Zeer eenvoudig gesteld is een dataframe een R-object dat een dataset weergeeft. Als kennismaking met de dataframe bouwen we zelf eerst twee dataframes door vectoren van gelijk type en gelijke lengte samen te voegen in één dataframe. Nadien openen we een externe dataset. Het gebeurt immers maar zelden dat men in R een dataset creëert, behalve voor pedagogische doeleinden of als datasimulatie. Doorgaans zal een onderzoeker een dataset in MS Excel of andere gespecialiseerde software opmaken om die daarna te openen in R.
3.1 Een dataframe maken in R: voorbeeld 1
Table 3.1 stelt een eenvoudige dataset voor op basis van een Lexicale Decisie Taak. Dit is een experiment waarbij participanten zo snel mogelijk moeten aanduiden of een woord al dan niet bestaat. Het is een zeer kleine dataset van slechts \(N=6\) observaties.
Table 3.1: Een dataset op basis van een lexicale decisie taak
Participant
Item
Frequentie
Reactietijd
1
a
hoog
320
2
b
laag
380
3
c
laag
400
4
d
hoog
300
5
e
hoog
356
6
f
laag
319
Table 3.2 is het codeboek met metadata voor elke variabele
Table 3.2: Het codeboek voor de dataset van de lexicale decisie taak
ID
Variabele
Toelichting
1
Participant
een uniek identificatienummer voor elke participant
2
Item
het woord dat als stimulus gebruikt werd
3
Frequentie
de frequentie van het item, een binaire categorische variabele; “hoog” vs. “laag”
4
Reactietijd
de reactietijd (in ms) van departicipant op het item
Eerst wordt elke vector apart gemaakt. In feite zijn dit de kolommen met hun hoofding of nog accurater, de variabelen met hun naam. Ik geef zorg altijd voor een ID-variabele, zodat elke rij een uniek identificatienummer geeft
2
met de functie data.frame() worden alle vectoren samengebracht tot een dataframe
3
we printen de dataframe in R.
Participant Item Freq RT
1 1 a hoog 320
2 2 b laag 380
3 3 c laag 400
4 4 d hoog 300
5 5 e hoog 356
6 6 f laag 319
3.2 Een dataframe maken in R: voorbeeld 2
We simuleren nu een artificiële dataset waarbij we de scores (op \(20\)) vergelijken tussen twee groepen: een groep die we eerst een behandeling (“treatment”) gaven, en we noemen deze groep “Treat”, en een controlegroep (“Control”). “Behandeling” is een algemene term en is niet beperkt tot een medische behandeling. In de context van een pedagogisch onderzoek, bijvoorbeeld, kan een behandeling bestaan uit het volgen van een nieuwe leermethode. De dataset ziet eruit als in
ID
Groep
Score
1
control
14
2
control
15
…
…
…
59
treat
12
60
treat
17
ID is een uniek identificatienummer voor elke observatie.
Group is een binaire categorische variabele.
Score is een continue variabele. We nemen twee steekproeven uit twee normale verdelingen met een zelfgekozen gemiddelde en een zelfgekozen standaardafwijking.
1Group <-gl(n =2,2k =30,3labels =c("Control", "Treat"))4Score <-c(round(rnorm(n =30, mean =16, sd =0.8),0),round(rnorm(n =30, mean =12, sd =0.9),0))5df <-data.frame(Group, Score)6head(df)
1
We creëren een factor met 2 levels
2
en 30 observaties voor elke level
3
de namen van de 2 levels
4
een vector van 2 steekproeven van 30 observaties uit een normale verdeling met een eigen gemiddelde en een eigen standaardafwijking. Afgerond.
5
we brengen beide variabelen samen in een dataframe
6
en bekijken de eerste 6 rijen.
Group Score
1 Control 16
2 Control 17
3 Control 15
4 Control 16
5 Control 16
6 Control 16
Wens je de data te bekijken in een apart tabblad dan gebruiken we View().
View(df)
3.3 Data uploaden uit R
Base-R en andere packages hebben ingebouwde datasets. We openen de sleep dataset door heel eenvoudig sleep in te geven.
extrais een numerieke variabele (een getal met cijfers na de komma). group en ID zijn “factors”, categorische variabelen met respectievelijk 2 en 10 mogelijke waarden. De output voor de factorvariabelen lees je als volgt:
$ group: Factor w/ 2 levels "1", "2": 1 1 1 ...
“1” en “2” zijn de namen van de levels, die r omzet naar numerieke waarden, 1 en 2. 1 1 1 betekent dat de eerste drie waarden van de variabelen “1” zijn. De levels worden door r alfabetisch gerangschikt, tenzij anders aangegeven.
3.4 Een tekstbestand openen als dataframe
Het is ongebruikelijk om een dataset rechtstreeks in R te maken. Doorgaans gebruiken onderzoekers een spreadsheet zoals MS Excel. Voor hele grote datasets kan er met een relationele databank gewerkt worden (bvb. een Oracle Database). Voor gespecialiseerde data wordt er ook vaak specifieke software gebruikt (bvb. PRAAT of ELAN voor gesproken tekstdata). Nadat de data werd verzameld, opgekuist en geannoteerd, wordt de data vervolgens opgeslagen als een tekstsbestand (.csv- of .txt-bestand). Bij een .txt bestand dient de tab als scheidingsteken, bij een .csv is dat een kommapunt “;”.
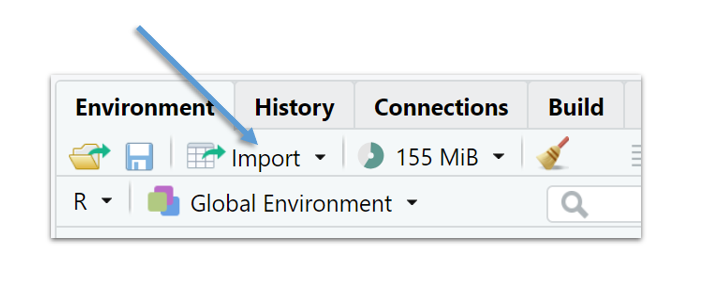
De eenvoudigste manier in RStudio om een .txt- of .csv-bestand te openen is via het tabblad Environment > Import data, zoals aangeduid in Figure 3.1:
Figure 3.1: Import in RStudio
Data openen in R is een gekende uitdaging voor beginners. Er bestaan verschillende functies om databestanden te openen en de kleinste fout leidt tot een foutmelding. Dit kan een frustrerende ervaring zijn. De enige remedie is blijven proberen.
Als voorbeeld openen we de .csv-dataset van De latte (2023). Deze een dataset werd gepubliceerd in de online repository TROLLing (https://dataverse.no/dataverse/trolling/). Het abstract biedt een samenvatting van de data.
This dataset contains one datafile (.csv) used to create the graphs and tables in the paper “(Im)polite uses of vocatives in present-day Madrilenian Spanish”. It includes 534 Spanish vocative tokens, i.e. (pro)nominal terms of direct address (e.g., tío ‘dude’), which were retrieved from CORMA, a conversational corpus of peninsular Spanish compiled between 2016 and 2019. The data is annotated for (i) form, (ii) communication, (iii) semantic category, (iv) speaker’s generation, (v) speaker’s gender, (vi) relationship between speaker and hearer, (vii) socio-pragmatic character of the hosting speech act, (viii) the hearer’s reaction, and (ix) the vocative’s socio-pragmatic effect.
Traditioneel en voor de komst van de notebook, diende men eerst een “working directory” aan te duiden. De working directory is de map waar je je code, R-code en output opslaat. De working directory kan opgevraagd worden via getwd() en veranderd worden via setwd().
Als je r-script en .csv-bestand in dezelfde map zitten, en je hebt deze map aangeduid als je working directory, dan kun je onderstaande code gebruiken om de data te openen. Indien je een Notebook gebruikt, dan hoef je zelfs geen working directory aan te duiden; zorg er gewoon voor dat je notebook en data in dezelfde map zitten.
Bij grote datasets is het handig om een overzicht te krijgen van alle namen van de variabelen.
names(sleep)
[1] "extra" "group" "ID"
Hoeveel rijen en kolommen heeft de dataframe?
dim(sleep)
[1] 20 3
20 rijen en 3 kolommen.
Elke data-analyse begint met een univariate samenvatting. We gebruiken hiervoor de summary() functie.
summary(sleep)
extra group ID
Min. :-1.600 1:10 1 :2
1st Qu.:-0.025 2:10 2 :2
Median : 0.950 3 :2
Mean : 1.540 4 :2
3rd Qu.: 3.400 5 :2
Max. : 5.500 6 :2
(Other):8
R-auteurs hebben gelijkaardige functies gemaakt voor andere packages Dit is bijvoorbeeld de describe() functie in Hmisc(Harrell Jr 2023).
library(Hmisc)describe(sleep)
sleep
3 Variables 20 Observations
--------------------------------------------------------------------------------
extra
n missing distinct Info Mean Gmd .05 .10
20 0 17 0.998 1.54 2.332 -1.220 -0.300
.25 .50 .75 .90 .95
-0.025 0.950 3.400 4.420 4.645
Value -1.6 -1.2 -0.2 -0.1 0.0 0.1 0.7 0.8 1.1 1.6 1.9 2.0 3.4
Frequency 1 1 1 2 1 1 1 2 1 1 1 1 2
Proportion 0.05 0.05 0.05 0.10 0.05 0.05 0.05 0.10 0.05 0.05 0.05 0.05 0.10
Value 3.7 4.4 4.6 5.5
Frequency 1 1 1 1
Proportion 0.05 0.05 0.05 0.05
For the frequency table, variable is rounded to the nearest 0
--------------------------------------------------------------------------------
group
n missing distinct
20 0 2
Value 1 2
Frequency 10 10
Proportion 0.5 0.5
--------------------------------------------------------------------------------
ID
n missing distinct
20 0 10
Value 1 2 3 4 5 6 7 8 9 10
Frequency 2 2 2 2 2 2 2 2 2 2
Proportion 0.1 0.1 0.1 0.1 0.1 0.1 0.1 0.1 0.1 0.1
--------------------------------------------------------------------------------
Soms willen we enkele rijen van een dataframe inspecteren. Met head() krijgen we de eerste zes rijen.
head(sleep)
extra group ID
1 0.7 1 1
2 -1.6 1 2
3 -0.2 1 3
4 -1.2 1 4
5 -0.1 1 5
6 3.4 1 6
Met tail() de laatste zes rijen.
tail(sleep)
extra group ID
15 -0.1 2 5
16 4.4 2 6
17 5.5 2 7
18 1.6 2 8
19 4.6 2 9
20 3.4 2 10
3.6 Data selecteren uit een dataframe
Om data uit een dataframe te selecteren kunnen we werken via indexering (de vierkante haakjes). Tussen de haakjes staat nu een komma om rijen en kolommen te onderscheiden.
De eerste vier rijen uit sleep:
sleep[1:4,]
extra group ID
1 0.7 1 1
2 -1.6 1 2
3 -0.2 1 3
4 -1.2 1 4
Alle observaties (rijen) waarvoor geldt dat er meer dan 0 uur extra geslapen werd.
Een andere manier om data te selecteren is via de subset() functie. Hier nemen maken we een nieuwe dataframe sleep_control waarvoor de eerste groep uit de sleep data halen.
extra group ID
Min. :-1.600 1:10 1 :1
1st Qu.:-0.175 2 :1
Median : 0.350 3 :1
Mean : 0.750 4 :1
3rd Qu.: 1.700 5 :1
Max. : 3.700 6 :1
(Other):4
3.7 Een nieuwe variabele toevoegen
We berekenen de z-score voor elke waarde van extra en voegen die toe aan de dataset. We gebruiken het dollarteken om de variabele aan de sleep-dataset toe te voegen.
Vermijd om verschillende datasets op te slaan, maar schrijf code om data te manipuleren en te selecteren, zo zorg je ervoor dat je data-analyse repliceerbaar wordt. Wil je een dataset toch opslaan, bvb. als een .csv-bestand met “;” als scheidsingsteken, dan gebruik je write.csv2() (2 zorgt ervoor dat “;” als scheidsingteken gebruikt wordt”.
write.csv2(df, file ="df.csv")
3.9 Functies toepassen op variabelen uit een dataframe
Om te verwijzen naar een specifieke variabele uit een dataset gebruik je het dollarteken
X is de continue variabele waarop we een functie gespecifieerd in (3) willen toepassen
2
is de categorische variabele volgens dewelke we de variabele in (1) opdelen
3
de functie die we wensen toe te passen.
1 2
0.75 2.33
3.10 Samenvatting en vooruitblik
Een dataframe is een R-object dat een dataset weergeeft. Een dataset wordt in de meeste gevallen gecreëerd buiten R en nadien als tekstbestand (.csv of .txt) geïmporteerd in R. Data importeren is een bekende frustratie wanneer je R voor de eerste keren gebruikt. De gemakkelijkste manier om een dataset in te laden is via de RStudiofunctie import data. Het is belangrijk dat je gemakkelijk je weg vind binnen een dataframe, dat je gemakkelijk de variabelen kunt analyseren en stukken uit de dataframe kunt opvragen. In het volgende hoofdstuk zul je zien hoe je dat kunt doen met behulp van tidyverse, wat in veel handboeken de standaardmethode geworden is om data te bevragen, te manipuleren en te transformeren.
3.11 Terminologie
Een overzicht van de functies die we in dit hoofdstuk gebruikt hebben in de context van een dataframe:
gl()
View()
str()
names()
getwd()
setwd()
read.csv()
dim()
summary()
head()
tail()
subset()
droplevels()
write.csv2()
DATAFRAME$VARIABELE
tapply()
De Latte, Fien. 2023. “Replication Data for: (Im)polite Uses of Vocatives in Present-Day Madrilenian Spanish.” DataverseNO. https://doi.org/10.18710/FOBMUQ.