Tot nu toe hebben we continue variabelen geanalyseerd. In de taalwetenschappen zijn dat doorgaans gegevens die tot stand komen op basis van psycholinguïstische experimenten (zoals eyetrackingdata, reactietijden), fonetische metingen (formanten en Voice Onset Time, vocaallengtes), of acceptabiliteitsmetingen. In veel takken van de taalwetenschap, zoals de corpuslinguïstiek, de sociolinguïstiek of de variatielinguïstiek zijn categorische data gebruikelijker.
In dit hoofdstuk leer je hoe je categorische variabelen kunt samenvatten en analyseren. We beginnen met de eenvoudigste categorische variabele met twee waarden en analyseren en vergelijken proporties. Vervolgens bekijken we de bivariate relatie tussen twee categorische variabelen, waarbij de kruistabel, de geclusterde staafdiagram en de chikwadraattoets uitvoerig besproken wordt. Daarna keren we terug naar de univariate analyse van multinomiale variabelen, dit zijn categorische variabelen met drie of meer categorieën. Via twee zogenaamde “goodness of fit” testen, gaan we na of een geobserveerd patroon afwijkt van een verwachte patroon. Ten slotte breiden we de analyse uit naar een multivariaat model aan de hand van classificatiebomen en een random forest. Vooraleer we van start gaan met binaire categorische variabelen, geef ik eerst nog een korte toelichting bij de manier waarop variabelen gemeten kunnen worden.
10.1 Meetschalen
In het eerste hoofdstuk hebben we een onderscheid gemaakt tussen kwantitatieve en categorische variabelen. In de praktijk is dit het belangrijkste onderscheid. Nu kun je op basis van de manier waarop variabelen gemeten worden, een verdere onderverdeling maken in vier categorieën.
Kwantitatief
Interval: meting zonder absoluut nulpunt (bvb.graden Celcius)
Ratio: meting met absoluut nulpunt (bvb. lichaamslengte)
Categorisch
Nominaal: categorieën zonder volgorde (bvb. geslacht)
Ordinaal: categorieën met volgorde (bvb. Likertschaal)
Voor de analyses die je in dit handboek aangereikt krijgt, zijn de verschillen tussen deze vier meetschalen grotendeels verwaarloosbaar. Het verschil tussen nominaal en ordinaal is enkel relevant voor geavanceerde analyses. Ordinale schalen worden in de praktijk vaak als een kwantitatieve variabele geanalyseerd. De geordende categorieën van een Likertschaal worden dan geïnterpreteerd en behandeld als naar numerieke waarden, waarvoor numerieke samenvattingen gemaakt worden (bvb. gemiddelde). Strikt genomen is dit niet helemaal correct, maar in de praktijk moet men soms roeien met de riemen die men heeft.
10.2 Proporties
Eerst een terminologische verduidelijking. Een fractie verwijst naar een deel van een geheel, zoals bvb. \(200\) op een totaal van \(350\). Een proportie is een fractie uitgedrukt als een getal tussen 0 en 1, of het quotiënt van het deel en het geheel uitgedrukt als decimaal getal. Een percentage is een proportie maal 100, of een transformatie van het quotiënt met \(100\) als noemer.
10.2.0.1 Voorbeeld
Naar schatting \(15\%\) van de volwassenen in Vlaanderen heeft moeite met lezen en schrijven.1 Is \(15\%\) het correcte cijfer? Dat weten we niet. \(15\%\) is een schatter \(\hat{p}\) voor een ongekende populatieparameter \(\pi\). Ik gebruik hier \(\pi\) als symbool voor de populatieparameterm naar naar analogie met de populatieparameter \(\mu\). Vaak wordt ook \(p\) gebruikt voor de populatie (\(\hat{p}\) wordt steevast gebruikt voor de steekproefstatistiek).
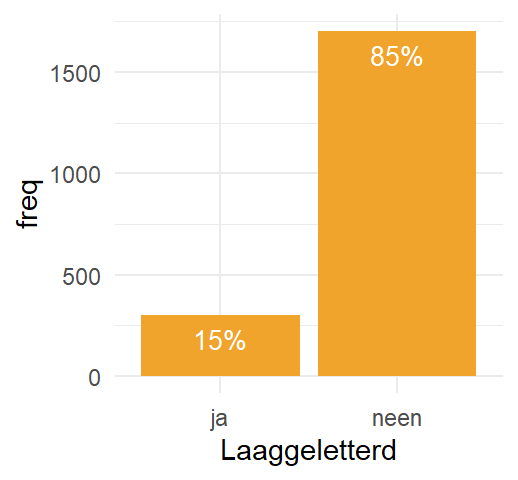
Laten we ervan uitgaan dat het onderzoek gebaseerd is op een enkelvoudige aselecte steekproef van \(N=2000\) participanten (in de praktijk vormt het nemen van een aselecte steekproef een grotere uitdaging dan het uitvoeren van een statische analyse). De proportie van zowel de populatie als de steekproef varieert tussen \(0\%\) (niemand is laaggeletterd) en \(100\%\) (iedereen is laaggeletterd). We hebben dus te maken met een stochastische variabele Laaggeletterdheid, met twee mogelijke waarden: iemand is laaggeletterd of is dat niet. We kunnen we deze binaire categorische variabele samenvatten als in Table 10.1:
Table 10.1: De frequentietabel voor Laaggeletterdheid op basis van een steekproef van 2000 participanten.
\(X_i\)
\(f_i\)
\(r_i\)
Ja
1700
\(85\%\)
Nee
300
\(15\%\)
\(X_i\) verwijst naar de twee mogelijke waarden van de categorische variabele. \(f_i\) staat voor de geobserveerde absolute frequentie voor elke waarde (hoeveel?), terwijl \(r_i\) de waarden omzet uitdrukt als relatieve frequenties.
We kunnen de verdeling van de variabele visualiseren aan de hand van een staafdiagram zoals in Figure 10.1.
Figure 10.1: Een staafdiagram voor de variabele laaggeletterdheid.
Voor de berekening van de schatter \(\hat{p}\) voor laaggeletterdheid delen we het aantal laaggeletterden \(X\) door het totale aantal participanten, zoals in Equation 10.1. Het aantal waarin we geïnteresseerd zijn, noemen we ook de successen (ongeacht of de uitkomst positief of negatief is). Voor een statistische analyse wordt de succeswaarde omgezet naar \(1\) (vandaar ook de term “succes”), terwijl een niet-succes de waarde \(0\) krijgt.
\[
\hat{p}=\frac{X}{n}
\tag{10.1}\]
Een veel voorkomende uitdaging bij het schatten van proporties is de correcte inschatting van de noemer. Dit is vooral moeilijk wanneer de totale populatie niet gekend is. We gaan hier niet verder in op deze uitdagende kwestie. Zie (Roy, Acharya, and Roy 2016) voor meer informatie.
10.3 Intermezzo: Procent vs. Procentpunt
Opgepast met de vergelijking van veranderingen die uitgedrukt worden als percentages!
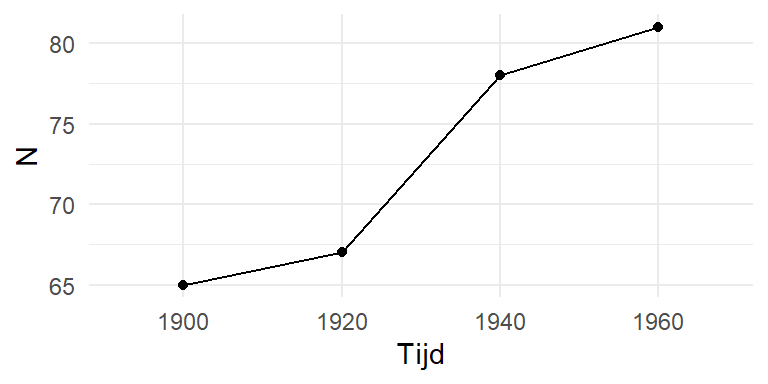
Stel dat we observaties hebben voor vier tijdstippen, zoals in Table 10.2:
Table 10.2: Observaties voor vier tijdstippen
1900
1920
1940
1960
65
67
78
81
We kunnen de verandering tussen de observaties visueel voorstellen aan de hand van een trendlijn zoals in Figure 10.2.
Figure 10.2: Verandering in geobserveerde aantallen doorheen de tijd
De verandering kan uitgedrukt worden als een percentage. Table 10.3 toont de stijging tussen elk tijdsmoment in absolute waarden en in procenten:
Table 10.3: De procentuele toename tussen elke periode.
1900-1920
1920-1940
1940-1960
\(2\)
\(11\)
\(3\)
\(3\%\)
\(16\%\)
\(4\%\)
We berekenen de procenten als volgt:
(67-65)/65*100
[1] 3.076923
(78-67)/67*100
[1] 16.41791
(81-78)/78*100
[1] 3.846154
Om de verandering tussen het aantal observaties te vergelijken kunnen we de verandering in procenten uitdrukken. Maar om de procenten onderling te vergelijken, wordt de term procentpunt gebruikt: De stijging van \(3\%\) naar \(16\%\) is gelijk aan \(13\) procentpunten – 13pp of \(13\%\)-punt. Procentpunt is een absolute waarde voor het verschil tussen procenten:
\[
b\%-a\%=(b-a)pp
\tag{10.2}\]
In procent uitgedrukt, bedraagt de stijging \(433\%\) 433. Een honderste van een procentpunt wordt een basispunt genoemd. In de omgangstaal wordt vaak procent gebruikt wanneer het eigenlijk procentpunt betreft.
10.4 De steekproevenverdeling van de proportie
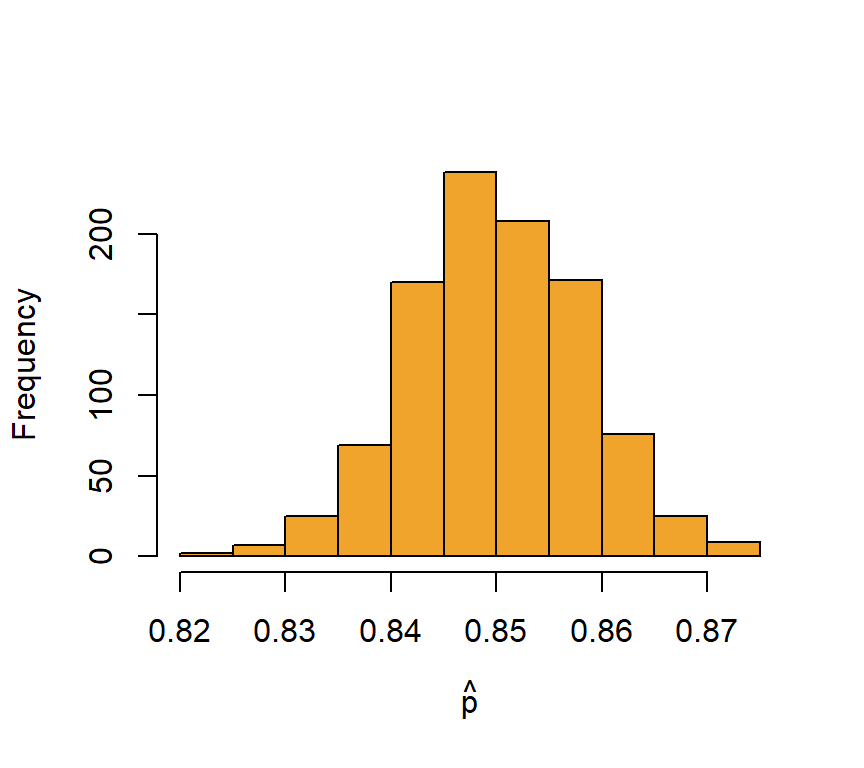
Stel dat we het onderzoek naar laaggeletterdheid 1000 keer zouden herhalen. Dan zouden we een andere schatting bekomen van de proportie laaggeletterdheid. Met andere woorden, op basis van meerdere steekproeven zouden we andere schatters $\hat{p_i}$ bekomen voor de populatieparameter \(\pi\). We simuleren dit in R.
de populatieparameter \(\pi\) van de verdeling waaruit we samplen
4
om opnieuw een percentage te bekomen
We visualiseren de steekproevenverdeling van de proportie in Figure 10.3 en we krijgen opnieuw een schitterend resultaat te zien.
hist(laag_samples_2000, xlab =expression(hat(p)),col ="#F1A42B", main ="")
Figure 10.3: De steekproevenverdeling van de proportie
De verdeling is bij benadering normaal! Bovendien is het gemiddelde van de steekproevenverdeling gelijk aan de populatieproportie.
We weten dat een normale verdeling gekenmerkt wordt door twee parameters: het gemiddelde en de standaardafwijking (die we in deze context de standard error noemen). Voor grote steekproeven (\(n > 20\)) geldt:
In een corpus vond men \(X = 216\) woorden t-deletie in auslaut op een totaal van \(N = 560\) woorden met t in auslaut. We hebben dus als schatter \(\hat{p}\) voor een populatieparameter \(\pi\):
De schatter \(\hat{p}\) is een zuivere schatter (“unbiased estimator”) voor de populatieparameter \(\pi\). Aangezien \(n\) in de noemer staat, leiden grotere steekproeven noodzakelijkerwijze tot nauwkeuriger schattingen (indien de steekproef aselect tot stand kwam en dus representatief is!). De standaardafwijking voor de schatter \(\sigma_{\hat{p}}\) is dus ook de standard error (SE) van de steekproevenverdeling van de proportie.
Nu we weten dat de steekproevenverdeling van een proportie ongeveer normaal verdeeld is, kunnen we ook z-scores, cumulatieve proporties en betrouwbaarheidsintervallen berekenen.
Op basis van onze schatting gaan we uit van een normale verdeling met gemiddelde \(\mu=0.39\) en eens standaardafwijking \(\sigma=0.02\). Wat is dan de z-score van een proportie van \(42\%\)?
We verwachten dus met \(95\%\) betrouwbaarheid dat t-deletie tussen de \(35\%\) en de \(43\%\) van de woorden betreft. Een \(95\%\) BI volstaat meestal als statistisch besluit. Aangezien \(50\%\) buiten het \(95\%\) BI valt kunnen we bvb. besluiten dat t-deletie in minder dan \(50\%\) van de in aanmerking komende woorden voorkomt, al kunnen we dit laatste ook nagaan aan de hand van een statistische test.
10.5.0.1 Opmerking
Wanneer het BI gebruikt wordt voor statistische inferentie wordt het BI vaak aangepast omdat gebleken is dat het BI onbetrouwbaar kan zijn. De aanpassing bestaat erin om de steekproefgrootte \(N\) met vier te vergroten. Dan onstaat er een nieuwe schatter \(\tilde{p}\) en een aangepaste Standard Error voor deze schatter.
\[
\tilde{p}= \frac{X+2}{N+4}
\]
Het BI wordt dan geschat op basis van Equation 10.4.
We bekijken twee significantietoetsen voor proporties:
Het verschil tussen een proportie en een verwachte proportie (z-toets voor één proportie)
Het verschil tussen twee proporties (z-toets voor twee proporties)
10.6.1 Z-toets voor een proportie
We formuleren de hypotheses:
\(H_0\): \(\pi=\pi_0\)
\(H_A\): \(\pi\neq\pi_0\) (of een eenzijdig alternatief)
We weten dat de steekproevenverdeling normaal verdeeld is. We gebruiken deze steekproevenverdeling om een teststatistiek \(Z\) te berekenen. Merk wel op dat we de verwachte populatieproportie \(\pi_0\) gebruiken om de SE te berekenen. Dit is anders dan in het BI waar we de steekproefproportie gebruiken.
Een expert verwacht dat de helft van alle woorden t-deletie vertonen. In onze steekproef van \(560\) woorden vonden we \(260\) observaties met t-deletie ofwel \(39\%\). Is het verschil met de verwachte \(50\%\) statistisch significant?
De p-waarde is duidelijk zeer klein. We beslissen om de nulhypothese te verwerpen en de alternatieve hypothese te aanvaarden dat de populatieproportie verschillend is van \(50\%\). Op basis van onze steekproef schatten we de werkelijke proportie op \(39\%\), en we hadden al een \(95\%\) BI geschat van \(35\%\) tot \(43\%\) (wat ons ook al een antwoord gaf op de vraag die we zonet getest hebben). In R gebruiken we de prop.test() functie.
prop.test(x =216, n =560, p =0.50)
1-sample proportions test with continuity correction
data: 216 out of 560, null probability 0.5
X-squared = 28.802, df = 1, p-value = 8.018e-08
alternative hypothesis: true p is not equal to 0.5
95 percent confidence interval:
0.3454379 0.4275823
sample estimates:
p
0.3857143
R maakt gebruik van een chi kwadraattoets, maar er kan aangetoond worden dat het resultaat van beide testen analoog is.
10.6.2 Z-toets voor twee proporties
We testen de hypotheses:
\(H_0\): \(\pi_1=\pi_2\)
\(H_A\): \(\pi_1\neq\pi_2\) (of een eenzijdig alternatief)
Men onderzocht het gebruik van de huig-r in twee sociale groepen. In groep 1 gebruikten \(43\) op \(60\) (\(72\%\)) participanten een huig-r, in groep 2 \(34\) op \(50\) (\(68\%\)).
We gebruiken onmiddellijk de prop.test() functie in R:
x is een vector voor het aantal successen in de groepen
2
n is een vector voor het aantal observaties in elke groep.
2-sample test for equality of proportions with continuity correction
data: c(43, 34) out of c(60, 50)
X-squared = 0.043651, df = 1, p-value = 0.8345
alternative hypothesis: two.sided
95 percent confidence interval:
-0.1540573 0.2273906
sample estimates:
prop 1 prop 2
0.7166667 0.6800000
Op basis van deze test (R gebruikt hier opnieuw de chikwadraattest, maar die is analoog) hebben we geen bewijs dat er een verschil is in het gebruik van de huig-r tussen de twee sociale groepen. Er is natuurlijk een verschil tussen de twee steekproeven, maar daarover gaat het niet; we gebruiken de steekproeven om een conclusie te trekken over de populatie(s).
10.7 Bivariate relatie tussen twee categorische variabelen
Grafmiller (2023) biedt ons een dataset over de Engelse possessiefalternantie. In het Engels kan een bezitsrelatie op twee manieren uitgedrukt worden: een spreker kan de s-genitief gebruiken, zoals in (1a), of een constructie met het voorzetsel of, zoals in (1b):
a. Kim’s book
b. the book of Kim
Dit is een typisch voorbeeld van een alternerende constructie, tegenwoordig een populair onderzoeksthema in de linguïstiek. Het doel van het onderzoek is om te achterhalen met welke variabelen de alternantie geassocieerd is. Het uitgangspunt is dat er geen sprake is van een “vrije” alternantie maar dat het gebruik van een van beide opties gemotiveerd is door meerdere variabelen, zowel linguïstische factoren (bepaalde kenmerken van de talige elementen in de constructie), als extra-linguistische factoren (bvb. eigenschappen van de spreker of de talige context). Een van de talige factoren waarvan men kan aannemen dat ze een effect heeft op het gebruik van de alternantie is de eindklank van de ‘bezitter’. Wanneer de bezitter eindigt op een sibilant, zoals in voorbeeld (2), dan lijkt het waarschijnlijker dat de spreker om fonotactische redenen de of-variant zal gebruiken, zoals in (2a), veeleer dan de s-variant in (2b).
a. the wheels of the bus
b. the bus’s wheels
Grafmiller (2023) bevat een corpussample van \(N=\) possessiefconstructies, waarbij ook het gebruik van een sibilant in auslaut geanooteerd werd. We laden de dataset, selecteren de variabelen die we nodig hebben, en bekijken de eerste zes rijen.
gen <-read.delim("written_genitive_tokens_Brown_Frown.txt", stringsAsFactors=TRUE) 1gen <- gen[ , c("Type",2"Final_Sibilant")]head(gen)
1
Type is de uitkomstvariabele
2
Final_sibilant is een binaire variabele, met “Y” als ja, de possessor eindigt op een sibilant en “N” als neen, de possessor eindigt niet op een sibilant.
Type Final_Sibilant
1 s N
2 of N
3 of N
4 s N
5 of Y
6 of N
Enkele samenvattende statistieken:
Voor Type:
table(gen$Type)
of s
3103 1995
round(prop.table(table(gen$Type)),2)*100
of s
61 39
De of-variant (\(61\%\)) komt vaker voor dan de s-variant (\(39\%)\).
De meeste ‘bezitters’ (\(78\%\)) eindigen niet op een sibilant.
10.7.1 De kruistabel
We vatten de relatie tussen de twee categorische variabelen samen aan de hand van een kruistabel. Omdat we Type als uitkomst beschouwen, geef ik die weer als een kolomvariabele. Ik verkies om de uitkomst als kolomvariabele weer te geven omdat we op die manier extra rijen kunnen toevoegen voor nog meer variabelen.
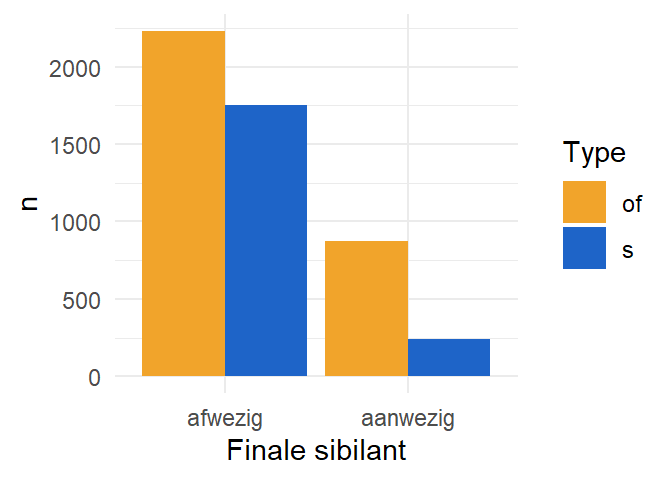
table(gen$Final_Sibilant, gen$Type)
of s
N 2229 1754
Y 874 241
Een kruistabel bevat heel wat informatie. Zo kunnen we verschillende proporties (of kansen) berekenen die op verschillende vragen een antwoord bieden. Ik gebruik hier de Crosstable() functie uit de gmodels package vanwege de handige manier op de verschillende proporties te printen.
Merk op dat de voorwaardelijke kans groter is dan de gezamelijke kans. Immers, wat is de kans op B “gegeven” A betekent dat we de kans op A al kennen. We beschikken dus over meer informatie dan bij de gezamelijke kans.
Tot daar deze korte uitweiding in de probabiliteitsleer. We gaan over naar de statistische data analyse van de kruistabel. We beginnen zoals steeds met een visualisatie.
10.7.2 De geclusterde staafdiagram
Een kruistabel stellen we voor als een geclusterde (of soms gestapelde) staafdiagram.
Figure 10.4 visualiseert de kruistabel aan de hand van ggplot2. Daarvoor moeten we de data eerst samenvatten aan de hand van een dataframe.
tt <- gen |>select(Final_Sibilant, Type) |>group_by(Final_Sibilant, Type) |>summarize(n =n())
`summarise()` has grouped output by 'Final_Sibilant'. You can override using
the `.groups` argument.
tt
# A tibble: 4 × 3
# Groups: Final_Sibilant [2]
Final_Sibilant Type n
<fct> <fct> <int>
1 N of 2229
2 N s 1754
3 Y of 874
4 Y s 241
Merk op hoe verschillend de output is in vergelijking met base-r:
table(gen$Final_Sibilant, gen$Type)
of s
N 2229 1754
Y 874 241
Het is echter zeer eenvoudig om ook via base-r een dataframe te maken.
Figure 10.4: Een geclusterde staafdiagram van Genitiefvorm in functie van de aanwezigheid van een sibilant.
Een heel duidelijke tendens is moeilijk af te leiden uit de figuur. Wanneer er een sibilant aanwezig is dan lijkt de of-variant iets frequenter voor te komen. Is dit meer dan toeval? Om dit te onderzoeken gebruiken we de chikwadraattoets.
10.8 De chikwadraattoets
Om de samenhang tussen twee categorische variabelen te testen, gebruiken we de chikwadraattoets. Maar wat betekent “samenhang”?
Met samenhang wordt een wiskundige afhankelijkheid bedoeld. Dit betekent dat we op basis van de ene variabele kunnen we de andere voorspellen met een grotere waarschijnlijkheid dan puur toeval. Vergelijk de twee tabellen in Table 10.4.
Table 10.4: Twee tabellen zonder en met perfecte samenhang
(a) Geen samenhang
A1
A2
B1
20
20
B2
20
20
(b) Perfecte samenhang
A1
A2
B1
40
0
B2
0
40
Op basis van Table 10.4 (b) kunnen we perfect voorspellen wat de categorie van variabele A zal zijn als we weten dat de categorie van B gelijk is aan B1. De relatie is hier perfect deterministisch: \(P(A|B)=100\%\). Op basis van Table 10.4 (a) kunnen we dat totaal niet voorspellen. Als we weten dat B gelijk is aan B2, dan kan de variabele A zowel A1 als A2 zijn; \(P(A|B)=50\%\). De twee variabelen zijn hier totaal onafhankelijk van elkaar. In de meeste datasets is de situatie niet zo puur. We hebben een statistische test nodig om na te gaan of er enige afhankelijkheid is tussen beide variabelen.
We formuleren eerst de nul- en de alternatieve hypothese:
\(H_0\): er is geen samenhang tussen de twee variabelen
\(H_A\): er is wel een samenhang tussen de twee variabelen
De teststatistiek voor de chi kwadraattoets wordt als volgt berekend:
\[
X^2=\sum \frac{(f_o-f_e)^2}{f_e}
\]
Waarbij \(f_o\) gelijk aan de geobserveerde aantal observaties in de cel, en \(f_e\) gelijk aan het verwachte aantal observaties in de cel. Er kan aangetoond worden dat de verwachte celfrequenties berekend kunnen worden als:
\[
f_{e11}=\frac{\text{rij 1 totaal}*\text{kolom 1 totaal}}{\text{totale aantal observaties}}
\]
We bekijken opnieuw de samenvattende tabel voor ons voorbeeld met de marginale totalen:
addmargins(table(gen$Final_Sibilant, gen$Type))
of s Sum
N 2229 1754 3983
Y 874 241 1115
Sum 3103 1995 5098
De verwachte waarde \(f_e\) voor \(cel_{11}\) is dus gelijk aan:
(3103*3983)/5098
[1] 2424.333
De verwachte waarde \(2424\) is hoger dan de geobserveerde waarde \(2229\) dit suggereert een negatieve associatie tussen “N” en “of”. We bekijken de verwachte waarde voor \(cel_{22}\):
(1995*1115)/5098
[1] 436.3329
Ook hier is de verwachte waarde \(436\) hoger dan de geobserveerde waarde \(241\), wat opnieuw een negatieve associatie suggereert. We zijn nog niet veel wijzer geworden. Laten we de statistische test uitvoeren in R. We gebruiken daarvoor de functie chisq.test() die we toepassen op een tabelobject.
Pearson's Chi-squared test with Yates' continuity correction
data: tt
X-squared = 182.94, df = 1, p-value < 2.2e-16
“X-squared” (\(= 182,94\), wat we gerust mogen afgeronden tot \(183\)) is de teststatistiek, “df” is het aantal vrijheidsgraden, en de P-waarde (“p-value”) is kleiner dan \(0.05\), op basis waarvan we beslissen om de nulhypothese te verwerpen en de alternatieve hypothese te aanvaarde. We hebben dus een (sterk) bewijs dat beide categorische variabelen afhankelijk zijn. Meer kunnen we op dit ogenblik niet beslissen.
In de teststatistiek worden de geoberveerde frequenties in de cellen vergeleken met de verwachte frequenties. We bekijken de verwachte frequenties:
tt # geobserveerde waardenchisq.test(tt)$exp # verwachte waarden
of s
N 2229 1754
Y 874 241
of s
N 2424.3329 1558.6671
Y 678.6671 436.3329
We berekenen de teststatistiek meet de hand (de eerste en laatste keer dat je dit ooit gaat doen).
We stellen opnieuw de vraag: hoe speciaal is deze waarde? Is de teststatistiek statistisch significant op het \(5\%\) significantieniveau?
Om dit te beoordelen moeten we nagaan wat de cumulatieve proportie is van waarden die hoger zijn dan \(183\). Daarvoor moeten we weten wat de verdeling is van de teststatistiek. Onder de nulhypothese volgt de teststatistiek voor de chikwadraat toets een chikwadraat verdeling met \((r-1)*(k-1)\) vrijheidsgraden, waarbij r verwijst naar het aantal rijen, en k naar het aantal kolommen. In ons geval is het aantal vrijheidsgraden gelijk aan \(1\), immers \((2-1)*(2-1)=1\).
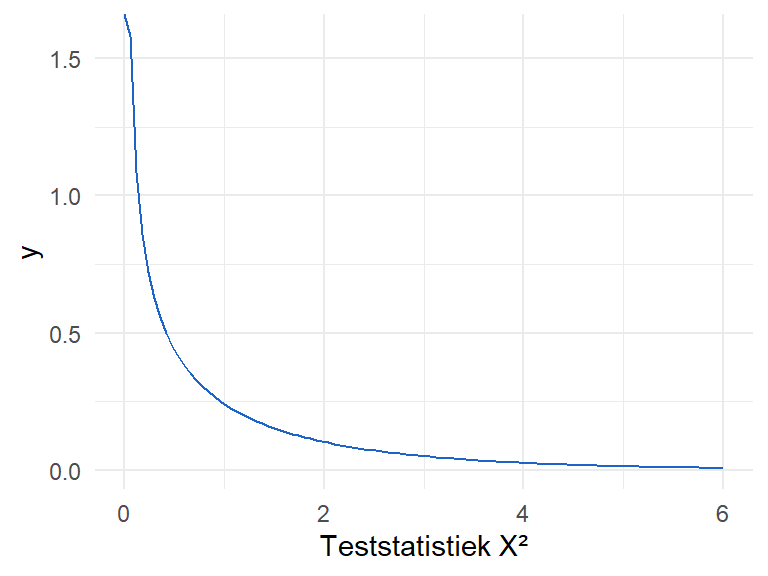
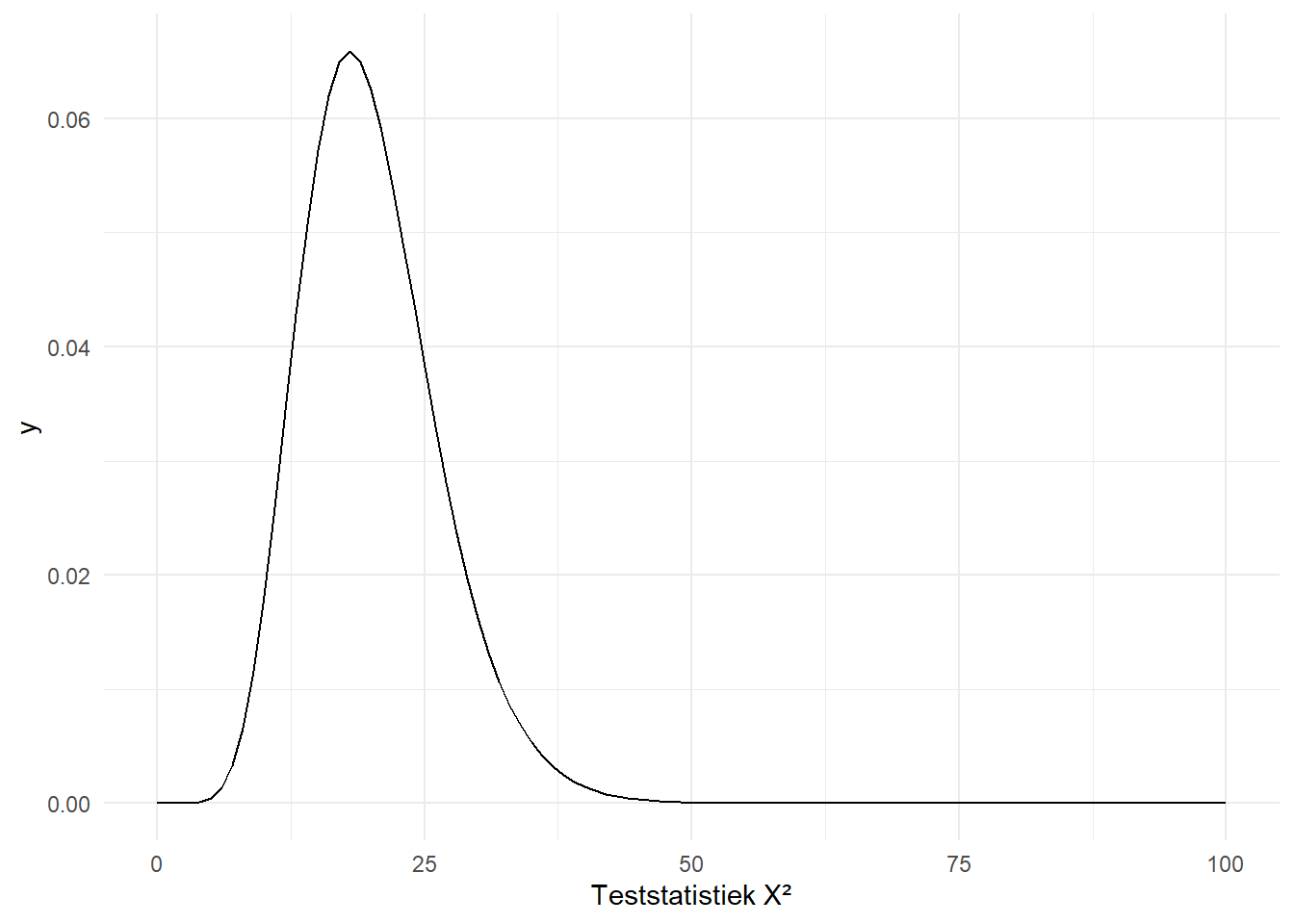
Figure 10.5 visualiseert de chikwadraatverdeling met 1 vrijheidsgraad.
Figure 10.5: Een chikwadraatverdeling met 1 vrijheidsgraad
De waarde van onze teststatistiek bedraagt \(183\), duidelijk een waarde op de X-as die heel ver naar rechts ligt en waarvoor de culumatieve proportie extreem klein is. Wat is de kritische waarde \(c\) voor een \(5\%\) significantieniveau op deze verdeling?
qchisq(p =0.05, df =1, lower.tail =FALSE)
[1] 3.841459
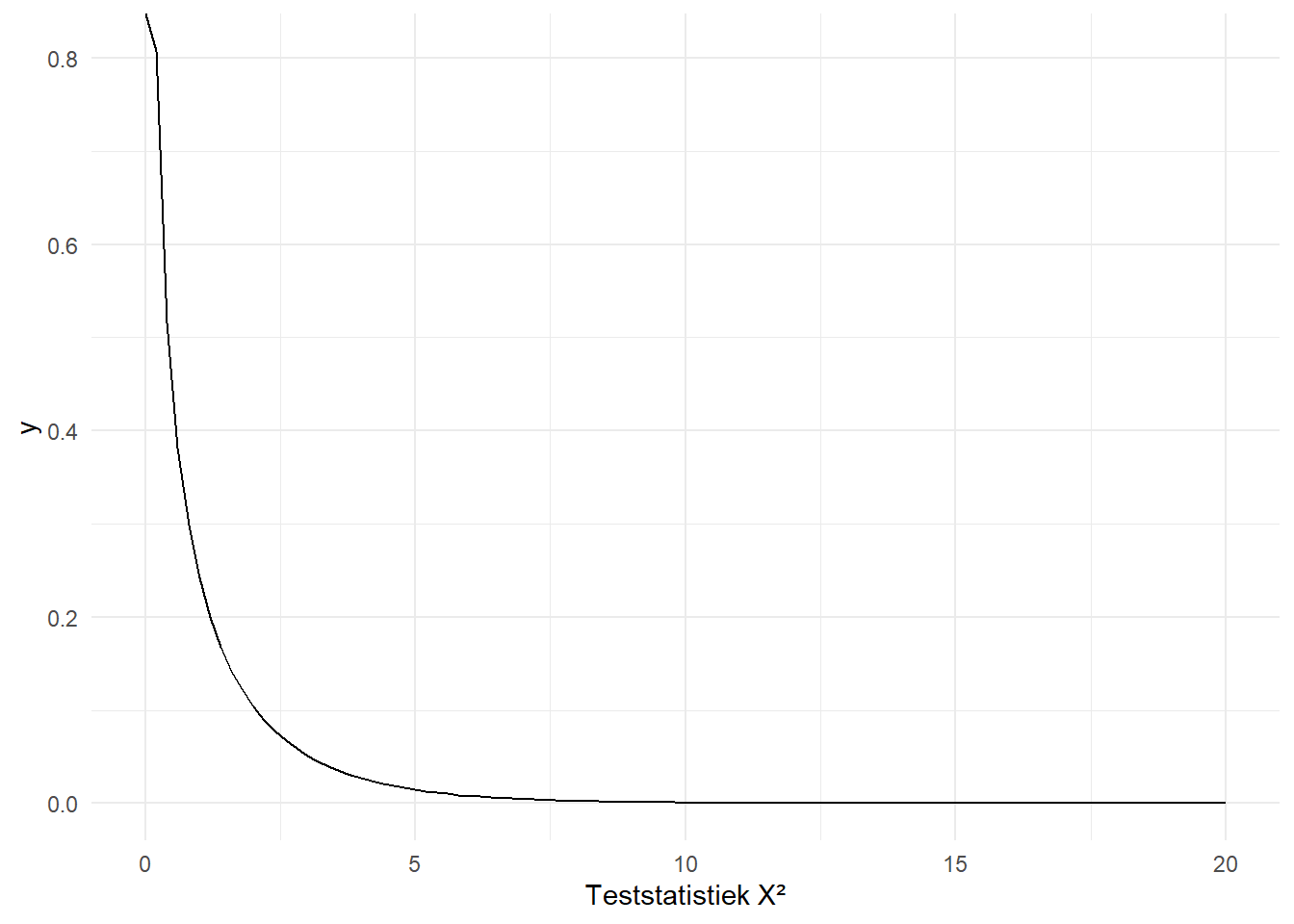
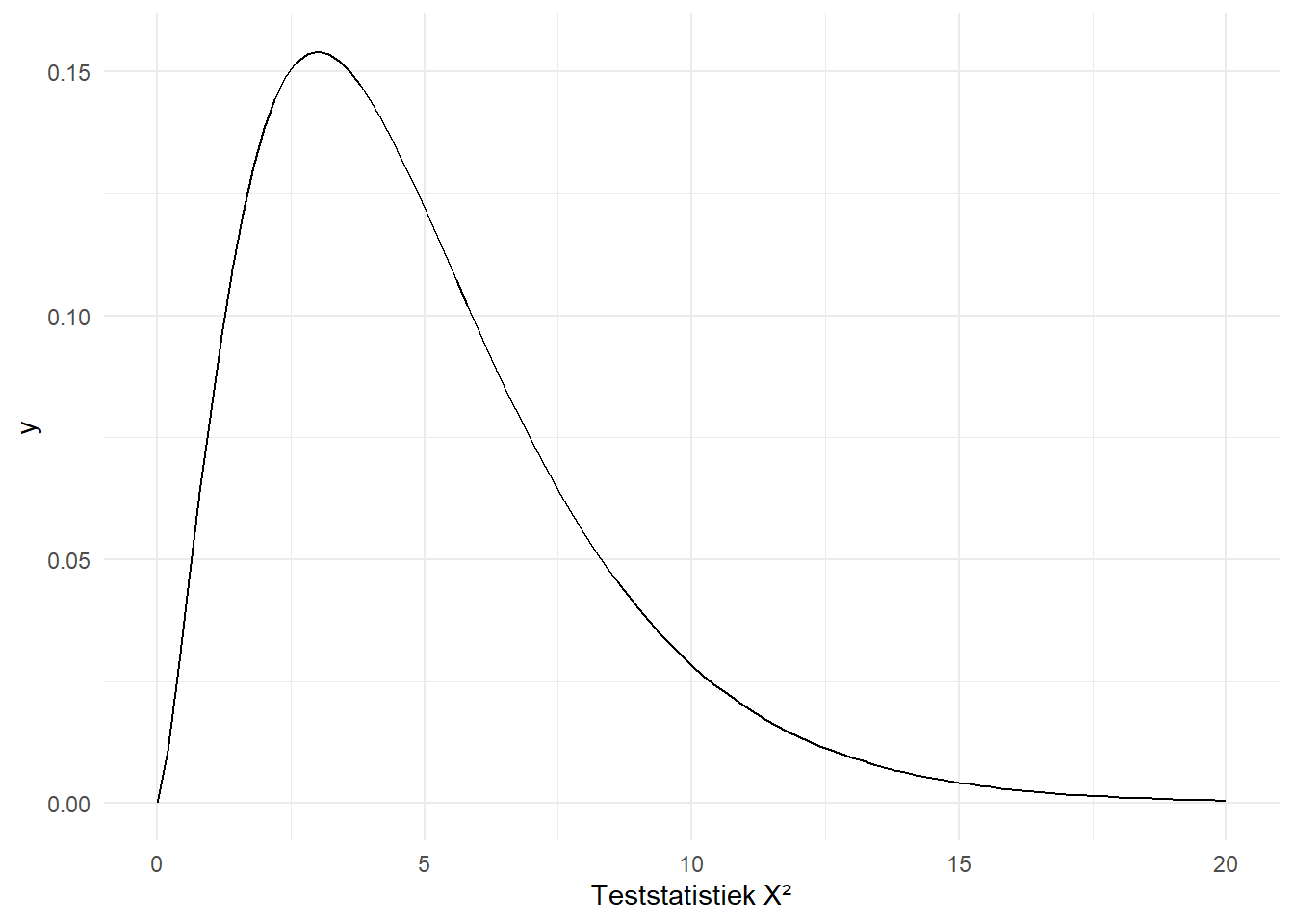
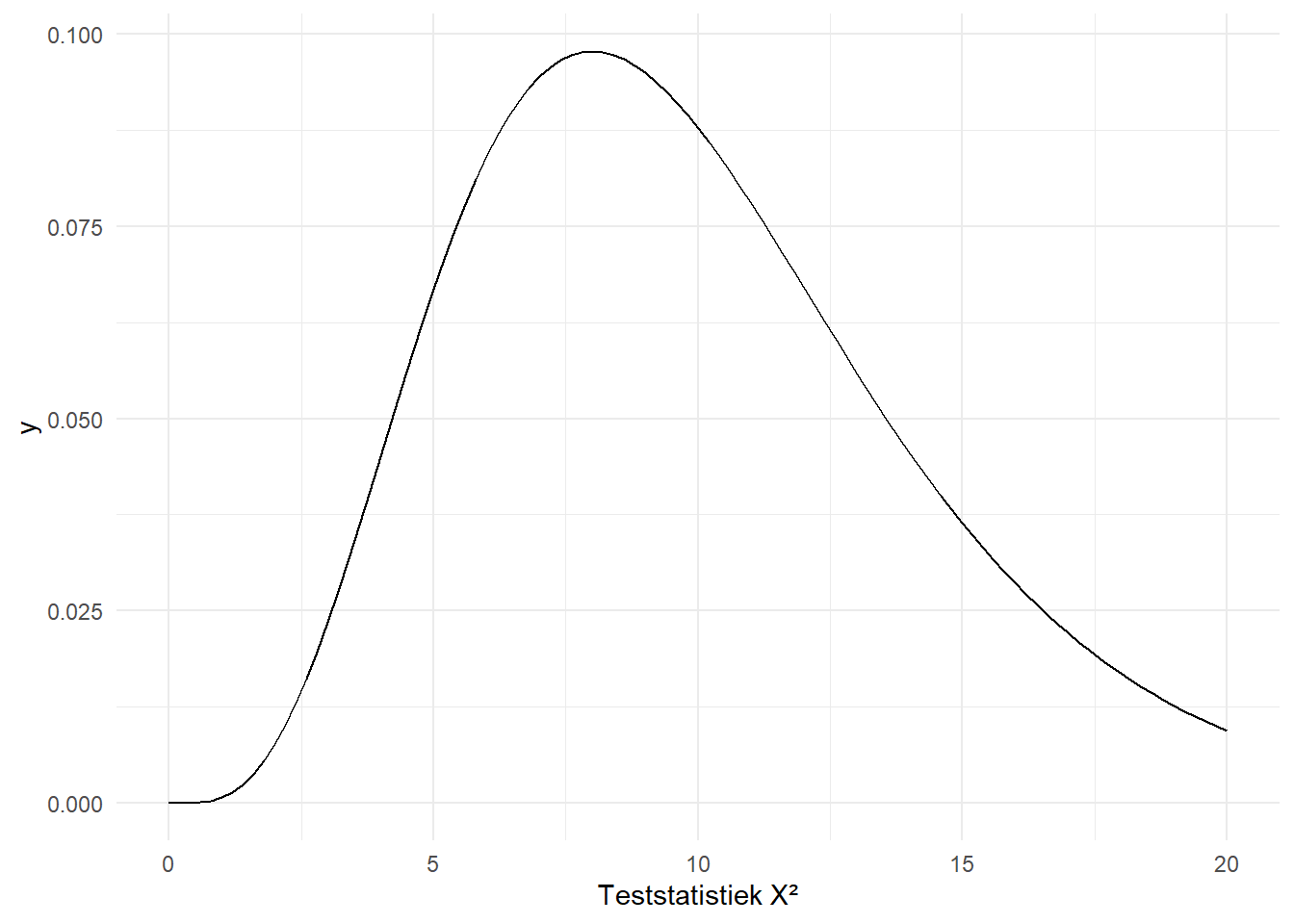
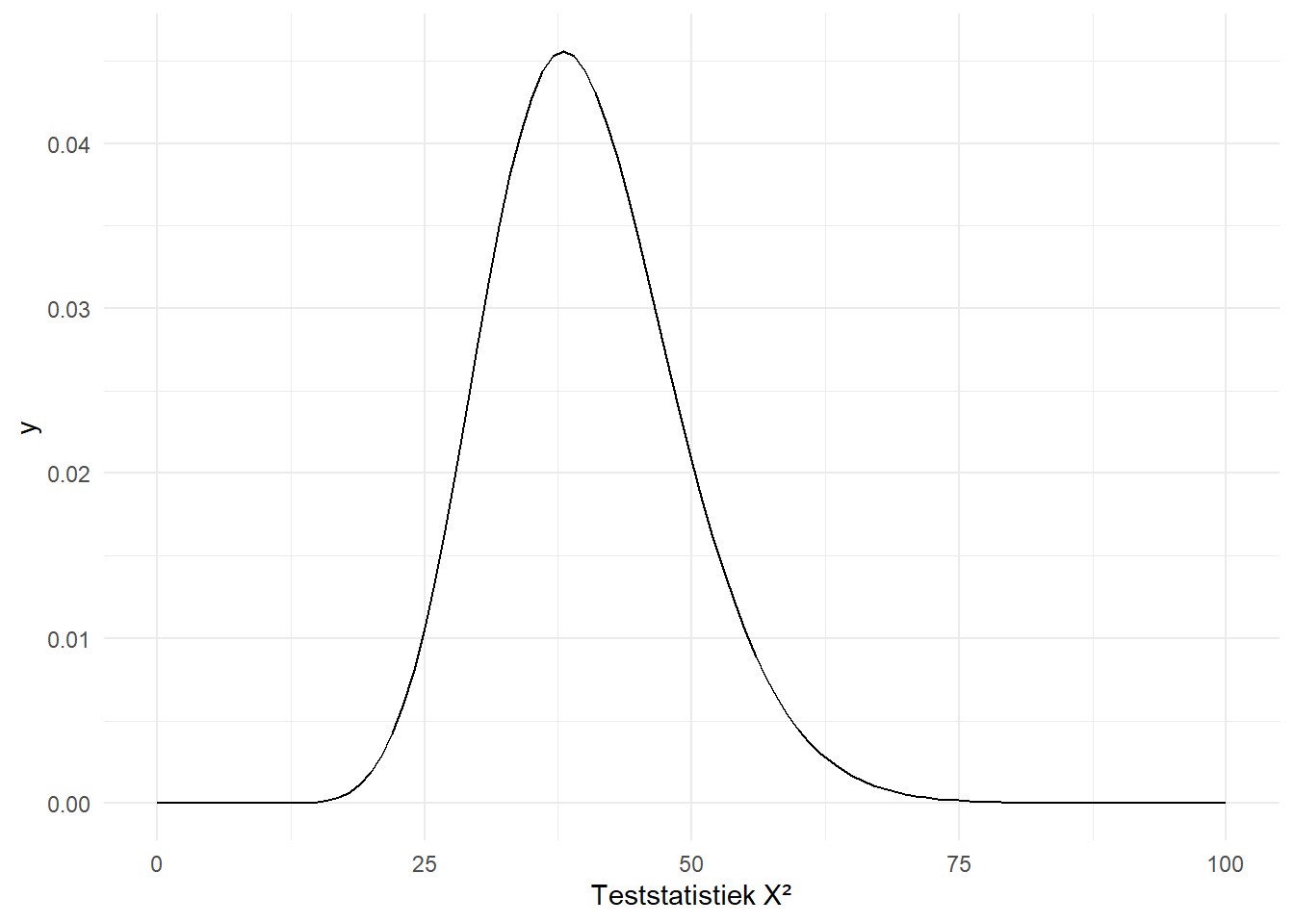
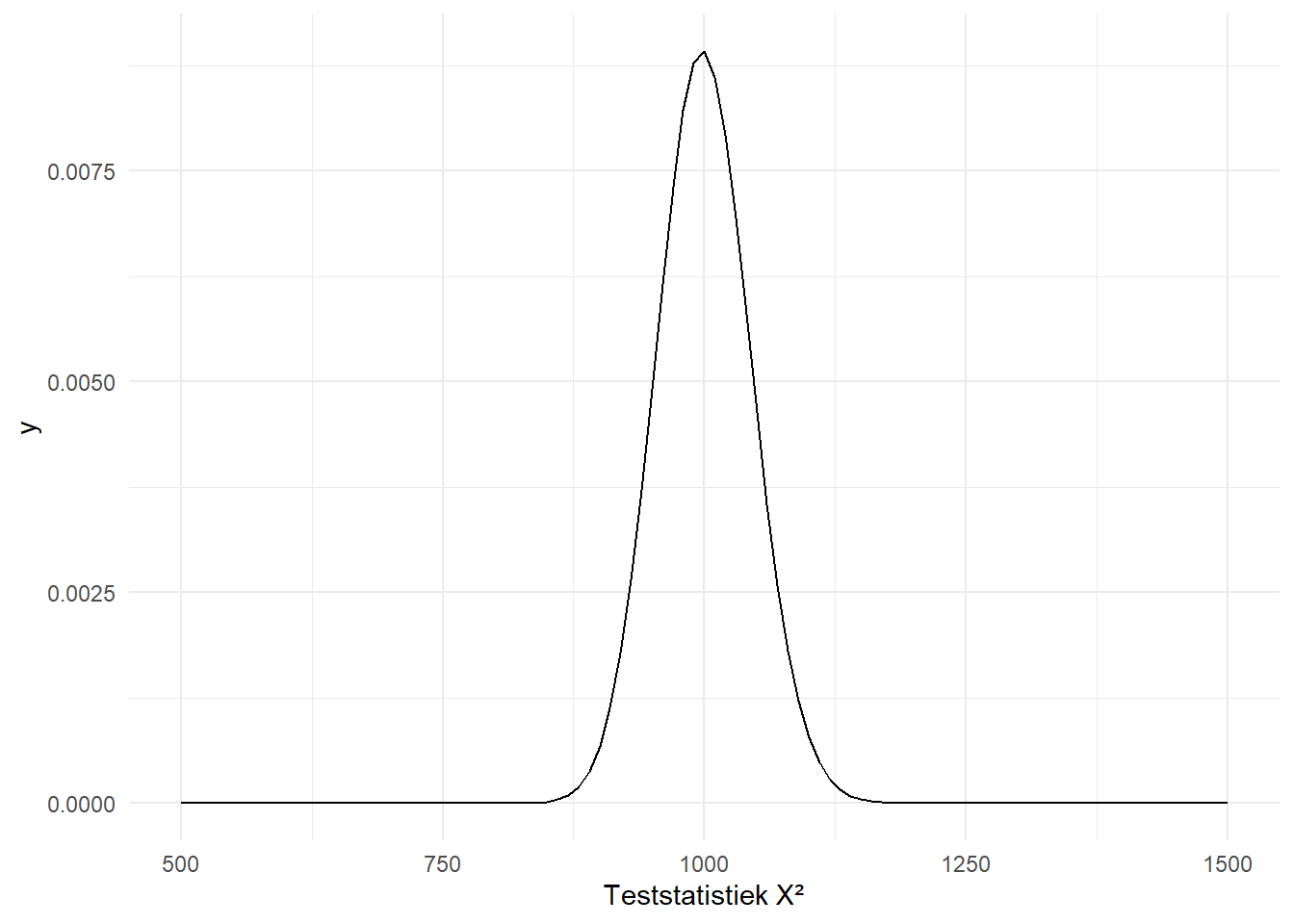
Onze testatistiek van \(183\) is duidelijk veel groter. Figure 10.6 toont nog een paar andere chikwadraatverdelingen, of beter gezegd, dezelfde verdeling maar met andere vrijheidsgraden.
(a) 1 vrijheidsgraad
(b) 5 vrijheidsgraden
(c) 10 vrijheidsgraden
(d) 20 vrijheidsgraden
(e) 40 vrijheidsgraden
(f) 1000 vrijheidsgraden
Figure 10.6: De Chikwadraatverdeling
10.8.1 Effectsterkte: Cramer’s V
Een sterk bewijs voor een effect is niet gelijk aan een bewijs voor een sterk effect. Om de sterkte van de samenhang tussen twee categorische variabelen te schatten kunnen we gebruik maken van Cramér’s V, die berekend wordt als in Equation 10.5
In de noemer staat \(N\) voor het totale aantal observaties in de dataset en \(min(k-1,r-1)\) voor het minimum van het koppel: aantal rijen min 1 en aantal kolommen min 1. Ter illustratie, voor een tabel met 4 rijen en 3 kolommen, geldt: \(min(k-1,r-1)=min(3-1,4-1)=min(2,3)=2\). Toegepast op ons voorbeeld krijgen we:
Een effectsterkte van \(19\%\) kan beschouwd worden als een zwakke associatie, op basis van de volgende interpretatie:
\(V=1\): perfecte associatie
\(V=0\): compleet gebrek aan associatie
\(V<0.25\): zwakke associatie
\(0.25<V<0.75\): matige associatie
\(V>0.75\): sterke associatie
Samengevat hebben we dus een sterk bewijs gevonden dat het gebruik van de s-possessiefvorm geassocieerd is met het gebruik van een niet-sibilant in auslaut (\(P < 0.0001\)), maar ook dat deze associatie eerder zwak is (Cramér’s V = 0.19). Dit suggereert dat er allicht nog andere variabelen zijn die geassocieerd zijn met de possessiefalternantie.
10.9 Goodness-of-fit
10.9.0.1 Versie 1: gelijke proporties
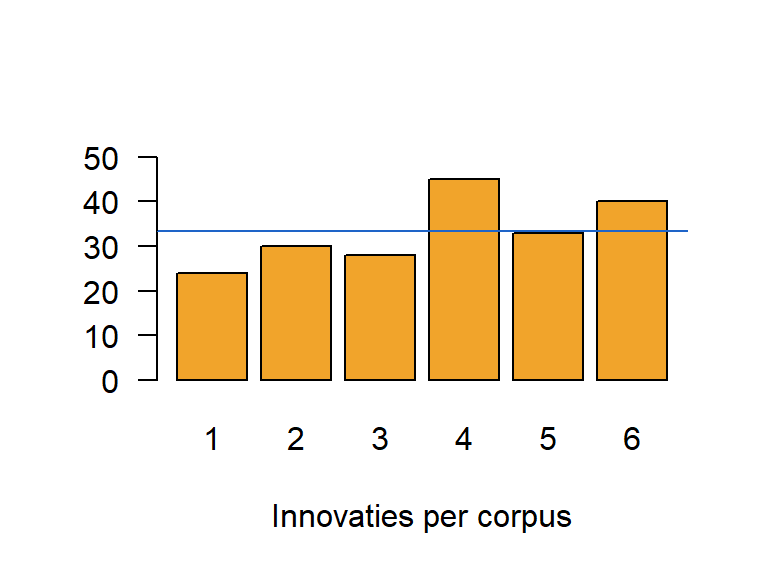
We namen zes steekproeven van \(20000\) woorden uit \(6\) verschillende maar vergelijkbare corpora waarvan ook het totale aantal woorden vergelijkbaar was (niet exact gelijk maar ook geen noemenswaardige verschillen). We telden het aantal innovaties. Table 10.5 biedt een overzicht van de geobserveerde frequenties \(f_o\) per corpus.
Table 10.5: Innovaties in zes corpussamples
Corpus
Innovaties
1
\(24\)
2
\(30\)
3
\(28\)
4
\(45\)
5
\(33\)
6
\(40\)
Gemiddeld genomen zijn er \(33\) innovaties per sample. Sommige samples hebben meer innovaties, andere minder. Zijn de afwijkingen groot genoeg om te besluiten dat er samples zijn met meer of minder innovaties dan de andere? Wijkt ten minste een van de samples significant af van de andere?
mean(c(24, 30, 28, 45, 33, 40))
[1] 33.33333
We kunnen verschillen visualiseren aan de hand van de staafdiagram in Figure 10.7.
inno <-c(24, 30, 28, 45, 33, 40)barplot(inno, xlab ="Innovaties per corpus",names =c("1", "2", "3", "4", "5", "6"), col ="#F1A42B", las =1,ylim =c(0,50))abline(a =mean(inno), b =0, col ="#1E64C8")
Figure 10.7: Aantal innovaties per corpus.
We zien dat er aanzienlijk minder innovaties voorkomen in het eerste corpus, terwijl er meer innovaties vastgesteld worden in 4 en 5. Maar zijn de verschillen groot genoeg om te besluiten dat er significante verschillen zijn in het aantal innovaties per corpus?
We formuleren de nul- en alternatieve hypotheses:
\(H_0\): de werkelijke proporties \(\pi_i\) zijn gelijk aan \(1/6\)
\(H_A\): de werkelijke proporties \(\pi_i\) zijn niet gelijk aan \(1/6\) (een of meerdere wijkt of wijken af van de verwachte proportie)
We vergelijken dus wat we observeren met wat we verwachten indien er geen verschil was (= \(H_0\)). We formuleren de hypotheses hier in termen van de proporties maar we kunnen even goed de verwachte frequenties gebruiken. En dan zie je onmiddellijk dat de situatie vergelijkbaar is met die van de kruistabel. Als teststatistiek kunnen we daarom de Pearson chikwadraattoets gebruiken:
\[
X^2=\sum \frac{(f_o-f_e)^2}{f_e}
\]
Het verwachte aantal berekenen we als het product van het totale aantal observaties \(N\) en de verwachte proportie \(p_i=1/6\), wat natuurlijk niets anders is dan het gemiddelde aantal observaties.
Chi-squared test for given probabilities
data: inno
X-squared = 9.22, df = 5, p-value = 0.1006
De test is niet significant. We aanvaarden de nulhypothese en besluiten dat er geen significant verschil is in het aantal innovaties (X² = 9, df = 5, P-waarde = 0.10).
10.9.0.2 Versie 2: verschillende proporties
Stel nu dat we hetzelfde onderzoek uitvoeren maar met steekproeven met verschillende aantallen, die we hebben toegevoegd aan Table 10.6.
Table 10.6: Innovaties in zes corpussamples met een verschillend aantal woorden
Corpus
Innovaties
n corpus
1
\(24\)
\(20000\)
2
\(30\)
\(45000\)
3
\(28\)
\(50000\)
4
\(45\)
\(55000\)
5
\(33\)
\(45000\)
6
\(40\)
\(30000\)
We berekenen het verwachte aantal nog steeds op dezelfde manier als \(f_e=N*p_i\), maar het verwachte aantal \(p_i\) is niet langer \(1/6\). We moeten immers rekening houden met het verschillend aantal woorden per corpus. De verwachte proportie \(p_i\) bekomen we door het aantal woorden per corpus te delen door het totale aantal woorden (in alle corpora samen).
\[
p_i=\frac{n_{corpus_i}}{N_{totaal}}
\]
Table 10.7 toont geeft de verwachte proporties en aantallen weer per corpus.
Table 10.7: Innovaties in zes corpussamples met een verschillend aantal woorden
Corpus
Innovaties
n corpus
\(p_i\)
\(f_e\)
1
\(24\)
\(20000\)
\(0.075\)
\(1.81\)
2
\(30\)
\(45000\)
\(0.170\)
\(5.09\)
3
\(28\)
\(50000\)
\(0.189\)
\(5.28\)
4
\(45\)
\(55000\)
\(0.208\)
\(9.34\)
5
\(33\)
\(45000\)
\(0.170\)
\(5.60\)
6
\(20\)
\(50000\)
\(0.189\)
\(4.90\)
In chisq.test() moeten we nu de verwachte proporties toevoegen, voor het overige blijft alles exact hetzelfde.
chisq.test(x = inno, p = propexp)
Chi-squared test for given probabilities
data: inno
X-squared = 19.069, df = 5, p-value = 0.001866
De testatistiek \(X²=19\) is bij \(df=5\) vrijheidsgraden statistisch significant op het \(5%\) significantieniveau. We beslissen om de nulhypothese te verwerpen en de alternatieve hypothese te aanvaarden dat ten minste een van de aantallen innovaties afwijkt van de andere. We inspecteren de gestandaardiseerde residuelen; afwijkingen van groter dan \(|2|\) wijzen dus op significante afwijkingen van de nulhypothese.
We observeren twee significante afwijkingen: in het derde corpus zijn er minder innovaties dan verwacht, in het derde corpus zijn er meer innovaties dan verwacht.
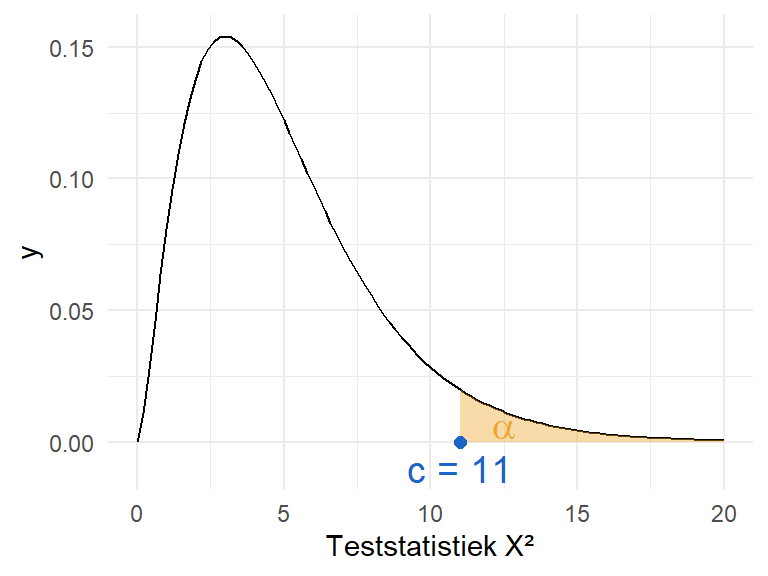
We tekenen een chikwadraatverdeling met 5 vrijheidsgraden en duiden het \(5\%\)-significantieniveau aan en de geassocieerde kritische waarde. De kritische waarde bedraagt \(11\).
qchisq(p =0.05, df =5, lower.tail =FALSE)
[1] 11.0705
Figure 10.8: Een chikwadraatverdeling met 5 vrijheidsgraden en het 5% significantieniveau.
10.10 Classificatiebomen
Met een chikwadraattoets onderzoeken we de samenhang tussen twee categorische variabelen. Het is tegenwoordig een populair onderzoeksthema binnen de variatielinguïstiek om na te gaan hoe een binaire uitkomstvariabele samenhangt met een reeks categorische predictorvariabelen. Alhoewel we ons in deze cursus beperken tot bivariate relatie, maak ik hier toch een zijsprong naar de multivariatie statistiek om een populaire en vrij eenvoudige statistische analyse toe te lichten.
10.10.0.1 Voorbeeld
Verroens & De Cuypere (2023) onderzochten de Franse ingressiefalternantie, geïllustreerd in voorbeeld (3).2 De samenhang tussen deze uitkomstvariabele en verschillende predictorvariabelen werd onderzocht.
Alex a commencé à chanter la Marseillaise.
Il s’est mis à courir.
Het uitgangspunt was dat er geen enkele variabele is die de alternantie volledig bepaalt, maar dat er een samenspel is van verschillende factoren. Een dergelijke hypothese vraagt een multivariate data analyse. Het heeft geen zin om aparte chikwadraattoetsen uit te voeren. Aparte testen kunnen wel een zekere indicatie geven van welke factoren belangrijk zijn, maar in het samenspel kunnen onverwachte samenwerkingen optreden die niet blijken uit aparte testen. Verroens & De Cuypere (2023) gebruikten een logistische regressie analyse met een random intercept. Hier gebruiken we een ander multivariaat model: een classificatieboom (ook wel een “beslissingsboom” genoemd). De dataset voor deze studie werd gepubliceerd in de TROLLing repository als Verroens & De Cuypere (2022). Het abstract geeft toelichting bij de data:
The dataset includes an annotated corpus sample of N = 2000 French sentences with se mettre à or commencer à (1000 observations of each verb). The sample was drawn from the literary corpus Frantext (FT) and the journalistic corpus Le Monde (1000 observations from both corpora). The sample is balanced for verb as well as corpus, so we have 500 observations for each Verb-Corpus combination. The data is annotated for 8 variables: Source (corpus), Verb, Mood & Tense, Event type, Adverb presence, Adverb token, and Adverb type.
ID Source Verb Mood_Tense
COMA_FT_5972: 1 frantext:1000 commencer à:1000 ind présent :730
COMA_FT_5973: 1 le monde:1000 se mettre à:1000 passé composé:484
COMA_FT_5974: 1 ind imparfait:279
COMA_FT_5975: 1 passé simple :238
COMA_FT_5976: 1 infinitif : 88
COMA_FT_5977: 1 pl q parfait : 44
(Other) :1994 (Other) :137
Event_Type Adverb Adverb_Token Adverb_Type
accomplishment: 363 absent :1928 déjà : 18 DurProg: 26
achievement : 218 present: 72 soudain : 12 VelSud : 46
activity :1136 tout à coup: 9 NA's :1928
state : 283 aussitôt : 6
vite : 5
(Other) : 22
NA's :1928
We wensen het simultane effect te modelleren van meerdere predictoren te op de uitkomstvariabele Verb aan de hand van een classificatieboom. Een classificatieboom is een model dat gecreëerd wordt via een algoritme dat de data recursief opdeelt op basis van de relaties tussen de uitkomstvariabele en de perdictorvariabelen. Beschouw Figure 10.9, die een conceptuele voorstelling weergeeft van een classificatieboom.
flowchart TD
A[Data] -->B{"`statistische test
PRED1`"}
B --> D[Subset1]
B --> E[Subset2]
B --> F[Subset3]
D --> G{"`statistische test
PRED2`"}
E --> H{"`statistische test
Pred3`"}
G --> I[Subset 4]
H --> J[Subset 5]
Figure 10.9: Een conceptuele voorstelling van een classificatieboom.
Het algoritme verloopt als volgt:
Evalueer op basis van een statistische test elke bivariate relatie tussen de uitkomstvariabele en alle predictoren. De predictor met de sterkste impact (wat op verschillende manieren bepaald kan worden) verdeelt de data in subsets.
Binnen elke subset wordt opnieuw stap 1 toegepast, waardoor je opnieuw subsets krijgt.
Herhaal stap 1 en 2 tot er geen significante relaties tussen de uitkomstvariabele en de predictoren meer overblijft. Dit kan ook gebeuren omdat je gekozen hebt dat een subset een minimum aantal observaties moet hebben.
Op die manier krijg je een reeks splitsingsregels en subsets die je samen kunt visualiseren als een beslissingsboom.
We passen hier het ctree() algoritme toe uit het party package. ctree staat voor Conditional Inference Tree, een algoritme dat tegenwoordig de standaard is geworden vanwege allerlei voordelen ten opzichte van andere algoritmes (het zou te technisch worden om ons in die aspecten te verdiepen, hier is dus een kleine geloofssprong nodig).
We zullen een boom fitten op basis van drie predictoren: Event_Type, Adverb en Adverb_Type. Eerst passen we de levels van de uitkomstvariabele aan om straks een mooiere figuur te krijgen.
en verander deze dan met nieuwe namen (in feite overschrijf je de oude)
[1] "commencer à" "se mettre à"
We openen vervolgens het party package en fitten ons model. Zoals je kunt zien is dit eigenlijk zeer gemakkelijk (zolang je geen interne opties wenst aan te passen om het model te optimaliseren).
Het model visualiseren we vervolgens als een beslissingsboom in Figure 10.10.
plot(tree, controls =ctree_control(maxdepth =2), terminal_panel =node_barplot(tree, col ="black", fill =c("#1E64C8","#F1A42B"), beside = T, id =TRUE))
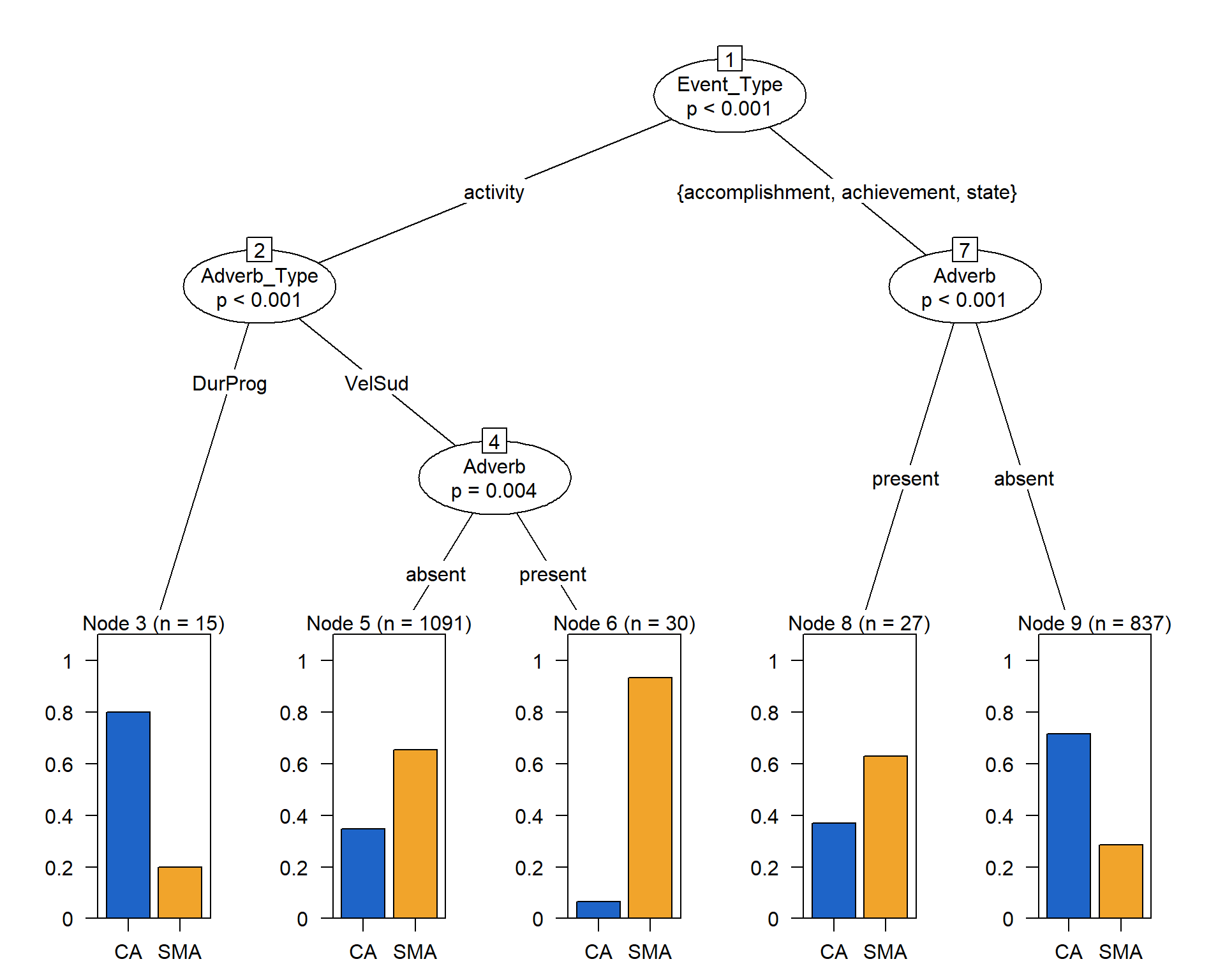
Figure 10.10: Een Conditional Inference tree voor de Franse ingressiefalternantie.
De visualisatie is vrij intuïtief te interpreteren. De eindknopen onderaan zijn de uitkomsten die het model voorspelt op basis van de verschillende combinaties tussen de variabelen die in de boom voorkomen. “Node3”, bijvoorbeeld toont een “voorkeur” voor – of, beter nog, de grootste probabiliteit of kans op – “CA”. De y-waarden zijn probabiliteiten (dus altijd waarden tussen \(0\) en \(1\)). Laten we even kijken hoe deze voorkeur voorspeld wordt. We beginnen daarvoor bovenaan bij de eerste knoop (Node 1), de predictor Event_Type, die in deze boom als belangrijkste predictor weerhouden wordt. De predictor scheidt de data op basis van het verschil tussen “activity” vs. de overige drie event types. We volgen “activity” naar knoop 2 Adverb_Type, en zien dat “DurProg” (bijwoorden met een duratieve of progressieve betekenis) in combinatie met “activity” leidt tot een voorspelde probabiliteit van \(80\%\) voor commencer à, en een probabiliteit van \(20\%\) voor se mettre à. We hebben dus een voorspelde probabiliteit voor beide uitkomsten op basis van de combinatie van twee predictoren, en dus een multivariate voorspelling. Op dezelfde manier kun je de overige predictorcombinaties en voorspelde uitkomsten uit de figuur afleiden.
Pas op, de voorspellingen van het model zijn niet \(100\%\) correct, het model doet immers ook foute voorspellingen! Zoals we leren uit de confusionmatrix, die de voorspelde uitkomsten vergelijkt met de geobserveerde waarden in het corpus, komt een goeie \(68\%\) van de uitkomsten in de boom overeen met de waarden in de steekproef. Omgekeerd, \(32\%\) van alle rijen in de dataset worden dus verkeerd voorspeld. Maar dit is nog steeds beter dan wat je verwacht, mocht je blind gokken. Dan verwacht je namelijk dat je een “correcte” voorspelling zal maken – puur op basis van toeval natuurlijk – van \(50\%\). Maar omdat ons multivariate model beter presteert dan \(50\%\) zijn we bereid om te concluderen dat we iets hebben bijgeleerd over de relatie tussen de uitkomstvariabele en de onderzochte predictoren.
We zouden kunnen proberen om het model te optimaliseren door extra variabelen toe te voegen of door opties in het algoritme aan te passen, maar dat zou in essentie niet zoveel veranderen, behalve dat het voorspellingspercentage zou kunnen verbeteren.
Een van de nadelen van een classificatieboom is de neiging tot overfitting. Overfitting betekent dat een model zeer goede voorspellingen doet voor de data waarop het gefit werd maar dat het model slechte voorspellingen doet voor nieuwe data. Het CIT-algoritme is in dat opzicht al een grote verbetering ten opzichte van oudere algoritmes (de details laat ik hier achterwege). Wat vaak gedaan wordt om de stabiliteit van een boom te onderzoeken is een hele reeks bomen fitten – een heel bos eigenlijk, want we spreken van een random forest – en om dan te kijken wat in het bos de belangrijkste predictoren zijn. Een random forest is een classificatiemethode uit de machine learning.
Het fitten van een random forest is technisch complex en geavanceerd, maar is met de partykit::cforest() functie opnieuw zeer eenvoudig uit te voeren in R.
library(partykit)
1
de modelformule
2
enkele opties om de boom te laten groeien
3
aantal bomen in het bos
4
de dataset
Loading required package: libcoin
Attaching package: 'partykit'
The following objects are masked from 'package:party':
cforest, ctree, ctree_control, edge_simple, mob, mob_control,
node_barplot, node_bivplot, node_boxplot, node_inner, node_surv,
node_terminal, varimp
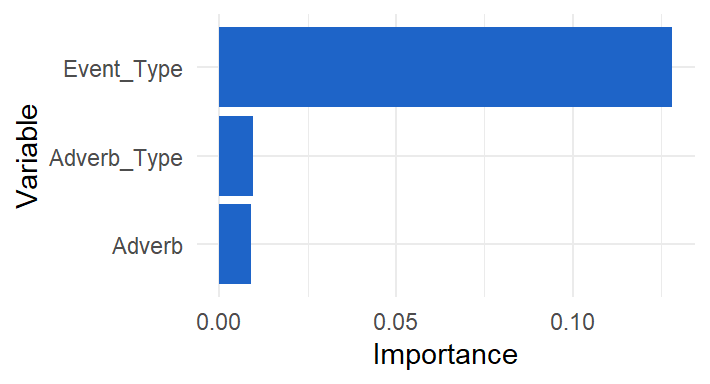
Figure 10.11: De belangrijkste variabelen volgens het random forest model.
Event_Type is volgens het model de belangrijkste predictor, wat in lijn ligt met de classificatieboom. Hoe goed voorspelt de random forest?
ct <-table(fring$Verb, predict(rf,OOB =TRUE, type ="response"))ct
CA SMA
CA 608 392
SMA 256 744
sum(diag(ct))/sum(ct)
[1] 0.676
De random forest voorspelt met \(67.7%\) iets minder goed, maar de evaluatie is wel gebaseerd op observaties die niet werden gebruikt voor het gefitte model, waardoor er dus gecorrigeerd wordt voor overfitting. Het argument “OOB” staat voor “out-of-bag”, wat betekent dat het model gefit wordt op een deel van de data en dat de voorspelling gebeurt op een ander deel van de data. Er bestaat allerlei manieren om een dergelijke “crossvalidatie” uit te voeren, maar daar gaan we hier niet op in.
Een nadeel van een random forest is dat het een zogenaamd “black box” model is; je kunt geen \(2000\) bomen tekenen en die allemaal interpreteren. Er bestaan manieren om de predictoreffecten van black box models beter te interpreteren (bvb. via zogenaamde “SHAP”-waarden), maar dat valt buiten de opzet van dit handboek.
10.11 Samenvatting en vooruitblik
De chikwadraattoets is een van de eerste statistische testen die gebruikt werden in de taalwetenschap. De categorische variabele vormt in meerdere takken van de taalwetenschap immers de belangrijkste datatypes. Zoals steeds vormt een correcte en genuanceerde samenvatting en visualisatie van de data een fundamenteel onderdeel van de data analyse. Begin nooit zomaar met significantietoetsen. Ik heb dit hoofdstuk afgesloten met twee geavanceerde modellen, de classificatieboom en de random forest. Beide modellen zijn relatief eenvoudig om te fitten en te interpreteren, wat hun populariteit in de huidige corpuslinguïstiek verklaart. Verdere uitbreidingen op de bivariate categorische data analyse zijn de hierarchische clusteranalyse, de logistische regressie, de (meervoudige) correspondentieregressie (Plevoets 2018), en de behavioral profile analyse (Gries and Divjak 2009).
10.12 Terminologie
proportie (fractie)
steekproevenverdeling van de steekproefproportie
test voor twee proporties
proportie (fractie)
steekproevenverdeling van de steekproefproportie
test voor een proportie
test voor twee proporties
marginale totalen
rij- vs. kolomtotalen
gezamelijke, marginale en voorwaardelijke kans
geclusterde vs. gestapelde staafdiagram
chikwadraattoets
Goodness of fit
residuelen
cramér’s V
classificatieboom
random forest
geom_bar()
geom_col()
geom_line()
rbinom()
prop.test()
table()
prop.table()
gmodels::CrossTable()
addmargins()
chisq.test()
qchisq()
levels()
party::ctree()
partykit::cforest()
varimp()
10.13 Oefeningen
Finale verscherping in het Nederlands. In het Nederlands kunnen stemhebbende obstruenten aan het einde van een syllabe stemloos worden (bvb. /d/ wordt /t/ in hand) (Booij 2020). Het LanguageR package bevat de dataset finalDevoicing met 1697 geannoteerde woorden met en zonder finale verscherping. Om wat meer informatie te krijgen over de data kun je het package laden en vervolgens via het tabblad help in RStudio naar de informatiepagina over de dataset gaan.
Open de dataset finalDevoicing en geef een samenvatting van alle variabelen
Maak een tabel met geobserveerde waarden en proporties voor de variabele Voice.
Geef Voice weer aan de hand van een staafdiagram.
Maak een kruistabel met Voice als kolomvariabele en Onset1Type als rijvariabele.
Geef de rijproporties weer en interpreteer de resultaten
Maak een geclusterde staafdiagram om de relatie tussen Voice en Onset1Type weer te geven.
Voer een chikwadraattest uit om na te gaan of er een significante afhankelijkheidsrelatie bestaat tussen beide variabelen.
Bereken Cramér’s V indien de relatie significant is.
Twee proporties vergelijken. Beschouw de danish dataset in het languageR package. Gebruik de test voor twee proporties om na te gaan of er evenveel observaties zijn voor mannen als voor vrouwen.
Classificatiebomen. De Engelse datiefalternantie verwijst naar de alternantie tussen twee zinsconstructies met ditransitieve werkwoorden, zoals in (1) Mark gave her a present en (2) Mark gave a book to his friend. De syntactisch variant in (1) wordt de Double Object Construction genoemd, die in (2) de To-Dative Construction. In deze dataset wordt niet over constructies gesproken maar over de realisatie van de Recipient (RealizationOfRecipient), waarbij de Recipient in (1) als een NP (Noun Phrase) gerealizeerd wordt, en die in (2) als een PP (Prepositional Phrase). Een belangrijke onderzoeksvraag in het alternantieonderzoek luidt: met welke variabele is de alternantie geassocieerd? Merk bijvoorbeeld op dat indien de Recipient als een pronominaal object gerealiseerd wordt, de NP iets “natuurlijker” lijkt dat de PP. Vergelijk bijvoorbeeld (1) met (3) Mark gave a presentto her. We zouden de relatie tussen de realisatie van het Recipient en alle mogelijke predictoren afzonderlijk kunnen onderzoeken door middel van afzonderlijke chikwadraattoetsen, maar het is beter om de simultane associatie tussen meerdere predictoren en de uitkomstvariabele na te gaan aan de hand van een multivariaat model. Een vrij eenvoudige modellering is de klassificatieboom.
Fit een classificatieboom met de ctree functie, met RealizationOfRecipient als uitkomst en alle andere variabelen als predictoren.
Geef een visuele voorstelling van de boom.
Wat is de proportie correct voorspelde uitkomsten van de boom?
Interpreteer de verschillende voorspellingspaden in de boom.
Goodness of fit. Nieuwsberichten die op de redactie verschijnen worden niet zomaar in de krant gepubliceerd maar doorlopen een reeks aanpassingen door redacteurs. Die aanpassing gaan van stukken herschrijven of schrappen tot kleinere aanpassingen in spelling en interpunctie. Vandendaele, De Cuypere, and Van Praet (2015) onderzocht ingrepen door de redactie in nieuwsberichten. De onderzoekers waren geïnteresseerd of nieuwsberichten sterker worden aangepast naargelang de plaats waar ze verschijnen in de krant. Zo zouden redacteurs meer veranderingen aanbrengen in Headline news articles. Levert Table 10.8 daarvoor een bewijs?
Table 10.8: Interventies per type artikel.
Type artikel
Aantal woorden
Aantal interventies
Front page
118568
350
Headline
261527
402
Medium
205613
387
News
62454
177
News wire
21406
108
Short news
27437
116
Statistiek in de sociolinguïstiek. Fischer (1958) onderzocht de realisatie van de finale cluster -ing bij 24 kinderen in een dorp in Engeland. De -ing-cluster wordt er op twee manieren gerealiseerd: enerzijds als een stemhebbende velaire nasaal /-iŋ/ en anderzijds als een stemhebbende alveolaire nasaal /-in/. Fischer liet de kinderen een verhaaltje vertellen en hij noteerde welke variant ze meestal gebruikten. Voor elke kind hebben we dus 1 observatie. Table 10.9 vat de observaties samen. Fischer was een van de eersten in de taalwetenschap om een statistische test toe te passen op een dergelijke tabel. Treed in zijn voetsporen en voer de chikwadraattest uit om het verband te testen. Formuleer je conclusie.
Table 10.9: De realisatie van -ing in relatie tot geslacht
/-iŋ/
/-in/
Boys
5
7
Girls
10
2
Teken de verdeling van de teststatistiek uit oefening 5 en duid aan:
Grafmiller, Jason. 2023. “The Genitive Alternation in 1960s and 1990s American English: Data from the Brown and Frown Corpora.” DataverseNO. https://doi.org/10.18710/R7HM8J.
Gries, Stefan Th., and Dagmar Divjak. 2009. “Behavioral Profiles.” In, 57–75. John Benjamins Publishing Company. https://doi.org/10.1075/hcp.24.07gri.
Roy, Tarun Kumar, Rajib Acharya, and Arun Roy. 2016. “Introduction to Sample Survey Designs.” In, 1–12. Cambridge University Press. https://doi.org/10.1017/cbo9781316550892.003.
Vandendaele, Astrid, Ludovic De Cuypere, and Ellen Van Praet. 2015. “Beyond ‘Trimming the Fat.’ The Sub-Editing Stage of Newswriting.”Written Communication 32 (4): 368–95.
Verroens, Filip, and Ludovic De Cuypere. 2022. “Replication Data for: French Ingressives and (Phasal) Aspect. A Frame-Semantic Corpus-Based Analysis.” DataverseNO. https://doi.org/10.18710/WVW9U4.
———. 2023. “French Ingressives and (Phasal) Aspect: A Frame-Semantic Corpus-Based Analysis.”Canadian Journal of Linguistics/Revue Canadienne de Linguistique 68 (3): 435–61. https://doi.org/10.1017/cnj.2023.19.