In hoofdstuk 9 hebben we aan de hand van een t-test het verschil tussen twee gemiddelden onderzocht. Met een ANOVA – Analysis of Variance of variantieanalyse – gaan we na of er een verschil is tussen drie of meer gemiddelden. Alhoewel de ANOVA wat in onbruik is geraakt door de populariteit van de regressieanalyse, blijft het nuttig om de basisgedachte achter de ANOVA te begrijpen. Voor specifieke onderzoeksdesigns kan het ANOVA-model een elegante oplossing bieden. Belangrijker nog is dat de methode inzicht biedt in de verschillende vormen van variabiliteit in de data, wat een fundamenteel aspect is van de statistische data analyse. Zoals de naam het al prijsgeeft, maakt de test gebruik van de variantie in de data om tot een conclusie te komen over verschillen in gemiddelden.
Om de methode te illustreren en toe te lichten gebruik ik een dataset met taaltestscores van de Bruin et al. (2017), de BEST-dataset. De dataset bevat taaltestscores voor drie talen: Spaans, Baskisch en Engels. We analyseren de LexTale-scores. LexTale meet woordenschatkennis aan de hand van een lexicale decisietaak (Lemhöfer and Broersma 2011). Bij een lexicale decisietaak krijgen participanten items gepresenteerd waarbij ze moeten aanduiden of het een bestaand of onbestaand woord is. De test werd oorspronkelijk ontwikkeld als woordenschattest voor L2-Engels, maar ondertussen bestaan er ook varianten van de test voor andere talen. De test heeft een score tussen \(0\) en \(100\).
11.1 Data: BEST
We openen de dataset, selecteren de LexTale-variabelen, transformeren de dataset naar het lange dataformaat, en passen de namen van de variabelen aan.
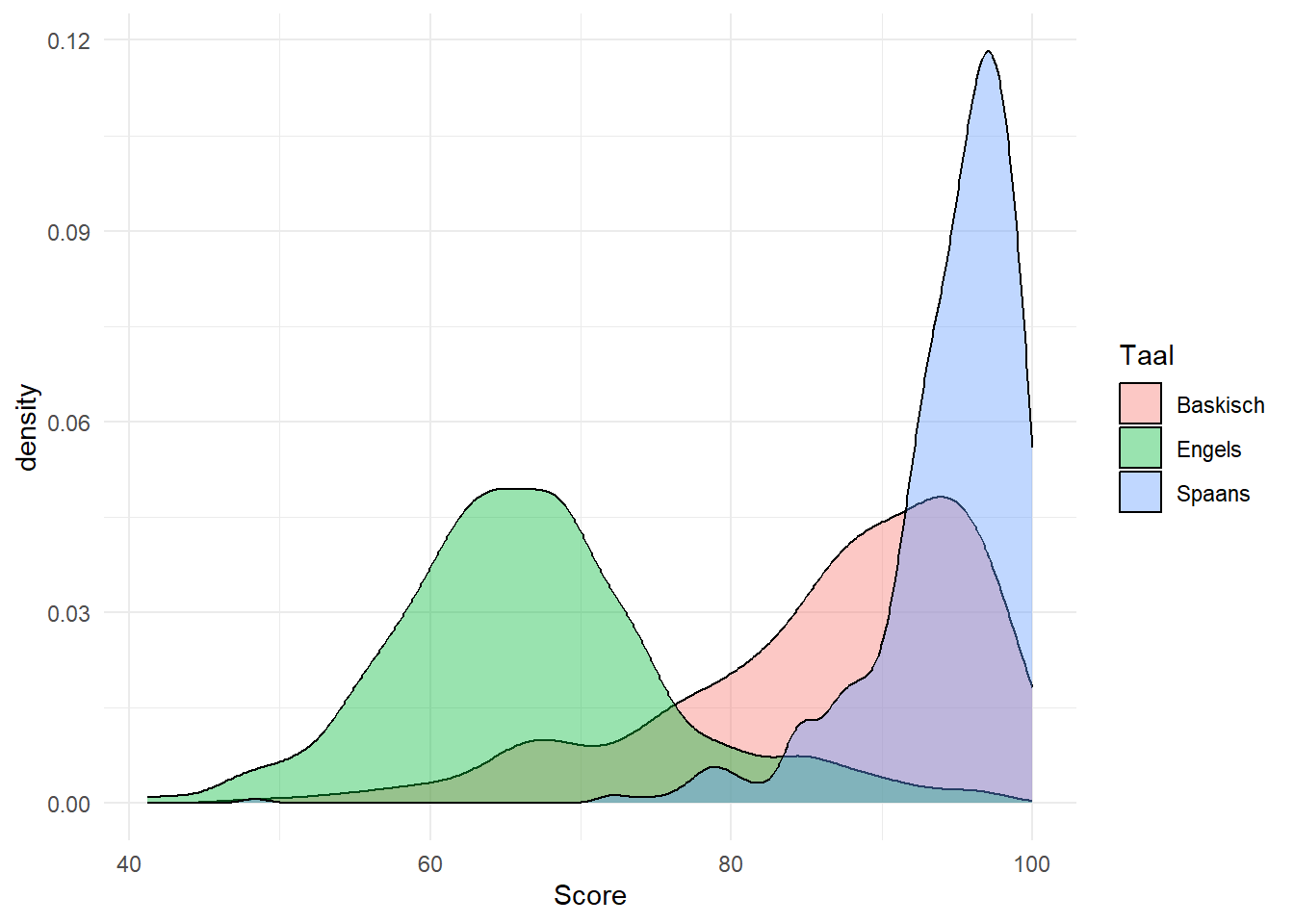
We visualiseren de data in Figure 11.1 aan de hand van drie overlappende densiteitscurves.
ggplot(Lex, aes(x=Score, fill = Taal)) +geom_density(position ="identity", alpha =0.4) +theme_minimal()
Figure 11.1: De verdeling van de LexTALEscores voor Spaans, Baskisch en Engels
Er tekent zich een duidelijke tendens af waarbij de scores voor Spaans en Baskisch hoger liggen dan die voor Engels. De samenvattende statistieken geven een nauwkeuriger inschatting van de verschillen tussen de drie talen.
# A tibble: 3 × 6
Taal Min Median Mean Var Max
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Baskisch 48 89 86.3 104. 100
2 Engels 41.2 66.2 66.8 85.2 97.5
3 Spaans 48.3 95.8 94.4 26.1 100
Er zijn overduidelijke verschillen in de Lextalescores voor de drie talen. De gemiddelde scores voor Spaans en Baskisch zijn met respectievelijk \(94\) en \(87\) hoger dan de score voor Engels \(68\). De verklaring ligt voor de hand: de meeste participanten zijn tweetalig Spaans-Baskisch die Engels als vreemde taal hebben. Merk ook het verschil in varianties, die voor Spaans (\(27\)) ligt veel lager dan die voor Baskisch (\(93\)) en Engels (\(86\)). Een dergelijk verschil compromitteert de ANOVA-test omdat net zoals bij de t-test, homoscedasticiteit ook voor de ANOVA een assumptie is. We negeren dit even “pour le besoin de la cause”, namelijk het begrijpen, kunnen uitvoeren en beoordelen van de ANOVA.
11.2 ANOVA
Met een variantie-analyse testen we de volgende hypotheses:
\(H_A\): \(\mu_1=\mu_2=...=\mu_i\)
\(H_0\): ten minste twee \(\mu_i\) zijn verschillend van elkaar (ze hoeven dus niet allemaal verschillend te zijn om de nulhypothese te verwerpen).
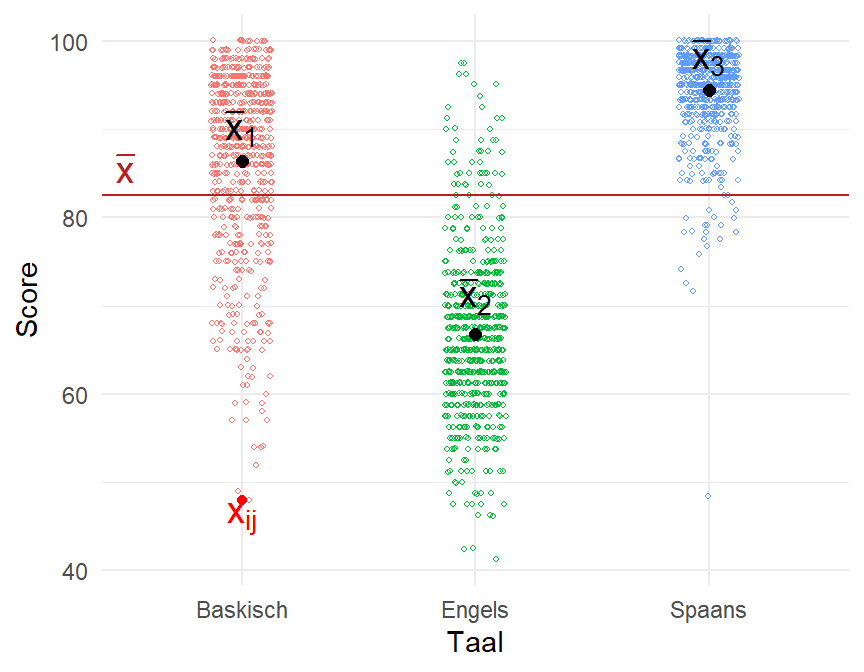
Om deze hypotheses te testen worden de varianties vergeleken. Het is daarom het nuttig om de data voor te stellen aan de hand van een puntenwolk zoals in Figure 11.2. Ik voeg onmiddellijk ook het algemene gemiddelde toe als een horizontale lijn en de groepsgemiddeldes als grotere bollen, zodat we de drie verschillende vormen van variantie in de data kunnen aanduiden.
ggplot(Lex, aes(x=Taal, y=Score, color = Taal)) +geom_jitter(width =0.13, shape =21, size=0.8, show.legend =FALSE) +geom_hline(yintercept=mean(Lex$Score),color ="firebrick") +stat_summary(fun=mean, geom='point', col="black", shape=20, size=3) +annotate('text', x =0.5, y =mean(Lex$Score)+3, label ="bar(x)", col ="firebrick", size =5, parse=T) +annotate('text', x =1, y =90, label ="bar(x)[1]", col ="black", size =5, parse=T) +annotate('text', x =2, y =71, label ="bar(x)[2]", col ="black", size =5, parse=T) +annotate('text', x =3, y =98, label ="bar(x)[3]", col ="black", size =5, parse=T) +geom_point(aes(x=1,y=48),colour="red") +annotate('text', x =1, y =46, label ="x[ij]", col ="red", size =5, parse=T) +theme_minimal()
Figure 11.2: De verdeling van de LexTALEscores voor Spaans, Baskisch en Engels.
Het ANOVA-model is gebaseerd op drie soorten varianties; de variantie van:
alle datapunten vs. het algemene gemiddelde: \(x_{ij}\) vs. \(\bar{X}\)
de drie groepsgemiddeldes vs. het algemene gemiddelde: \(\bar{X}_i\) vs. \(\bar{X}\)
alle datapunten vs. het eigen groepsgemiddelde: \(x_{ij}\) vs. \(\bar{X}_i\)
We zagen in hoofdstuk 6 dat een variantie gelijk is aan een gemiddelde kwadratensom. Welnu, wat zijn de drie kwadratensommen voor deze drie variantie?
SSTO: de totale kwadratensom (“Sum of Squares of Total”):
\[
SSTO=\sum(x_{ij}-\bar{X})²
\]
Waarbij \(x_{ij}\) verwijst naar de observatie \(j\) uit groep \(i\), dus \(x_{2,3}\) is observatie \(3\) uit groep \(2\).
SSTR: de kwadratensom van de behandelingen (“Sum of Squares of Treatment”)
\[
SSTR=\sum(\bar{X_i}-\bar{X})
\]
SSE: de kwadratensom van de errors (“Sum of Squares of Errors”)
\[
SSE=\sum(x_{ij}-\bar{X_i})
\]
In hoofdstuk 7 hebben we gezien hoe elk punt op een normale verdeling gemodelleerd kan worden als \(x_i=\mu+e_i\). Welnu, we kunnen dit uitbreiden met meerdere gemiddeldes en kunnen het datamodel als volgt schrijven:
De totale kwadratensom in de data is gelijk aan de som van de kwadratensom tussen de groepen (TR = “treatments” of “behandelingen”) en de kwadratensom binnen elke groep, of de residuelen (E = “errors”, de afwijkingen ten opzichte van de groepsgemiddelden).
De gemiddelde kwadratensommen bekomen we door de kwadratensommen te delen door hun respectievelijke vrijheidsgraden. De MSTO is niets anders dan de totale variantie. Voor de statistische test hebben we enkel de MSTR en de MSE nodig.
MSTR
\[
MSTR=\frac{SSTR}{r-1}
\]
met \(r=\) aantal groepen.
MSE
\[
MSE=\frac{SSE}{n-r}
\]
met \(n=\) aantal observaties en \(r=\) aantal groepen.
MSTR en MSE zijn respectievelijk schatters voor de variantie tussen de groepen en de variantie binnen de groepen.
Vervolgens definiëren we de teststatistiek\(F^*\) als:
\[
F^*=\frac{MSTR}{MSE}\sim f_{r-1,n-r}
\]
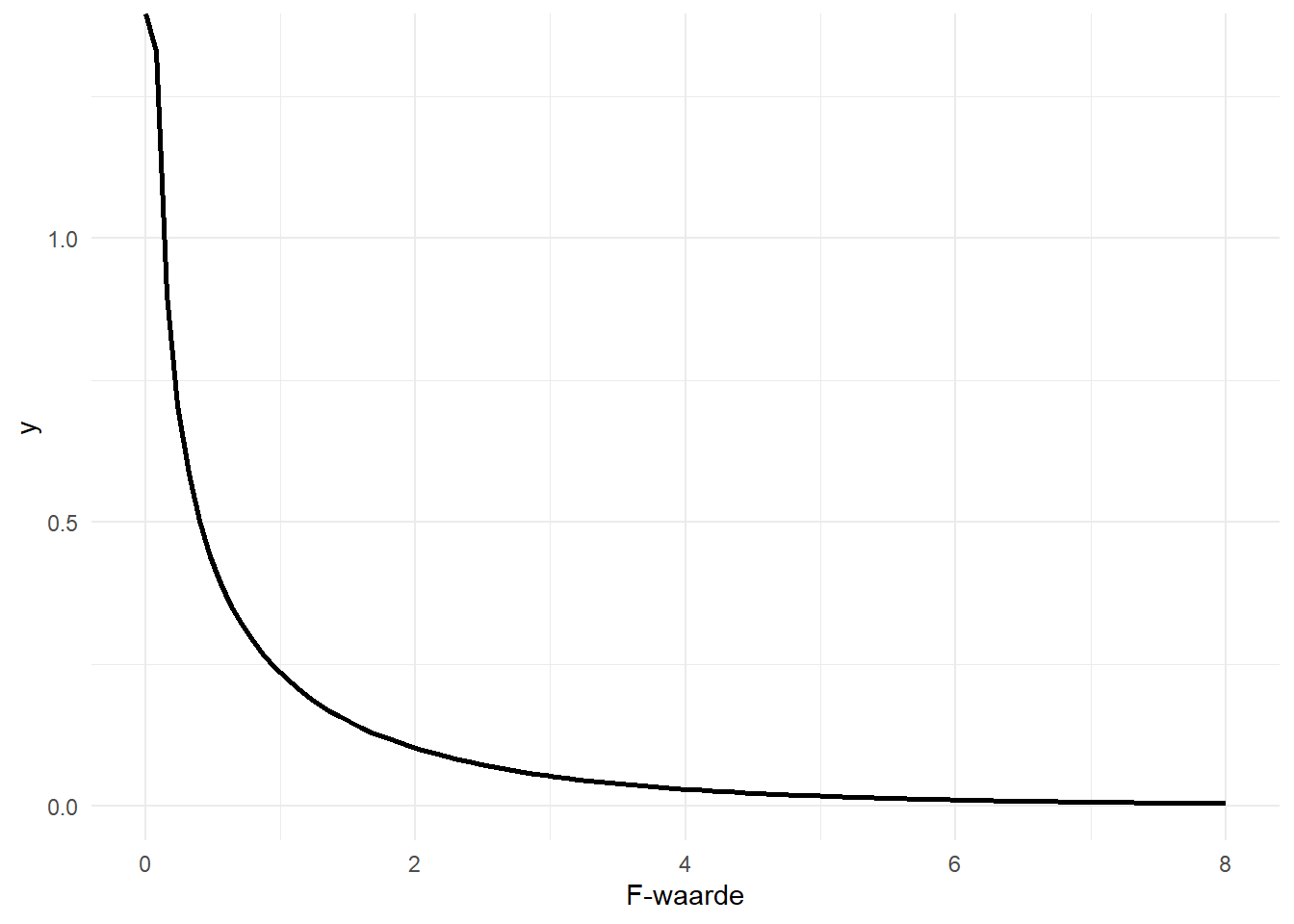
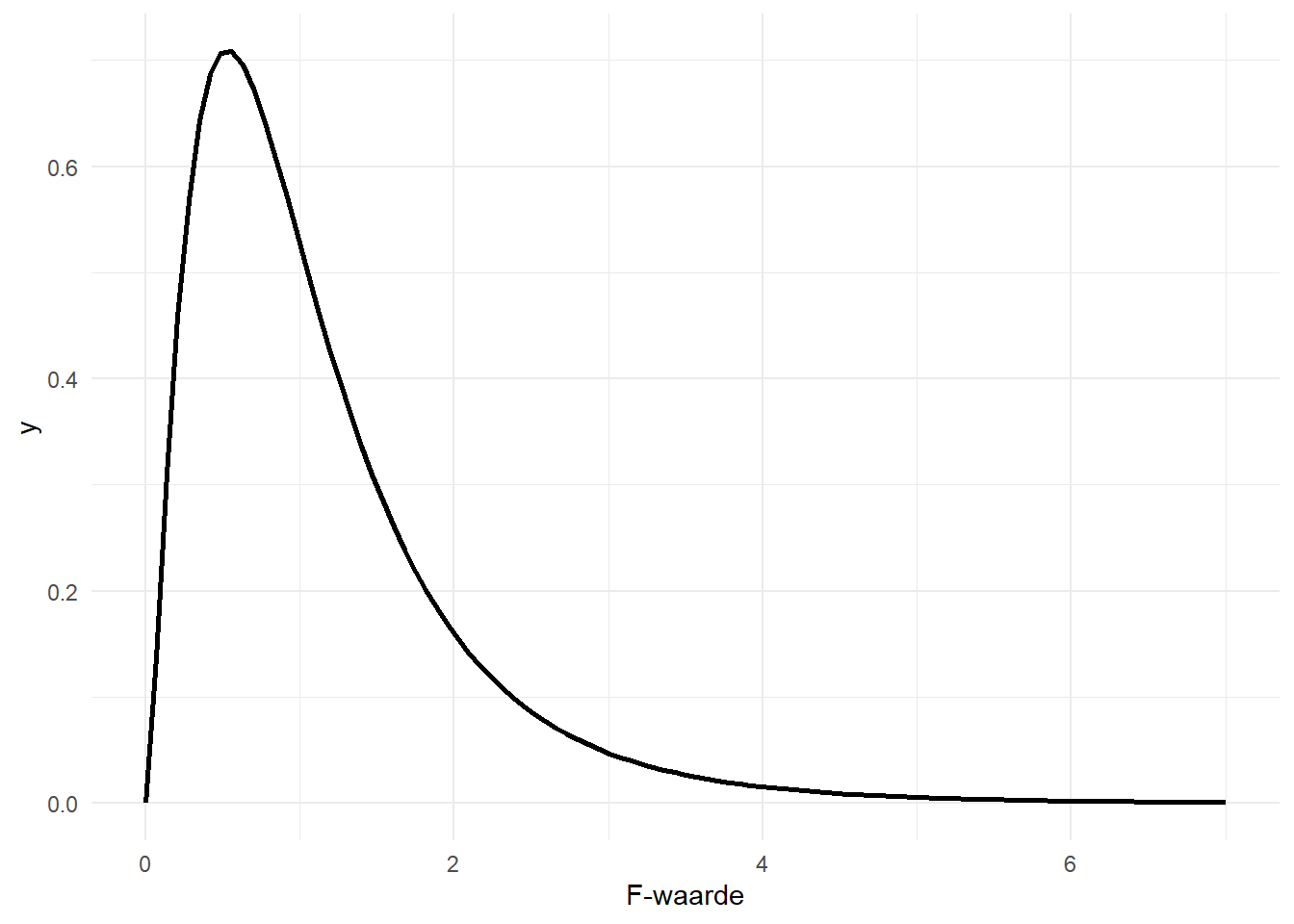
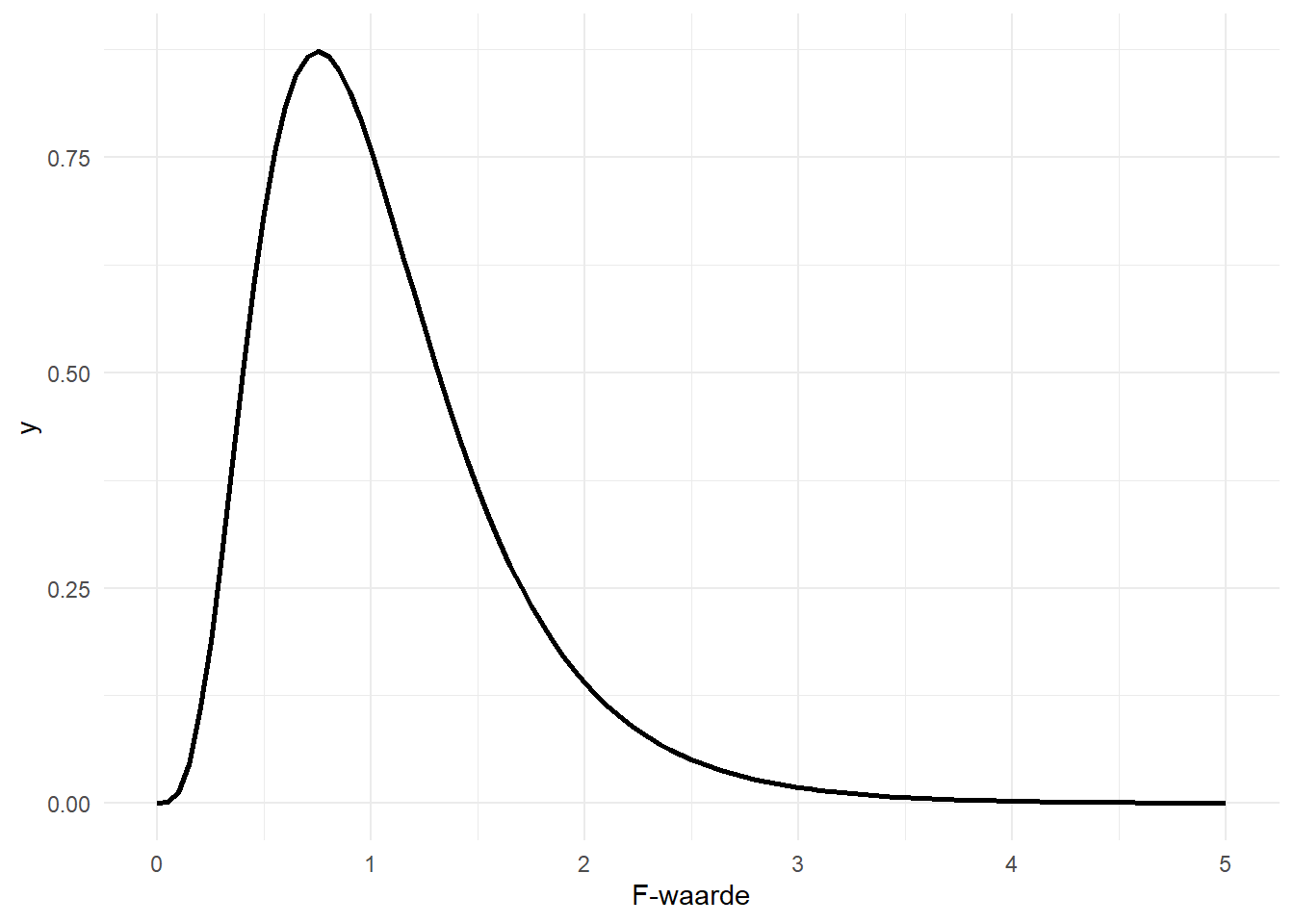
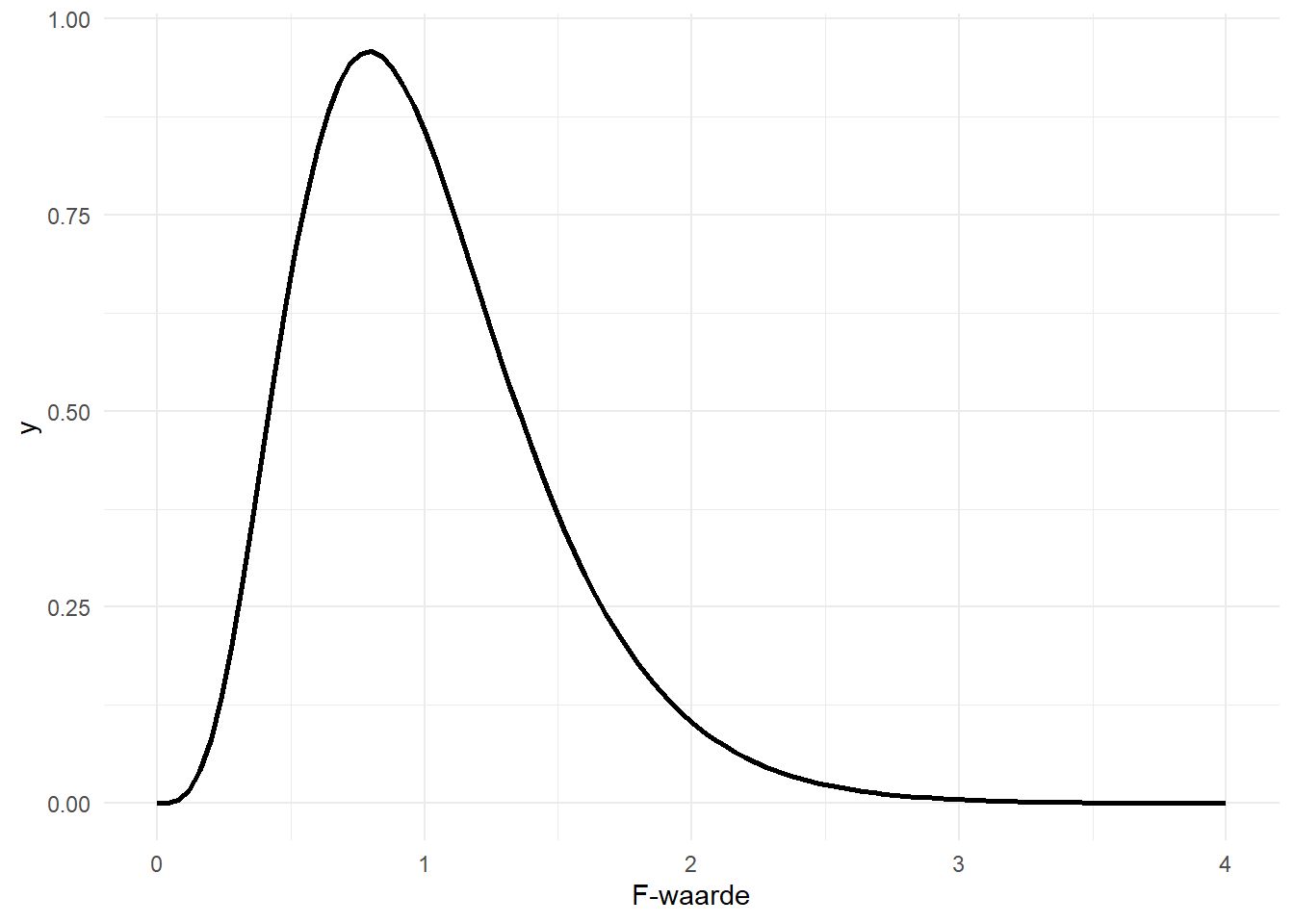
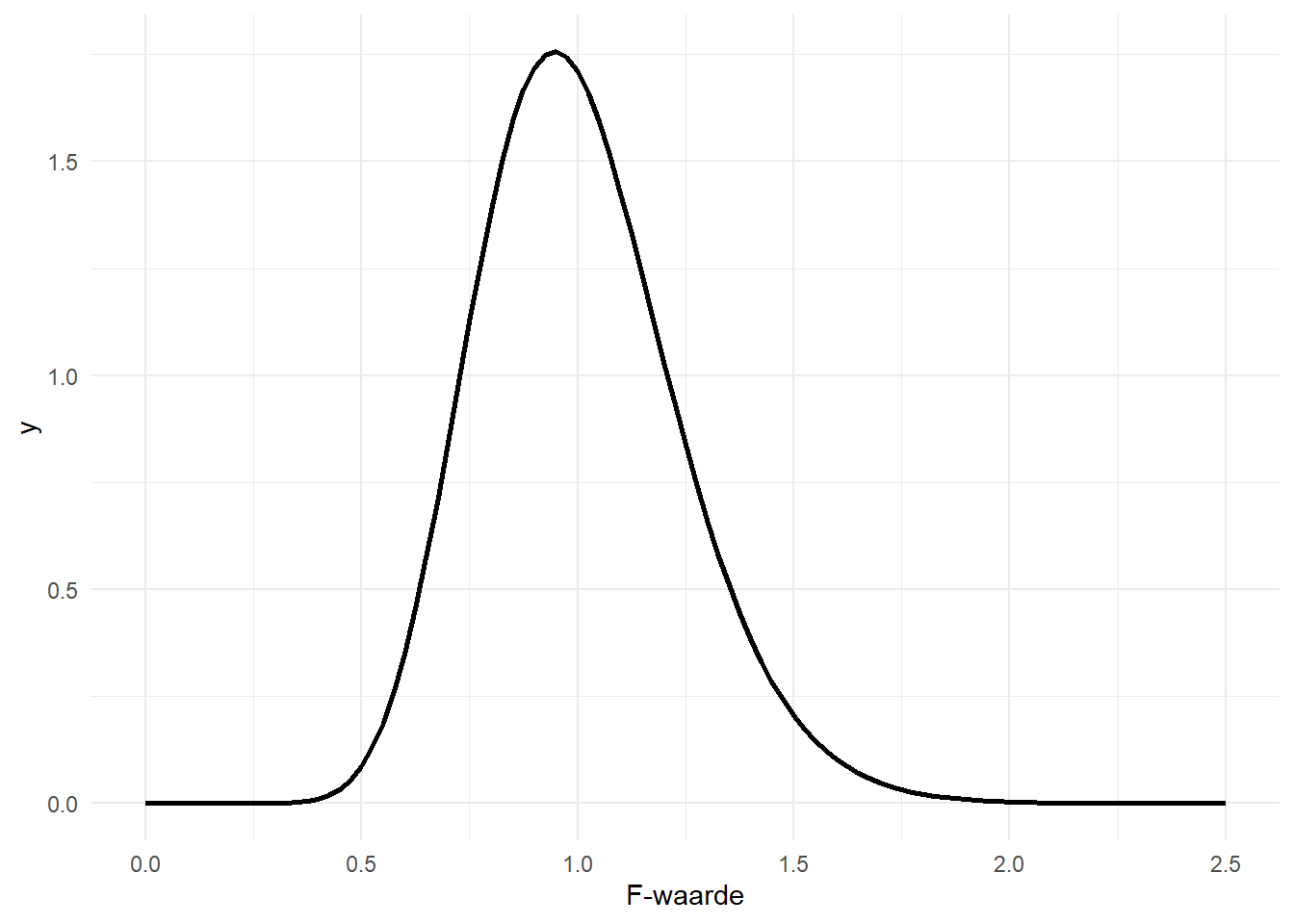
\(f_{r-1,n-r}\) verwijst naar de f-verdeling met twee vrijheidsgraden: \(r-1\) in de teller (Eng. “numerator”) en \(n-r\) in de noemer (Eng. “denominator”). \(F^*\) verwijst naar de teststatistiek, \(f\) naar de f-verdeling. De teststatistiek is dus opnieuw een waarde op een verdeling. Om na te gaan of deze waarde speciaal, of “significant” is, bekijken we de proportie waarden die gelijk is of nog groter dan de geobserveerde teststatistiek, met ander woorden, de P-waarde. Eerst geef ik in Figure 11.3 enkele voorbeelden van f-verdelingen met verschillende vrijheidsgraden.
De f-waarden zijn steeds positief omdat het een quotiënt van kwadraten betreft.
We voeren de f-test uit en interpreteren het resultaat. We fitten het model met de aov() functie en vragen vervolgens de summary().
mdl <-aov(Score ~ Taal, data = Lex)summary(mdl)
Df Sum Sq Mean Sq F value Pr(>F)
Taal 2 262534 131267 1829 <2e-16 ***
Residuals 1947 139739 72
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
De resultaten worden weergegeven in een “anovatabel”. De kolom “Pr(>F)” is de P-waarde en die is hier heel sterk significant (P-waarde < 0.0001). De teststatistiek wordt weergegeven als “F value” en is \(1829\), een waarde op de horizontale as van een f-verdeling met \(2\) en \(1947\) vrijheidsgraden (zie kolom “Df”). In de tabel krijgen we ook de kwadratensommen (“Sum Sq”) en de gemiddelde kwadratensommen (“Mean Sq”). De teststatistiek is gelijk aan het quotiënt van de gemiddelde kwadratensommen: \(\frac{131267}{72}=1829\). “Taal” verwijst naar de groepen (of “treatments”) en “Residuals” verwijst naar de “residuelen”.
Wat is de kritische waarde \(c\) voor een \(5\%\) significantieniveau op een f-verdeling met \(2\) en \(1947\) vrijheidsgraden?
qf(p =0.05, df1 =2, df2 =1947, lower.tail =FALSE)
[1] 3.000346
De teststatistiek van \(1829\) is veel groter en de geassocieerde P-waarde is dan ook navenant extreem klein. Op basis van de ANOVA-test beslissen we om de nulhypothese te verwerpen en de alternatieve hypothese te aanvaarden dat er ten minste twee gemiddelden verschillend zijn van elkaar.
11.3 Assumpties
De ANOVA is een parametrische test, wat impliceert dat er aan een aantal voorwaarden moet voldaan zijn opdat de verdeling van de teststatistiek inderdaad gelijk is aan wat we verwachten. Er zijn drie assumpties, die we op dezelfde manier kunnen nagaan als bij de t-test.
Onafhankelijke observaties. Is elk datapunt onafhankelijk van de andere tot stand gekomen? Hier moeten we weten hoe de data gecreëerd werden. Werden dezelfde participanten getest op verschillende tijdstippen? Indien dit het geval is dan is de assumptie al geschonden. We dienen dan een andere modellering te gebruiken die wel rekening houdt met deze clustering in de data. (een regressiemodel met een random factor is tegenwoordig een standaardoplossing).
Normaliteit van de data. Komen de drie groepen uit een normale verdeling? Een blik op Figure 11.1 wijst er al op dat normaliteit hier geschonden is.
Gelijke variantie (homoscedasticiteit). Zijn de varianties tussen de groepen gelijk? Figure 11.1 wijst overduidelijk op het tegendeel.
We kunnen de laatste twee assumpties op allerlei manieren testen. Laten we even de gemakkelijkheidsoptie kiezen via het easystats package.
check_normality(mdl)
Warning: Non-normality of residuals detected (p < .001).
check_homogeneity(mdl)
Warning: Variances differ between groups (Bartlett Test, p = 0.000).
We kunnen de nulhypotheses van normaliteit en homoscedasticiteit verwerpen en concluderen dat de assumpties om een ANOVA-test uit te voeren geschonden zijn. De eerdere ANOVA-resultaten moeten we dus met een flinke korrel zout nemen, of, nog beter, opteren voor een andere test. Een niet-parametrisch alternatief voor een ANOVA is de Kruskal-Wallis test.
11.4 De paarsgewijze verschillen
De alternatieve hypothese is bij een ANOVA nogal banaal; er zijn ten minste twee gemiddeldes die verschillend zijn van elkaar. Goed, maar welke gemiddeldes zijn er dan verschillend? Om dit na te gaan voeren we een posthocanalyse uit van de paarsgewijze verschillen.
Nu zou je kunnen opwerpen dat we dat eerder al hadden kunnen doen door de verschillen tussen de gemiddelden te testen aan de hand van een reeks t-testen. Dit is geen goed idee, vanwege de “familywise error rate”. Volg even de volgende redenering.
We testen doorgaans op een significantieniveau van \(5\%\). Dit klopt wanneer we één test uitvoeren. Maar wanneer meerdere tests worden uitgevoerd dan loopt dit significantieniveau op, en stijgt de kans dat we ten onrechte te nulhypothese verwerpen en dus een Type 2 fout maken. Om dit te vermijden, voeren we eerst een algemene (omnibus) test uit, en pas wanneer die test significant is, gaan we verder met een posthocanalyse van de paarsgewijze verschillen. Bij het testen van de paarsgewijze verschillen moet het significantieniveau daarenboven worden aangepast naar een iets lager niveau. Daarvoor zijn verschillende oplossingen bedacht. De eenvoudigste is de oplossing van Bonferroni: deel het significantieniveau door het aantal testen. Voer je vijf testen uit dan deel je \(5\%\) door \(5\) en dan bekomt je een significantieniveau van \(1\%\). Het nadeel van Bonferroni is dat de test dan te conservatief of te streng wordt en dat je te vaak beslist om de nulhypothese te behouden wanneer die eigenlijk verkeerd is (Type 1 fout). Een gulden middenweg werd gevonden door Tuckey die een Honestly Significant Difference ontwikkeld heeft. Zonder verder in de technische details te treden, voeren we Tuckey’s HSD uit:
TukeyHSD(mdl)
Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = Score ~ Taal, data = Lex)
$Taal
diff lwr upr p adj
Engels-Baskisch -19.597692 -20.699913 -18.49547 0
Spaans-Baskisch 8.027969 6.925749 9.13019 0
Spaans-Engels 27.625662 26.523441 28.72788 0
We zien dat alle paarsgewijze verschillen significant zijn (cf. “p adj”). We krijgen een overzicht van de verschillen tussen de gemiddeldes (“diff”) alsook voor elk verschil een \(95\%\) betrouwbaarheidsinterval, waaruit we afleiden dat het grootste verschil tussen Spaans en Engels te vinden is, met \(27.6\) punten en een \(95\%\) BI van \(26.5\) tot \(28.7\).
11.5 Samenvatting en vooruitblik
Met de ANOVA hebben we het verschil tussen drie of meer gemiddelden geëvalueerd. Alhoewel de ANOVA wat in onbruik is geraakt in het voordeel van de regressieanalyse, heeft het model wel enkele interessante aspecten die ook belangrijk zijn bij de regressieanalyse. Met name het opdelen van de variabiliteit van de data in twee onderdelen – de variabiliteit die geassocieerd is met de behandelingen (het structurele deel van het model) en de rest van de variabiliteit die overblijft (het random deel van de errors) –, is één van de kerngedachten in de regressieanalyse en eigenlijk de statistische modellering in het algemeen. In het volgende hoofdstuk maken we kennis met het regressiemodel. Alle testen die we tot nu toe gedaan hebben voor de continue data (de t-testen en de ANOVA), kunnen we in een regressiemodel gieten. We beginnen echter met het enkelvoudig lineair regressiemodel: het lineair verband tussen een continue predictor op een continue uitkomst.
11.6 Terminologie
ANOVA
Variantie-analyse
Kwadratensom
Gemiddelde kwadratensom
SSTO / MSTO
SSTR / MSTR
SSE / MSE
Familywise Error Rate
Paarsgewijze vergelijkingen
F-verdeling
F-test
Functies:
aov()
summary()
TukeyHSD
11.7 Oefeningen
Leermethodes vergelijken. Jim Baumann en Leah Jones, Purdue College of Education, evalueerden het effect van drie verschillende leermethodes die de leesvaardigheden zouden verbeteren. De Reading dataset (reading.csv) is een van de datasets uit het populaire internationale handboek Introduction to the Practice of Statistics van Moore, McCabe, and Craig (2021). De onderzoekers verdeelden 66 leerlingen over drie groepen (drie gelijke, aselecte groepen): Basal is de traditionele methode, DRTA en Strategies zijn twee innovatieve methodes. Neem Post3 als uitkomstvariabele en ga na of de drie methodes een verschillend effect hebben op de gemiddelde leesvaardigheden van de leerlingen. Begin zoals steeds met een nauwkeurige beschrijving en visualisatie van de data.
De Influencer dataset.
Selecteer de sprekers met een Brabants accent.
Is er een verschil tussen de gemiddelde beoordeling voor de eigenschappen Eigentijds, Professioneel en Betrouwbaar? Je moet de data eerst transformeren van het wijde naar het lange dataformaat.
Bruin, Angela de, Manuel Carreiras, and Jon Andoni Duñabeitia. 2017. “The BEST Dataset of Language Proficiency.”Frontiers in Psychology 8 (April). https://doi.org/10.3389/fpsyg.2017.00522.
Lemhöfer, Kristin, and Mirjam Broersma. 2011. “Introducing LexTALE: A Quick and Valid Lexical Test for Advanced Learners of English.”Behavior Research Methods 44 (2): 325–43. https://doi.org/10.3758/s13428-011-0146-0.
Moore, David S., George P. McCabe, and Bruce A. Craig. 2021. Introduction to the Practice of Statistics. 10th ed. New York: WH Freeman.