9 De t-test
Bij een statistische data-analyse wensen we een besluit te nemen over een populatie op basis van een steekproef. We onderscheiden twee vormen van statistische inferentie:
- Schatten (Puntschatten en Intervalschatten)
- Testen (is er een verschil/effect/associatie/correlatie?)
In dit hoofdstuk bekijken we het stappenplan voor een statistische toets (of significantietoets) aan de hand van de t-test. Dit stappenplan verloopt als volgt:
- Formuleer de nul- en alternatieve hypotheses
- Kies het significantieniveau/beslissingsregel (doorgaans \(5\%\))
- Kies een test op basis van de onderzoeksvraag en de data
- Voer de test uit en verwerp of aanvaard de nulhypothese en verwerp of aanvaard de alternatieve hypothese volgens de beslissingsregel
- Interpreteer de resultaten in de context van de onderzoeksvraag
9.0.0.1 Voorbeeld
Stel dat we wensen na te gaan of de gemiddelde Engelse (receptieve) woordenschat van leerlingen in het eerste middelbaar is veranderd tussen het jaar 2000 en het jaar 2020. Misschien verwachten we een toename of afname. Of we wensen daarover geen standpunt in te nemen en willen gewoon weten of de woordenschatkennis veranderd is.
We gaan er gemakshalve van uit dat de studie in de allerbeste omstandigheden werd uitgevoerd. We beschikken dus over aselecte steekproeven, de woordenschattest is zowel valide als betrouwbaar en de test werd afgelegd in optimale condities. Kortom, we beschikken over kwaliteitsvolle data.
We bekijken in dit hoofdstuk vier testen uit de t-testfamilie.
- de t-test voor twee gemiddelden (gelijke variantie)
- de Welch t-test voor twee gemiddelden (ongelijke variantie)
- de t-test voor één gemiddelde
- de gepaarde t-test
We zullen zien dat de manier van testen analoog verloopt, maar dat ze een antwoord bieden op een verschillende vraagstelling. We starten met de t-test voor twee gemiddelden en volgen het stappenplan.
9.1 Nul- en alternatieve hypothese
Alvorens we een test uitvoeren, formuleren we twee hypotheses:
- de nulhypothese (\(H_0\))
- de alternatieve hypothese (\(H_A\))
De nulhypothese stelt dat er geen verschil of geen effect is. De nulhypothese is doorgaans het omgekeerde van wat je eigenlijk hoopt te vinden, namelijk dat er wél een verschil is of een effect. De alternatieve hypothese is meestal datgene wat we verwachten als antwoord op een onderzoeksvraag (mocht je geen verschil verwachten, dan zou je allicht ook geen onderzoek opstarten om na te gaan of er een verschil is).
In de context van ons onderzoek naar het verschil in woordenschatkennis tussen \(2000\) en \(2020\) formuleren we de hypotheses als volgt:
- \(H_0\): \(\mu_{2000}=\mu_{2020}\)
- \(H_A\): \(\mu_{2000}\neq\mu_{2020}\)
We zouden ook twee specifiekere alternatieve hypotheses kunnen formuleren waarin we wel een richting verwachten:
- \(H_A\): \(\mu_{2000}>\mu_{2020}\)
- \(H_A\): \(\mu_{2000}<\mu_{2020}\)
Wanneer we geen richting in het verschil verwachten (\(\neq\)), spreken we van een tweezijdige test. Wanneer we wel een richting verwachten (\(<\) of \(>\)), spreken we van een eenzijdige test. Tenzij er goeie theoretische of empirische aanwijzingen zijn om een bepaalde richting te verwachten, is het altijd beter om tweezijdig te testen.
Merk op dat de hypotheses geformuleerd worden in relatie tot de populatieparameter \(\mu\). We wensen immers een uitspraak te doen over de populatie(s) op basis van de steekproeven die we onderzoeken.
9.2 Het significantieniveau
Het significantieniveau \(\alpha\) is een cumulatieve proportie die we op voorhand bepalen (keer terug naar Hoofdstuk 7 indien je niet meer weet wat een cumulatieve proportie is). Doorgaans wordt het significantieniveau vastgelegd op \(5\%\). Een P-waarde kleiner dat \(5\%\) zullen we als statistisch significant beschouwen. We gaan hier in straks dieper op in, nadat we de test hebben uitgevoerd.
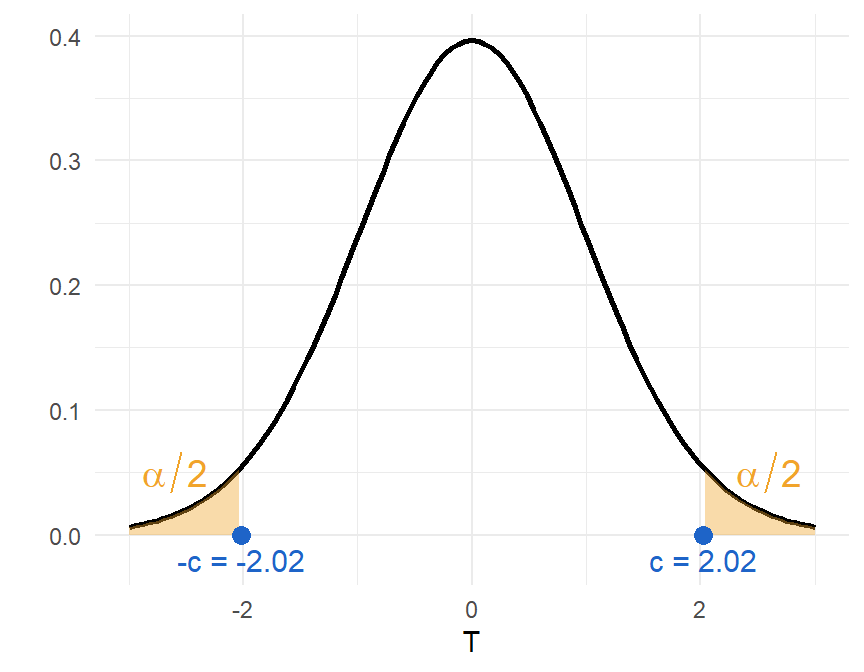
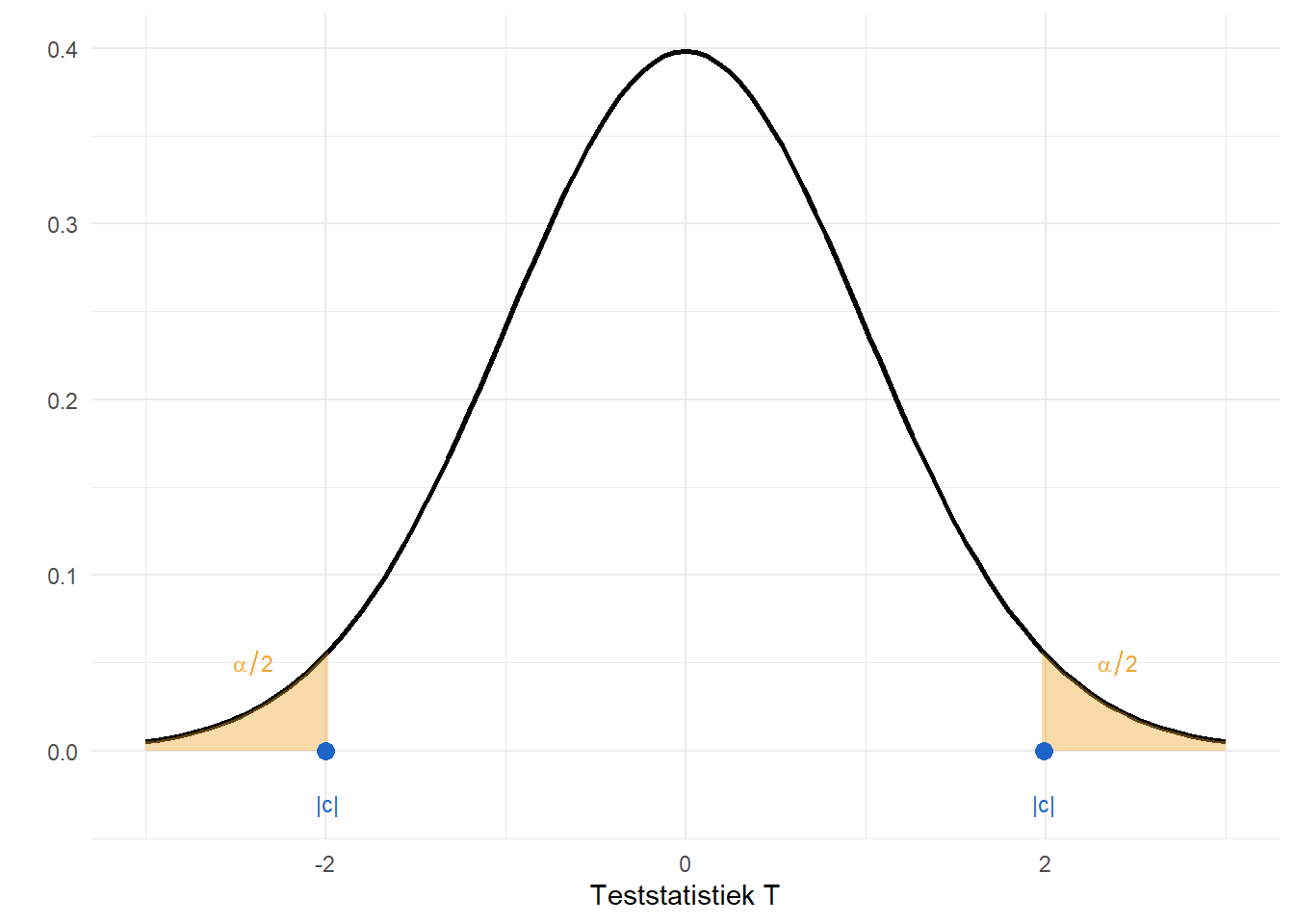
Zowel het significantieniveau \(\alpha\) als de P-waarde zijn cumulatieve proporties op een verdeling. Bij een t-test zijn dat proporties in de staarten van de t-verdeling. Die proporties zijn geassocieerd met een kritische waarde \(c\). Figure 9.1 toont de kritische waarde \(c\) en het significantieniveau \(\alpha\) voor een t-verdeling met 39 vrijheidsgraden, voor een tweezijdige test.
Als we eenzijdig testen en we verwachten een positief verschil, dan is \(\alpha\) volledig te vinden in de rechterstaart, zoals aangeduid in Figure 9.2. De kritische waarde \(c\) voor een \(5\%\) significantieniveau op een t-verdeling met 39 vrijheidsgraden is dan gelijk aan \(1.68\).
qt(p = 0.05, df = 39, lower.tail = FALSE)[1] 1.684875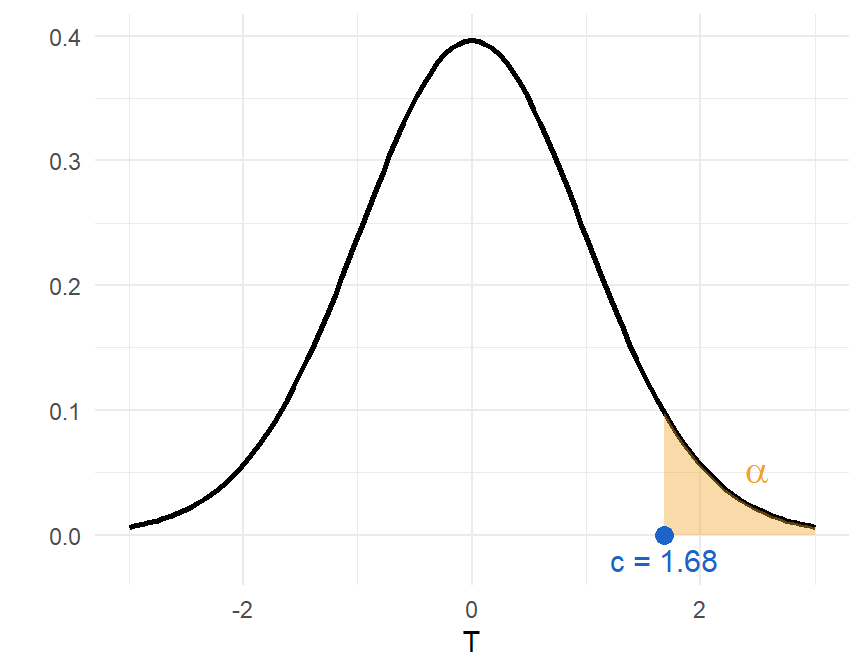
Op basis van de kritische waarde en/of het significantieniveau wordt een beslissingsregel opgesteld, de regel volgens dewelke we een beslissing nemen over de nul- en alternatieve hypothese op basis van de statistische test:
- we verwerpen de nulhypothese en aanvaarden de alternatieve hypothese als de teststatistiek (de uitkomst van de statistische test, zoals toegelicht in de volgende paragraaf) groter is dan de kritische waarde.
of:
- we verwerpen de nulhypothese en aanvaarden de alternatieve hypothese als de P-waarde kleiner is dat het significantieniveau.
Maar nu moeten we nog weten hoe we tot de teststatistiek en de P-waarde komen.
9.3 De t-test voor twee populatiegemiddelden (gelijke variantie)
Om de verandering in woordenschatkennis tussen \(2000\) en \(2020\) te onderzoeken, vergelijken we het verschil tussen twee steekproefgemiddeldes. De test die we daarvoor kunnen gebruiken is de t-test, ook wel de t-test voor twee populatiegemiddelden genoemd. In het Engels spreekt men ook over de “two sample t-test” of de “independent samples t-test”.
Op basis van twee metingen beschikken we dus over twee steekproeven die (mogelijks) uit twee verschillende populaties komen:
| Populatie | Parameters | Steekproef | Schatters |
|---|---|---|---|
| 1 | \(\mu_1,\sigma_1\) | 1 | \(\bar{X}_1,s_1\) |
| 2 | \(\mu_2,\sigma_2\) | 2 | \(\bar{X}_2,s_2\) |
We gaan er bovendien vanuit dat:
- de observaties uit de twee steekproeven onafhankelijk van elkaar (zowel tussen als binnen de twee steekproeven) tot stand zijn gekomen.
- de twee populaties normaal verdeeld zijn.
- de varianties van beide populaties gelijk zijn.
We noemen dit de assumpties van de test. Dit zijn voorwaarden waaraan de data moet voldoen om tot een betrouwbaar resultaat te komen. Het aantal observaties in beide steekproeven hoeft niet noodzakelijk gelijk te zijn. Een minimum aantal van 20 à 30 observaties per steekproef is gewenst, omdat bij kleinere aantallen de assumpties moeilijk te controleren en/of gemakkelijker geschonden worden. Bij grotere aantallen dan 30 per groep, mogen de assumpties van normaliteit en homoscedasticiteit ook tot op zekere hoogte geschonden worden. De test is immers robuust genoeg om toch tot een betrouwbaar resultaat te komen.
Om na te gaan of twee populatiegemiddeldes gelijk zijn, berekenen we de teststatistiek of toetsingsgrootheid T:
\[ T=\frac{(\bar{X_1}-\bar{X_2})-(\mu_1-\mu_2)}{s_p\sqrt{\frac{1}{n_1}+\frac{1}{n_2}}}\sim t_{n_1+n_2-2} \tag{9.1}\]
Laten we de verschillende elementen in deze vergelijking afzonderlijk bekijken om te begrijpen wat er gebeurt.
In de teller wordt het verschil tussen de steekproefgemiddeldes vergeleken met het verschil tussen de twe populatiegemiddeldes onder de nulhypothese. Wat is het verschil tussen de twee populatiegemiddeldes onder de nulhypothese? We verwachten dat er geen verschil is. Met andere woorden, en zoals we zien in Equation 9.2, het verwachte verschil is \(0\).
\[ \begin{split} \mu_{2000}&=\mu_{2020}\\ \mu_{2000}-\mu_{2020}&=0 \end{split} \tag{9.2}\]
In de teller wordt het verschil tussen de twee steekproefgemiddeldes dus vergeleken met nul: \((\bar{X_1}-\bar{X_2})-(\mu_1-\mu_2)=(\bar{X_1}-\bar{X_2})-0\).
En we delen dit verschil door een gepoolde schatter voor de standard error voor de steekproevenverdeling van het verschil tussen twee gemiddeldes. Deze gepoolde variante wordt berekend als:
\[ s^2_p=\frac{(n_1-1)s^2_1+(n_2-1)s^2_2}{n_1+n_2-2} \tag{9.3}\]
De t-test vergelijkt dus het geobserveerde verschil tussen twee steekproefgemiddeldes met een verwacht verschil tussen twee populatiegemiddeldes (onder \(H_0\) verwachten we dat dit verschil \(0\) is) in vergelijking met de SE van de steekproevenverdeling van het verschil in gemiddeldes.
We kunnen Equation 9.1 dan ook in woorden herschrijven als:
\[ \frac{\text{geobserveerd verschil}-\text{verwacht verschil}}{\text{SE}} \tag{9.4}\]
De SE impliceert dat er rekening gehouden wordt met variabiliteit in de data.
Herinner je de vraag: wat zou er gebeuren als we de test meerdere keren zouden herhalen? De teststatistiek is een gestandaardiseerde steekproevenverdeling van het verschil tussen twee gemiddeldes. Vergelijk Equation 9.1 met de z-score in Equation 9.5 en met de gestandaardiseerde vorm van de steekproevenverdeling van het gemiddelde (met een schatter \(s\) voor \(\sigma\)
\[ \begin{split} \frac{x_i-\mu}{\sigma}&\sim N(0,1)\\ \frac{\bar{X}-\mu}{\frac{s}{\sqrt{n}}}&\sim t_{n-1} \end{split} \tag{9.5}\]
Een t-test voor twee gemiddelden biedt een antwoord op de vraag: hoe ver ligt het verschilt het geobserveerde verschil tussen twee steekproefgemiddelden van het verwachte verschil \(0\), in termen van de SE voor het verschil in gemiddelden. Dit is exact analoog aan de z-score!
De bekomen teststatistiek is een waarde voor een variabele met een t-verdeling. Om te beoordelen of deze waarde speciaal is of statistisch significant, bekijken we de proportie aan waarden die nog groter is dan de geobserveerde waarde. Deze proportie is de P-waarde.
Laten we even de test uitvoeren met een fictieve dataset om te begrijpen wat de teststatistiek is en hoe we alles moeten interpreteren.
9.3.0.1 Voorbeeld
We simuleren de mogelijke scores van twee groepen (het jaar 2000 vs. het jaar 2020) op een taaltest. De testen worden gequoteerd op een totaal van \(100\). We simuleren dat de scores van beide groepen normaal verdeeld zijn met een gelijke variantie maar met een ander gemiddelde. Laten we even aannemen dat de groep uit \(2020\) een grotere gemiddelde receptieve woordenschat heeft dat de groep uit \(2000\).
We gaan uit van twee populaties (\(2000\) vs. \(2020\)) met de volgende parameters:
- 2020: \(\mu=66\), \(\sigma=10\)
- 2000: \(\mu=58\), \(\sigma=14\)
We creëren een dataset met \(N=120\) observaties, met \(60\) observaties voor elke groep.
set.seed(12) # om dezelfde steekproef te krijgen
Groep <- as.factor(c(rep("2020", 60),
rep("2000", 60)))
Score <- c(rnorm(n = 60, mean = 66, sd = 16),
rnorm(n = 60, mean = 60, sd = 16))
Test <- data.frame(Groep, Score)Enkele samenvattende waarden:
Test |> group_by(Groep) |>
summarise(Mean = round(mean(Score), 2),
VAR = round(var(Score), 2),
SD = round(sd(Score), 2))# A tibble: 2 × 4
Groep Mean VAR SD
<fct> <dbl> <dbl> <dbl>
1 2000 61.5 197. 14.0
2 2020 64.4 197. 14.0We visualiseren beide steekproeven in Figure 9.3.
ggplot(Test, aes(x = Score, fill = Groep)) +
geom_density(alpha = 0.6) +
scale_fill_manual(values=c("#1E64C8", "#F1A42B")) +
theme_minimal()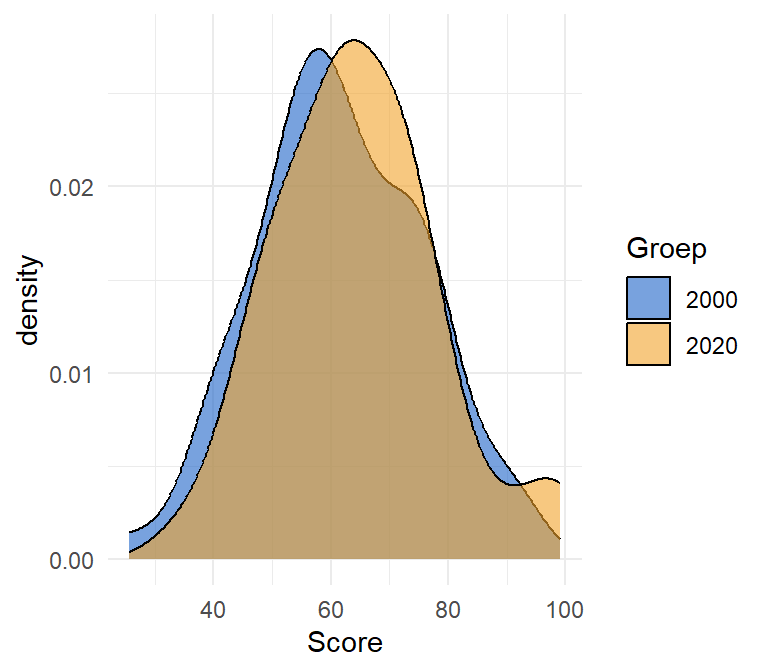
Merk op hoe het centrum van de verdelingen verschoven is. Het gemiddelde van 2020 ligt iets hoger dan het gemiddelde in 2000. Is dit kleine verschil statistisch significant? Om op die vraag te antwoorden voeren we een t-test uit. In R gebruiken we daarvoor de t.test() functie:
- 1
- We testen Score per Groep. Dit is de formulenotatie (cf. de tilde)
- 2
- de dataframe die we gebruiken
- 3
- we testen tweezijdig
- 4
- we gaan uit van gelijke varianties. De default in R is hiervoor FALSE
Two Sample t-test
data: Score by Groep
t = -1.1357, df = 118, p-value = 0.2584
alternative hypothesis: true difference in means between group 2000 and group 2020 is not equal to 0
95 percent confidence interval:
-7.982992 2.163870
sample estimates:
mean in group 2000 mean in group 2020
61.52997 64.43953 We overlopen alle elementen in de R-output:
- We zien eerst en vooral dat we het resultaat krijgen voor een “Two Sample t-test”. Dat wilden we inderdaad uitvoeren.
- De data die we hebben geanalyseerd is Score in functie van Groep (de dataset “Test” wordt zelf niet vernoemd.
- vervolgens krijgen we de resultaten van de statistische test:
- “t” is de teststatistiek, de uitkomst van onze statistische test. Laten
- “df” is het aantal vrijheidsgraden, d.i. \(n_1+n_2-2=60+60-2=118\)
- “P-value” is de P-waarde. Als deze proportie kleiner is dan het significantieniveau \(\alpha\) van \(5\%\) dan is de test statistisch significant. Dat is hier niet het geval. De test is dus niet statistisch significant op het \(5\%\) significantieniveau. We aanvaarden de nulhypothese dat er geen verschil is tussen de twee populatiegemiddeldes.
- We krijgen verder ook nog het \(95\%\) BI voor het verschil tussen de populatiegemiddeldes en de twee steekproefgemiddeldes. Het verschil tussen de twee steekproefgemiddeldes wordt niet vermeld, maar kunnen we eventueel zelf berekenen of opvragen.
Laten we even de t-test zelf berekenen door Equation 9.6 in te vullen. We kennen al de twee steekproefgemiddeldes (cf. R-output hierboven met de samenvattende waarden) en het verwachte verschil tussen de twee populatiegemiddeldes (wat \(0\) is en dus wegvalt). De standard error in de noemer kunnen we opvragen:
tt <- t.test(Score ~ Groep,
data = Test,
alternative = "two.sided",
var.equal = TRUE)
tt$stderr[1] 2.561986We pluggen alles in:
\[ \begin{split} t&=\frac{(\bar{X}_{2020}-\bar{X}_{2000})-(\mu_1-\mu_2)}{s_p\sqrt{\frac{1}{n_1}+\frac{1}{n_2}}}\\&=\frac{(64.43-61.52)-0}{2.56}\\ &=1.13 \end{split} \tag{9.6}\]
We krijgen een positief getal (in tegenstelling tot in de R-output die ons een negatieve uitkomst gaf) omdat ik bewust het hoogste gemiddelde eerst geplaatst heb. We testen echter tweezijdig, de teststatistiek \(|t|\) is dus |1.13|.
De P-waarde is de proportie groter dan deze teststatistiek, op een t-verdeling met 118 vrijheidsgraden:
- 1
-
q= de waarde die we evalueren - 2
-
df= het aantal vrijheidsgraden - 3
- we wensen de proportie groter dan \(1.13\), dus de “upper tail” (naar rechts) en we vermenigvuldigen met twee omdat we tweezijdig testen.
[1] 0.260768We illustreren dit testresultaat in Figure 9.4:
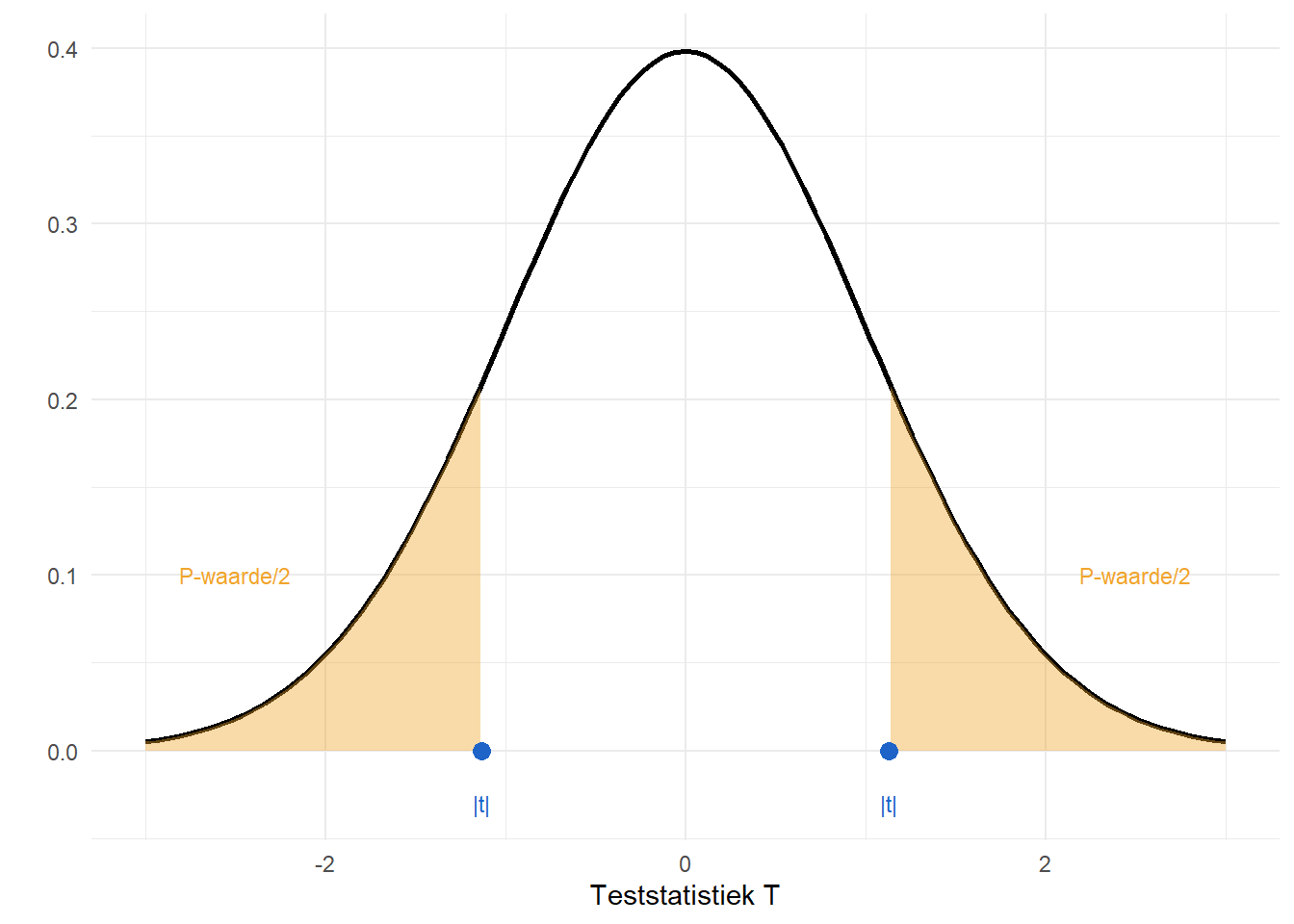
De P-waarde is de kans – onder de nulhypothese – om een teststatistiek te observeren die nog groter is dan de geobserveerde teststatistiek. De P-waarde biedt dus een antwoord op de intuïtieve vraag: hoe speciaal is dit resultaat als we ervan uitgaan dat beide populatiegemiddeldes gelijk zijn? De P-waarde is dus een proportie of een kans. Dit is analoog aan de interpretatie van de z-score in hoofdstuk 7. Vergelijk: hoe speciaal is iemand van \(210\)? Speciaal omdat de proportie van mensen groter dan \(210\;cm\) klein is.
Figure 9.4 visualiseert de teststatistiek en de P-waarde. We kunnen dit vergelijken met het \(5\%\) significantieniveau (\(\alpha\)) in Figure 9.5:
Om na te gaan of onze statistische test significant is, kunnen we op twee manieren te werk gaan:
- ofwel vergelijken we de P-waarde met \(5\%\)
- ofwel vergelijken we de teststatistiek met de kritische waarde \(c\).
De P-waarde geeft meer informatie, omdat je dan ook kunt nagaan hoe sterk het bewijs is tegen de nulhypothese; hoe lager de p-waarde, hoe sterker het bewijs tegen de nulhypothese.
9.4 Assumpties
We moeten nu nog de assumpties nagaan die het mogelijk maken om de test op een betrouwbare manier uit te voeren.
De assumptie van onafhankelijke observaties kunnen we enkel beoordelen op basis van de de manier waarop de steekproef tot stand is gekomen. Hier hebben we er zelf voor gezorgd dat we twee aselecte steekproeven hebben genomen, dus die aan die assumptie is voldaan.
De assumptie van normaliteit is ook voldaan omdat we zelf een steekproef genomen hebben uit een normale verdeling.
We kunnen die assumptie op twee manieren testen. Ten eerste door de steekproef te visualiseren en de normaliteit op zicht te beoordelen. We kunnen daarvoor een histogram maken van beide steekproeven. Figure 9.6 toont beide.
ggplot(Test, aes(x=Score)) +
geom_histogram(fill="#F1A42B", bins = 12) +
facet_grid( ~ Groep) +
theme_minimal()
ggplot(Test, aes(sample = Score)) +
stat_qq() +
stat_qq_line() +
facet_grid( ~ Groep) +
theme_minimal()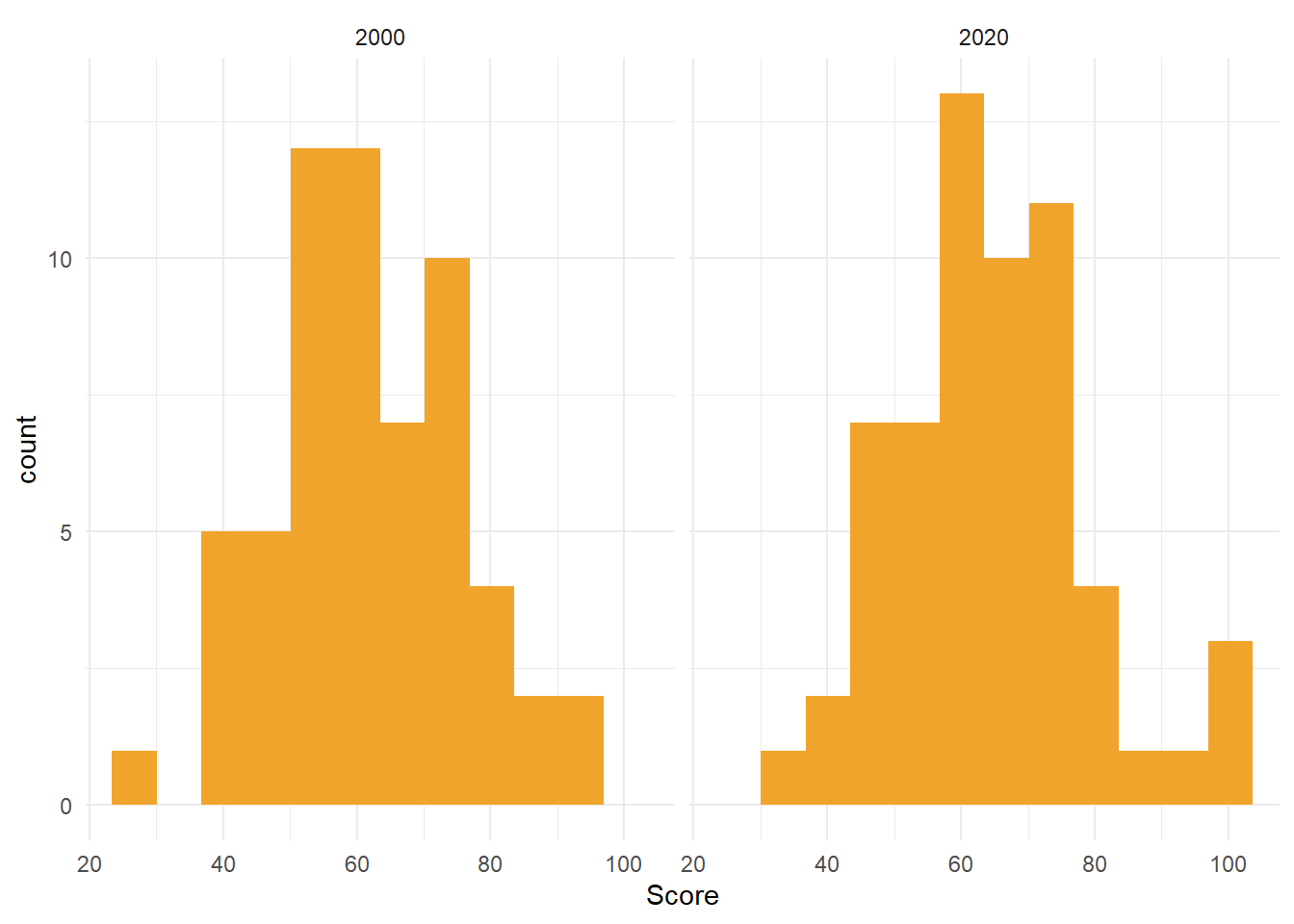
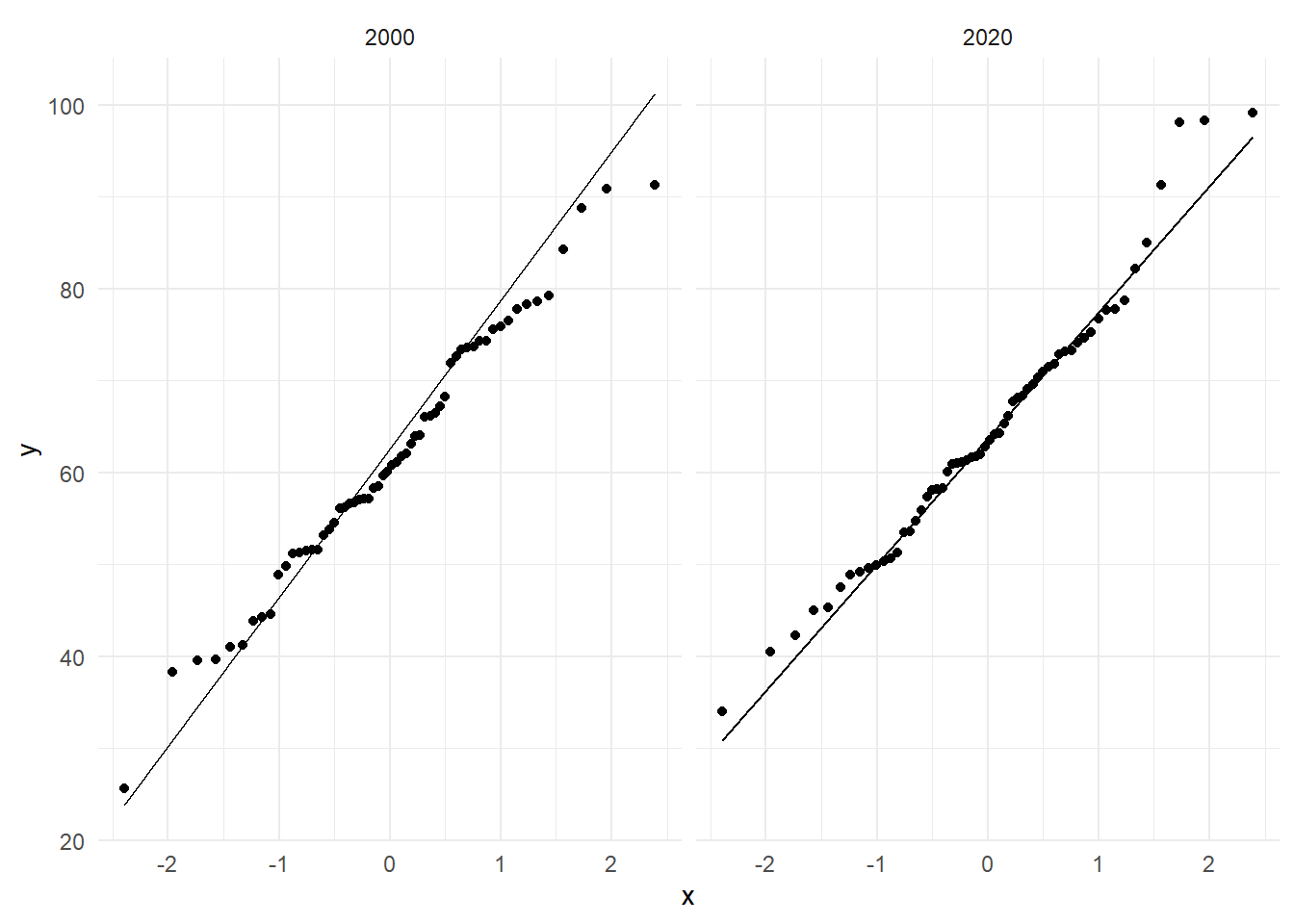
Een andere manier om normaliteit te testen is aan de hand van een statistische test. We kunnen hiervoor de Shapiro-Wilk test gebruiken. Aangezien dit een statistische test is, dienen we een nul- en alternatieve hypothese te formuleren:
- \(H_0\): De data is normaal verdeeld
- \(H_A\): De data is niet normaal verdeeld
Hier wensen we dus een niet-significant resultaat!
Om de test uit te voeren moeten we eerst twee aparte subsets maken waarbij we de scores voor de twee groepen apart hebben.
Score_2000 <- Test$Score[Test$Groep == "2000"]
Score_2020 <- Test$Score[Test$Groep == "2020"]Normaliteit 2000:
shapiro.test(Score_2000)
Shapiro-Wilk normality test
data: Score_2000
W = 0.98688, p-value = 0.7668Normaliteit 2020:
shapiro.test(Score_2020)
Shapiro-Wilk normality test
data: Score_2020
W = 0.97602, p-value = 0.2839Voor beide testen krijgen we een niet-significante P-waarde. We hebben dus geen aanwijzingen dat onze steekproeven niet uit een normale verdeling getrokken zijn.
Ten slotte testen we ook de assumptie van gelijke variantie of homoscedasticiteit. Een eenvoudige test is door gewoon de twee varianties te delen. Dit is een F-test. Hoe verder het resultaat verwijderd is van 1 hoe sterker het bewijs dat de twee varianties verschillend zijn.
We testen de hypotheses:
- \(H_0\): \(\sigma^2_{2000}=\sigma^2_{2020}\)
- \(H_A\): \(\sigma^2_{2000}\neq\sigma^2_{2020}\)
We bereken de teststatistiek.
var(Score_2000)/var(Score_2020)[1] 1.000946We hebben zonet een F-test uitgevoerd. De teststatistiek is het quotiënt van de varianties van de twee groepen:
\[ F=\frac{S^2_1}{S^2_2}\sim f_{df_1, df_2} \tag{9.7}\]
Met: \(df_1=n-1\) van de eerste groep en \(df_2=n-1\) van de tweede groep.
De hypotheses die we testen zijn:
- \(H_0\): \(\sigma^2_1 = \sigma^2_2\)
- \(H_A\): \(\sigma^2_1 \neq \sigma^2_2\)
- 1
-
qis de teststatistiek,df1is het aantal vrijheidsgraden van de eerste groep - 2
-
df2is het aantal vrijheidsgraden van de tweede groep - 3
- we vragen de rechterstaart.
[1] 0.498557De test is niet significant ($P-waarde > 0.05$). We beslissen om de nulhypothese te aanvaarden dat de twee varianties gelijk zijn.
In R kunnen we var.test() gebruiken:
var.test(Score ~ Groep, data=Test)
F test to compare two variances
data: Score by Groep
F = 1.0009, num df = 59, denom df = 59, p-value = 0.9971
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.5978897 1.6757161
sample estimates:
ratio of variances
1.000946 We kunnen ook de Levene test gebruiken (uit het car package).
library(car)Loading required package: carData
Attaching package: 'car'The following object is masked from 'package:dplyr':
recodeThe following object is masked from 'package:purrr':
someleveneTest(Score ~ Groep, data = Test) Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 1 0.0473 0.8282
118 En we komen tot hetzelfde besluit; de P-waarde is groter dan \(0.05\).
In bovenstaande output wordt de P-waarde weergegeven als “Pr(>F)”. Denk even na waarom dat ook een correcte weergave is voor de P-waarde.1
9.5 Welch t-test
Wanneer de assumptie van homoscedasticiteit geschonden is dan kan een alternatieve t-test worden uitgevoerd, met name Welch’s t-test. In dit geval volgt de verdeling van de teststatistiek T geen t-verdeling meer, maar dit kan opgevangen worden door de vrijheidsgraden anders te berekenen. In R dien je alleen het argument var.equal = FALSE aan te passen.
t.test(Score ~ Groep, data = Test,
alternative = "two.sided",
var.equal = FALSE)
Welch Two Sample t-test
data: Score by Groep
t = -1.1357, df = 118, p-value = 0.2584
alternative hypothesis: true difference in means between group 2000 and group 2020 is not equal to 0
95 percent confidence interval:
-7.982992 2.163870
sample estimates:
mean in group 2000 mean in group 2020
61.52997 64.43953 De Welch variant is de default in R. Let wel, het is niet omdat je het gemiddelde voor twee groepen met ongelijke varianties kunt vergelijken dat dat ook altijd een goed idee is. Als de verschillen tussen de varianties heel groot zijn, dan is dat misschien het belangrijkste resultaat. Om dit te beoordelen heb je achtergrondkennis nodig en niet louter statistische vaardigheden.
9.6 De t-test voor één populatiegemiddelde
We wensen een populatiegemiddelde te vergelijken met een verwachte waarde. We testen:
- \(H_0\): \(\mu=\text{verwachte waarde}\)
- \(H_A\): \(\mu\neq \text{verwachte waarde}\)
De test is analoog aan de t-test voor twee populatiegemiddelden: we gaan hoe ver het geobserveerde gemiddelde ver afwijkt van een verwachte waarde rekening houdend met de variabiliteit die we zouden krijgen mochten we meerdere steekproeven nemen.
We testen dus:
\[ \frac{\text{geobserveerd gemiddelde} - \text{verwachte waarde}}{SE} \]
De t-test voor één gemiddelde berekenen we als in Equation 9.8:
\[ T = \frac{\bar{X} – \mu}{\frac{s}{\sqrt{n}}}\sim t_{n-1} \tag{9.8}\]
T is de teststatistiek. Onder de nulhypothese volgt deze teststatistiek een t-verdeling met \(n-1\) vrijheidsgraden (met \(n\) het aantal observaties in de steekproef. Als we de standaardafwijking \(\sigma\) kennen van de populatieverdeling, dan volgt de steekproevenverdeling een normale verdeling zoals in Equation 9.9 (dit is dezelfde steekproevenverdeling die we in het vorige hoofdstuk gezien hebben!):
\[ Z = \frac{\bar{X} – \mu}{\frac{\sigma}{\sqrt{n}}}\sim N(0,1) \tag{9.9}\]
9.6.0.1 Voorbeeld
We voeren een t-test voor een gemiddelde uit aan de hand van een fictieve dataset, waarvoor we een aselecte steekproef van \(N=50\) observaties trekken uit een normale verdeling met \(\mu=30\) en \(\sigma=5\). We onderzoeken of het steekproefgemiddelde gelijk is aan \(33\) (gewoon een ander getal dat we verzinnen ter illustratie van de test - verander zelf eens het getal om te zien wat er gebeurt). We doen alsof we \(\sigma\) niet kennen en schatten deze parameter op basis van de standaardafwijking van de steekproef.
1set.seed(125)
2steekproef <- rnorm(n = 50, mean = 30, sd = 5)
3X_bar <- mean(steekproef)
4s <- sd(steekproef)
5SE <- s/sqrt(50)
6t <- (X_bar-33)/SE
t- 1
- om de steekproef repliceerbaar te maken
- 2
- we trekken een aselecte sample uit een normale verdeling met de gekozen parameters
- 3
- het steekproefgemiddelde
- 4
- de steekproefstandaardafwijking
- 5
- de standard error van de steekproevenverdeling van het gemiddelde
- 6
- de berekening van de teststatistiek t
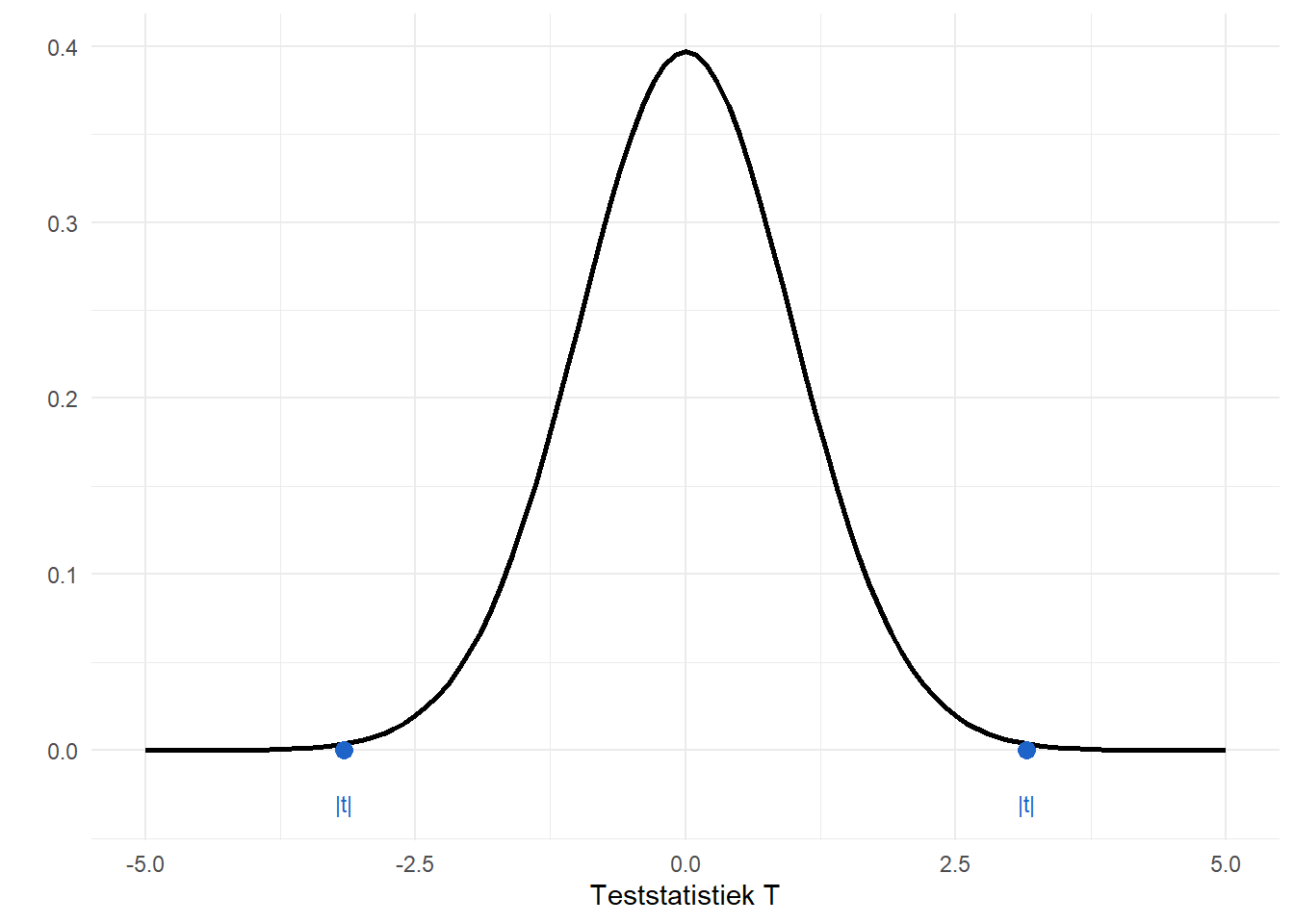
[1] -3.161957De teststatistiek \(t=-3.16\) is een waarde voor een t-verdeling met \(99\) vrijheidsgraden. We testen tweezijdig, dus hebben we eigenlijk \(|t|\). We visualiseren deze waarden en t-verdeling in Figure 9.7.
Om te bepalen of de teststatistiek significant is, bekijken we de (tweezijdige) P-waarde: de proportie onder de curve groter dan \(|t|\). Wie zich de leerstof over z-scores herinnert, hoeft de test niet uit te voeren, maar kent het antwoord zo. Maar goed, laten we toch even de P-waarde bekijken.
2*pt(q = 3.16, df = 49, lower.tail = FALSE)[1] 0.002703709De P-waarde is extreem klein en uiteraard significant. We beslissen om de nulhypothese te verwerpen en de alternatieve hypothese te aanvaarden.
We gebruiken normaal uiteraard de t.test() functie:
- 1
- de continue variabele die we wensen te testen (dus niet het steekproefgemiddelde zelf!)
- 2
- “mu” is de verwachte waarde onder de nulhypothese
- 3
- we testen tweezijdig. De twee overige alternativen zijn: “greater” of “less”.
One Sample t-test
data: steekproef
t = -3.162, df = 49, p-value = 0.002689
alternative hypothesis: true mean is not equal to 33
95 percent confidence interval:
29.22353 32.15848
sample estimates:
mean of x
30.69101 De t-test voor een populatiegemiddelde heeft normaliteit van de data als assumptie. We bekijken de qqplot:
qqnorm(steekproef, main = "")
qqline(steekproef)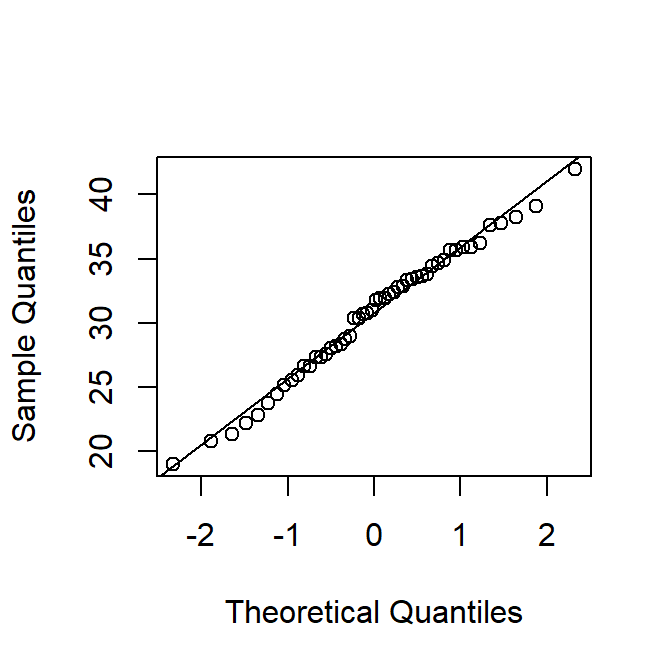
De qq-plot ziet er uitstekend uit. Ook de Shapirotest toont geen significante afwijking van normaliteit (P-waarde = 0.43).
shapiro.test(steekproef)
Shapiro-Wilk normality test
data: steekproef
W = 0.98686, p-value = 0.84769.7 De gepaarde t-test
Bij de t-test voor twee populatiegemiddelden hebben we gezien dat beide groepen onafhankelijk moesten zijn. Het kan gebeuren dat de twee groepen niet onafhankelijk zijn. Dit is bijvoorbeeld het geval wanneer dezelfde participanten op twee momenten een test afleggen. De testresultaten zijn dan geclusterd op basis van de participanten.
Om gepaarde groepen te vergelijken kunnen we de gepaarde t-test uitvoeren. We analyseren ter illustratie een deel van (Baten, Van Hiel, and De Cuypere 2021), een dataset met pre- en een posttestscores. De dataset bevat scores taaltesten Engels en Frans. Voor beide talen werd een productieve en receptieve woordenschattest afgenomen op twee momenten door dezelfde leerlingen. Voor beide talen en beide kennisaspecten werd dus een pre- en een posttest uitgevoerd. We analyseren hier enkel de productieve woordenschatkennis voor Engels. We selecteren eerst de data die we nodig hebben.
We openen de dataset en selecteren de variabelen.
clil <- read.csv("CLILVOC_20211106.csv",
sep=";", stringsAsFactors=TRUE)
clilprodeng <- clil[,c("ID", "Eng_Pro_Pre", "Eng_Pro_Post")]We bekijken eerst enkelen samenvattende waarden en merken onmiddellijk een algemene verbetering in de scores.
summary(clilprodeng) ID Eng_Pro_Pre Eng_Pro_Post
Min. : 3.00 Min. : 1.00 Min. : 6.00
1st Qu.: 35.50 1st Qu.: 7.00 1st Qu.:13.00
Median : 56.00 Median :12.00 Median :16.00
Mean : 57.91 Mean :11.96 Mean :16.83
3rd Qu.: 82.50 3rd Qu.:15.00 3rd Qu.:21.50
Max. :102.00 Max. :27.00 Max. :30.00 We zouden de data kunnen visualiseren met een geclusterde boxplot, zoals in Figure 9.9 (a), waarbij we opnieuw een duidelijke verbetering opmerken in de scores, maar waarbij er een belangrijk stuk informatie ontbreekt, namelijk dat dezelfde leerling twee testen afnam.
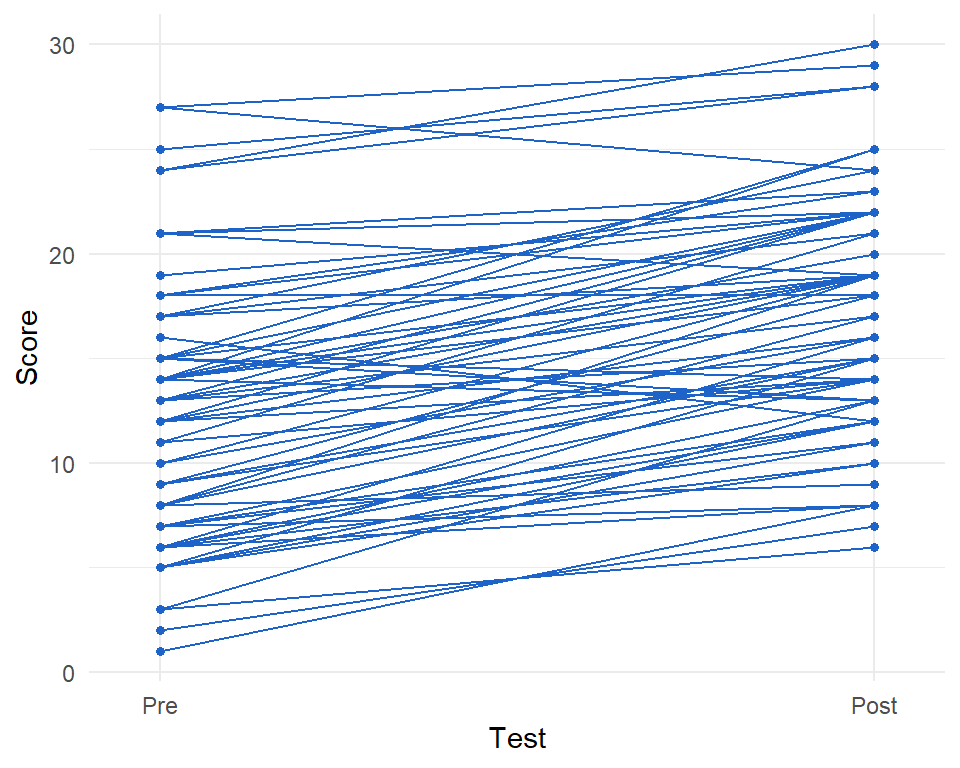
Om gepaarde data te visualiseren gebruiken we daarom beter een spaghettiplot zoals in Figure 9.9 (b), waarbij de gepaarde scores voor alle participanten zichtbaar gemaakt worden aan de hand van verbonden punten. Een stijgende lijn weerspiegelt een verbetering, een dalende een verslechtering (je zou een heel fancy plot kunnen maken waarbij grotere veranderingen in fellere kleuren worden weergegeven). We zien nu dat de scores van de meeste participanten verbeteren.
boxplot(clilprodeng$Eng_Pro_Pre,
clilprodeng$Eng_Pro_Post,
xlab = "Scores Productietest",
names=c("Pretest","Posttest"),
ylab = "Score",
las = 1,
col = "#1E64C8")
# voor een spaghettiplot moeten we de data eerst transformeren
# van wijd naar lang
prodlong <- pivot_longer(data = clilprodeng,
names_to = "Test",
values_to = "Score",
cols = 2:3)
prodlong$Test <- as.factor(prodlong$Test)
levels(prodlong$Test) <- c("Post", "Pre")
ggplot(prodlong, aes(x = reorder(Test, desc(Test)), y=Score, group=ID)) +
geom_point(colour="#1E64C8", size = 1.3) +
geom_line(colour="#1E64C8") +
scale_x_discrete(expand = c(0, 0.10)) +
xlab("Test") +
ylab("Score") +
theme_minimal()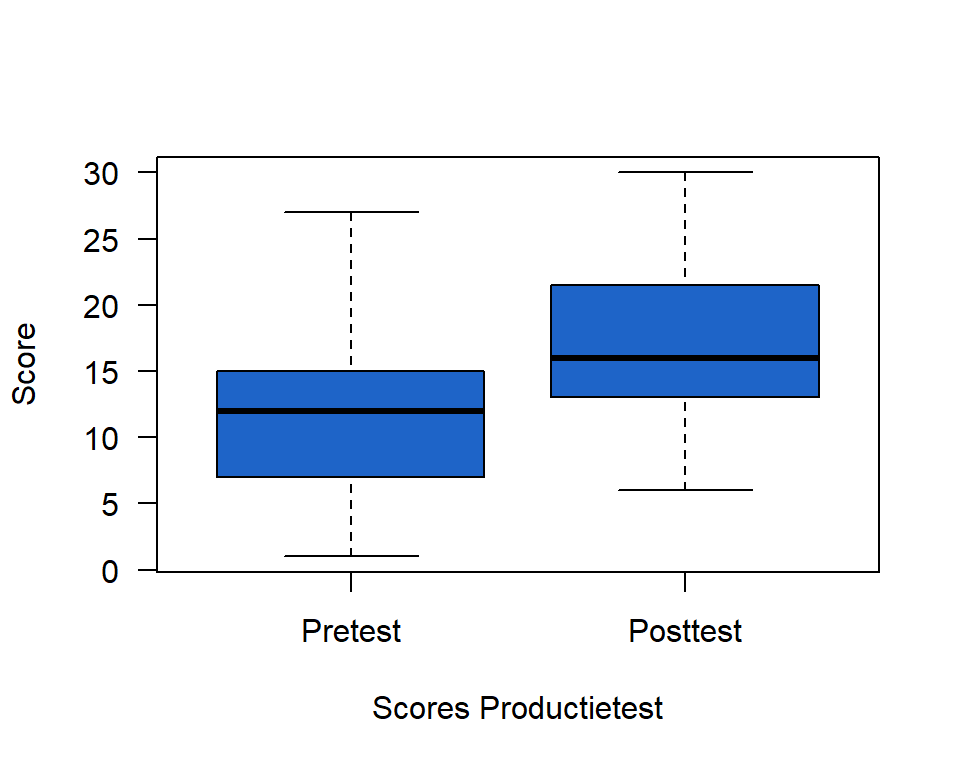
Vervolgens creëren we een nieuwe variabele waarbij we voor elke leerling het verschil tussen de Post- en de Pretest berekenen. Zo bekomen we een nieuwe variabele “clilverschil”, die we visualiseren aan de hand van een histogram in Figure 9.10.
clilprodeng$clilverschil <- clilprodeng$Eng_Pro_Post-clilprodeng$Eng_Pro_Pre
ggplot(clilprodeng, aes(x = clilverschil)) +
geom_histogram(position = "identity", bins = 12, fill="#1E64C8") +
theme_minimal() +
xlab("Verschil (Post-Pre)") +
ylab("Aantal")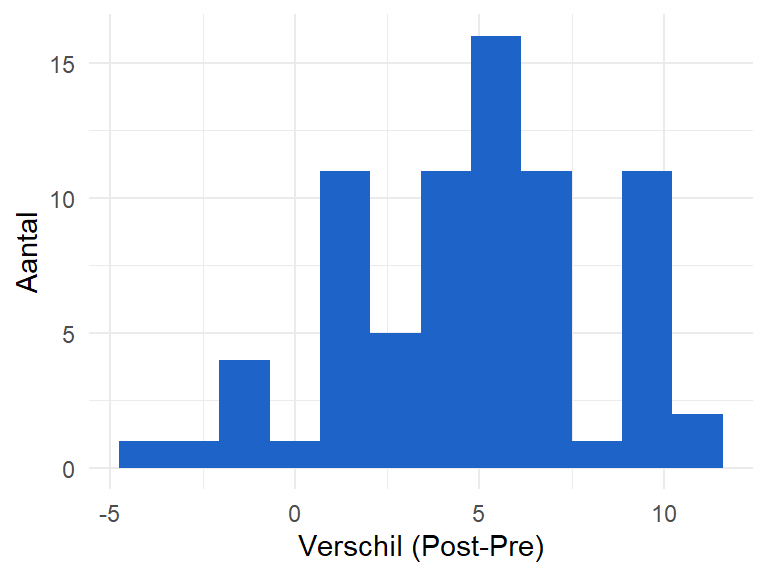
De meeste paarsgewijze verschillen zijn positief, wat nog maar eens wijst op een algemene verbetering in de scores. We maken hier dankbaar gebruik van de clustering in de data. Door de nieuwe variabele controleren we voor de interne variatie binnen de participant.
Om na te gaan of er een verandering is tussen de Pre- en Posttestscores kunnen we het gemiddelde verschil vergelijken met \(0\). Indien er een verbetering is dan verwachten we dat het gemiddelde verschil groter is dan \(0\) (met Verschil = Post - Pre).
Het verschil tussen twee normaal verdeelde variabelen \(X_1\sim\;N(\mu_1,\sigma_1^2)\) en \(X_2\sim\;N(\mu_2,\sigma_2^2)\) is een nieuwe variabele \(D\sim\;N(\delta,\sigma_D^2\), met:
\[ \begin{split} \delta&=\mu_1-\mu_2\\ \sigma_D^2&=\sigma_1^2+\sigma_2^2-2\sigma_{12}\\ \end{split} \tag{9.10}\]
Als schatter voor de populatieparameter \(\delta\) definiëren we \(\bar{D}\):
\[ \bar{D}=\frac{\displaystyle\sum_{i=1}^{n} D_i}{n} \]
De teststatistiek voor de gepaarde t-test is gedefinieerd in Equation 9.11:
\[ T = \frac{\bar{D} – \delta}{\frac{s_D}{\sqrt{n}}}\sim t_{n-1} \tag{9.11}\]
We testen de volgende nulhypothese en alternatieve hypothesen.
- \(H_0\): \(\delta=0\)
- \(H_A\): \(\delta\neq 0\) (tweezijdig), of: \(H_A\): \(\delta < 0\) (eenzijdig), of: \(H_A\): \(\delta > 0\) (eenzijdig)
We kunnen opnieuw gebruik maken van t.test() in R, met de toevoeging van het argument paired = TRUE.
t.test(clilprodeng$Eng_Pro_Post, clilprodeng$Eng_Pro_Pre,
paired = TRUE,
alternative = "two.sided")
Paired t-test
data: clilprodeng$Eng_Pro_Post and clilprodeng$Eng_Pro_Pre
t = 12.301, df = 74, p-value < 2.2e-16
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
4.078373 5.654960
sample estimates:
mean difference
4.866667 Er is een gemiddeld verschil tussen de Pre- en Posttestscores van 4.9 punten (\(95\%\) BI: \(4.1\) tot \(6.6\)). Het verschil is statistisch significant op het \(5\%\) significantieniveau (t = 12, df = 74, P-waarde < 0.001). Merk op dat we dezelfde test ook met de zogenaamde formulenotatie kunnen uitvoeren in R. Dit is handig wanneer we de data in het lange formaat hebben.
t.test(Score ~ Test, data = prodlong, paired = TRUE, alternative = "two.sided")
Paired t-test
data: Score by Test
t = 12.301, df = 74, p-value < 2.2e-16
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
4.078373 5.654960
sample estimates:
mean difference
4.866667 Merk verder op dat de gepaarde t-test gelijk is aan de t-test voor 1 populatiegemiddelde.
t.test(clilprodeng$clilverschil, mu = 0, alternative = "two.sided")
One Sample t-test
data: clilprodeng$clilverschil
t = 12.301, df = 74, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
4.078373 5.654960
sample estimates:
mean of x
4.866667 Het resultaat is exact gelijk.
9.7.1 Assumpties
Voor een betrouwbaar testresultaat moeten de data voldoen aan twee voorwaarden:
- onafhankelijkheid van de observaties (de verschillen)
- normaliteit
Onafhankelijkheid kunnen we enkel beoordelen op basis van manier waarop de data tot stand gekomen is. Als meerdere datapunten terug te brengen zijn tot één entiteit (bvb. dezelfde leerling creëerde meerdere observatie), dan is de voorwaarde van onafhankelijkheid geschonden.
We onderzoeken normaliteit aan de hand van een qqplot in Figure 9.11 en een shapiro test.
qqnorm(clilprodeng$clilverschil)
qqline(clilprodeng$clilverschil)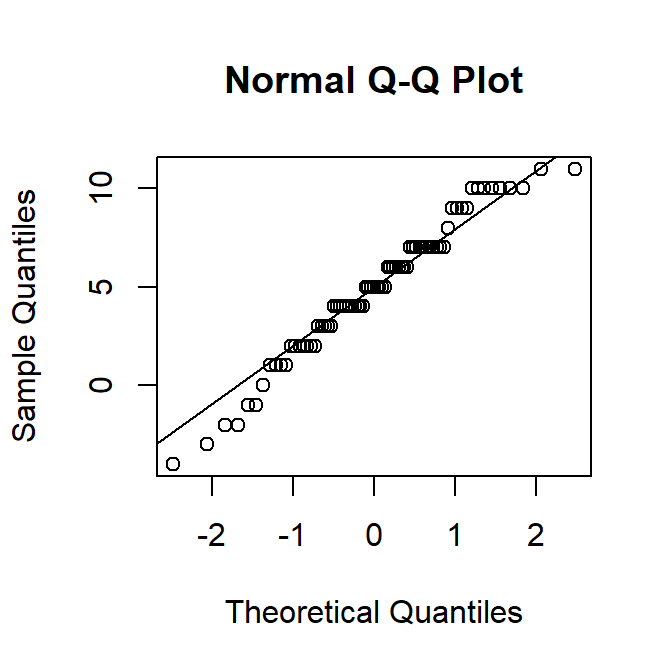
shapiro.test(clilprodeng$clilverschil)
Shapiro-Wilk normality test
data: clilprodeng$clilverschil
W = 0.97203, p-value = 0.09527We hebben op basis van de qq-plot en de statistische test geen sterke aanwijzingen tegen de hypothese dat de verschillen normaal verdeeld zijn en aanvaarden de nulhypothese dat de data normaal verdeeld zijn. (een dergelijke pedante formulering gebruik ik hier louter voor pedagogische doeleinden. In een paper hoef je dit niet op die manier te formuleren.)
9.8 Beslissingsfouten
De uitkomst van een statistische toets is steeds gebaseerd op een beslissing. We beslissen om de hypotheses te verwerpen of te aanvaarden. Maar hoe weten we of deze beslissing correct is? Correct betekent dat de beslissing de werkelijkheid weerspiegelt. Wanneer we bijvoorbeeld besluiten dat er een significant verschil is tussen twee populatiegemiddelden, klopt het dan ook dat de twee populatiegemiddelden verschillend zijn? Omgekeerd, wanneer we beslissen om de nulhypothese niet te verwerpen, klopt het dan dat er geen verschil is? Eigenlijk weten we dat niet. Een beslissing kan dus correct of fout zijn. En dit op twee manieren. Figure 9.12 geeft de mogelijkheden weer.
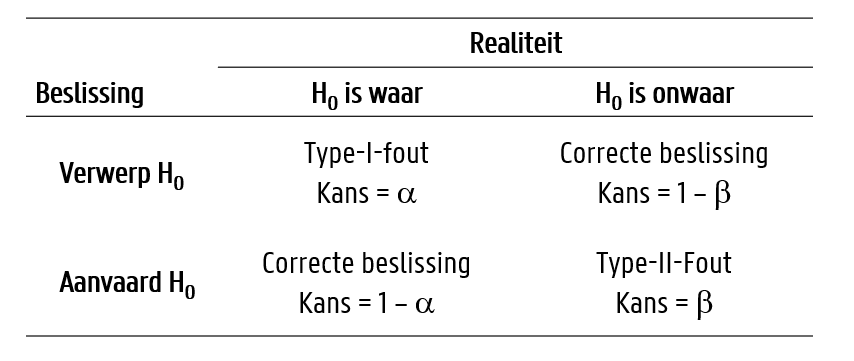
Op basis van de beslissingsmatrix onderscheiden we twee correcte en twee foutieve beslissingen.
- Correcte belissingen:
- Je beslist om \(H_0\) te aanvaarden, en in de werkelijkheid is \(H_0\) correct
- Je beslist om \(H_0\) te verwerpen, en in de werkelijkheid is \(H_0\) vals
- Foute beslissingen:
- Je beslist om \(H_0\) te verwerpen, maar in de werkelijkheid is \(H_0\) correct.
- Je beslist om \(H_0\) te aanvaarden, maar in de werkelijkheid is \(H_0\) vals.
Een correcte beslissing wordt genomen wanneer de beslissing overeenstemt met de realiteit. Er kunnen twee foute beslissingen genomen worden:
- Type-I-fout: wanneer we de nulhypothese ten onrechte verwerpen. Die fout hebben we zelf in de hand door het significantieniveau \(\alpha\) te kiezen. Een significantieniveau van \(5\%\) impliceert dat we in \(5\%\) van de testen een foutieve beslissing nemen. Hoe is dit mogelijk? Welnu, we nemen in feite aan dat de nulhypothese correct is. Wanneer we een significantieniveau kiezen, dan kiezen we zelf vanaf wanneer we beslissen om de nulhypothese te verwerpen. Maar dat is slechts een beslissing. Onwaarschijnlijke resultaten of speciale waarden zijn nog steeds mogelijk en wanneer we beslissen om een waarde als significant te beoordelen, dan betekent dit nog niet dat de nulhypothese noodzakelijkerwijze verkeerd is.
- Type-II-fout: wanneer we de nulhypothese ten onrechte aanvaarden. Dit heeft te maken met de power van de test: een slordig uitgevoerd onderzoek met weinig observaties kan niet genoeg power hebben om de nulhypothese te verwerpen. Ofwel is het werkelijke effect zó klein dat we heel veel data nodig hebben om dat kleine verschil te vinden. Er bestaan formules en methodes om de power van een statitische test te berekenen – en dit is zeker een belangrijke stap wanneer het onderzoek duur en tijdsrovend is – maar ik ga hier verder niet op in dit handboek.
Ten slotte verwijs ik ook naar Gelman & Carlin (2014), een belangrijke paper over twee andere fouten die volgens de auteurs belangrijker zijn dan de twee types die we hier bespreken.
9.9 Samenvatting en vooruitblik
We hebben een eerste statistische toets uitgevoerd om het verschil tussen twee gemiddeldes na te gaan. Het stappenplan dat we hebben gevolgd, kunnen we nu gebruiken om andere hypotheses te toetsen. We zullen telkens starten van een nul- en alternatieve hypothese, een test kiezen, uitvoeren en interpreteren in functie van de onderzoeksvraag. Bij elke test gaan we een teststatistiek bekomen, een getal op een horizontale as van een steekproevenverdeling van deze teststatistiek onder de nulhypothese. De P-waarde is de cumulatieve proportie die geassocieerd is met de teststatistiek: de kans, onder de aanname van de nulhypothese, om een teststatistiek te vinden die nog groter is dan de waargenomen teststatistiek. Met andere woorden: de P-waarde wijst aan hoe speciaal de teststatistiek is. Hoe lager de P-waarde, hoe sterker het bewijs tegen de nulhypothese. Maar let op: we nemen in feite nog steeds uit van de nulhypothese. Alleen gaan we op basis van een heel lage P-waarde beslissen dat de data niet compatibel is met de nulhypothese. Indien de P-waarde kleiner is dan \(5\%\) verwerpen we de nulhypothese en aanvaarden we de alternatieve hypothese. Dit is een beslissing, geen wetmatigheid, en die beslissing kan fout zijn. De nulhypothese ten onrechte verwerpen noemen we een type 1 fout, de nulhypothese ten onrechte aanvaarden noemen we een type 2 fout. Dit laatste kan het gevolg zijn van een slecht onderzoek: we hebben er misschien niet alles aan gedaan om een verschil te vinden. We hebben niet genoeg data gecreëerd. Het blijft een waarheid: hoe hoger de datakwaliteit, hoe gemakkelijker de data analyse.
9.10 Terminologie
- statistische inferentie
- nul- en alternatieve hypothese
- t-test voor twee gemiddeldes
- t-test voor een gemiddelde
- gepaarde t-test
- z-test
- normaliteit
- homoscedasticiteit
- eenzijdig vs. tweezijdig testen
- teststatistiek (toetsingsgrootheid)
- significantieniveau (\(\alpha\))
- significantiewaarde (P-waarde)
- kritische waarde
- beslissingsfouten: Type 1 en Type 2 fout
- power
- assumpties
Functies:
- t-test()
- var.test()
- levenTest() (uit car package)
- shapiro-test()
- qqnorm()
- qqline()
9.11 Oefeningen
- P-waarde en signicantieniveau. We voeren een statistische test uit en de P-waarde voor een signicantietoets bedraagt 0.026.
- Verwerp je de nulhypothese op een \(5\%\) signicantieniveau?
- Verwerp je de nulhypothese op een \(1\%\) signicantieniveau?
- P-waarde en signicantieniveau. We voeren een statistische test uit en de P-waarde voor een signicantietoets bedraagt bedraagt 0.074.
- Verwerp je de nulhypothese bij \(\alpha=0.05\)?
- Verwerp je de nulhypothese bij \(\alpha=0.01\)?
- P-waarde en signicantieniveau. De P-waarde voor een tweezijdige test bedraagt 0.06.
- Wat is de P-waarde voor een eenzijdige test?
- Welke extra informatie heb je nodig om over de richting van de test te beslissen?
- Significantietesten. Zijn de volgende uitspraken correct of fout. Indien fout, waarom?
- Op basis van de test verwerpen we de nulhypothese dat het steekproefgemiddelde gelijk is aan \(1500\).
- De Kolmogorov-Smirnov test suggereert dat onze data normaal verdeeld is (P = 0.46).
- Een verandering in het evaluatieproces moet leiden tot hogere tevredenheidsscores. We testen de nulhypothese dat er een verbetering is tegen de alternatieve dat er geen verandering is.
- De studie besluit dat de resultaten statistisch signicant zijn (P-waarde = 2.30045).
- Voice Onset Time. Beschouw de
VOTdataset (bron: Johnson (2008)).VOTstaat voor Voice Onset Time. Een spreker van het Cherokee produceerde in 1971 en 2001 woorden met /k/ en /t/ in anlaut. Men noteerde de VOT, dit is de tijd tussen de stemloze occlusief en de daaropvolgende vocaal. Is er een verschil tussen de gemiddelde VOT in 1971 en 2001 op een \(5\%\) signicantieniveau?- Formuleer de nul- en alternatieve hypothese.
- Welke test ga je uitvoeren om een antwoord te krijgen op de onderzoeksvraag?
- Ga de assumpties na waaraan je data moet voldoen.
- Voer de test uit in R en formuleer je besluit.
- Teken de verdeling van de teststatistiek en duid aan:
- teststatistiek
- kritische waarde voor een 5% signicantieniveau
- 5% signicantieniveau
- P-waarde
- Eenzijdig testen. Stel dat uit eerder onderzoek gebleken is dat de gemiddelde VOT in Cherokee korter geworden is. Maak gebruik van een eenzijdige test om dit na te gaan.
- Formuleer de nul- en alternatieve hypothese.
- Welke test ga je uitvoeren?
- Ga de assumpties na waaraan je data moet voldoen.
- Voer de test uit in R en formuleer je besluit.
- Teken de verdeling van de teststatistiek en duid aan:
- test statistiek
- kritische waarde voor een 5% signicantieniveau
- 5% signicantieniveau
- P-waarde
- Een gemiddelde met een verwachte waarde vergelijken. We beschikken over een opname van een tekst die ingesproken werd in het Engels. We willen nagaan of de uitspraak van de /y/ vocaal overeenkomt met wat we zouden verwachten bij een bepaald accent. We kunnen daarvoor gebruik maken van de formanten (fonetische waarden op basis waarvan taalklanken beschreven kunnen worden). We onderzoeken de eerste formant van de /y/ vocaal. We verwachten een F1 van \(235\,Hz\). In onze opname beschikken we over 25 metingen. Het gemiddelde bedraagt \(\bar{X}_{F1}=220\) en de standaardafwijking \(s=15\). Vertoont de gesproken opname het verwachte accent?
- Logaritmische transformatie. De
Ratingsdataset uit hetlanguageRpackage bevat gegevens over \(81\) Engelse woorden voor planten en dieren. Is er een verschil in de frequentie van woorden voor planten en dieren? De variabele Class is een binaire categorische variabele (‘animal’ vs. ‘plant’). Frequency is een continue variabele met de (loggetransformeerde) frequenties van de verschillende woorden. Ga na of er inderdaad een verschil is in de gemiddelde frequenties van de twee types woorden. Gebruikt de t-test om na te gaan of er een significant verschil is tussen de gemiddelde frequentie van de woorden in beide klassen.- Verken eerst de dataset met beschrijvende statistieken en visualisaties (univariaat en bivariaat)
- Formuleer de nul- en de alternatieve hypothese.
- Ga na of de veronderstellingen die je maakt bij de gebruikte toets voldaan zijn.
- Voer de test uit en formuleer je conclusie als antwoord op de onderzoeksvraag
- Gepaarde data beschrijven en visualiseren. Een onderzoeker evalueert het verschil tussen de lengte van een vocaal in 2 omgevingen (bvb. ie in piet en dier). Ze wenst in het bijzonder na te gaan of er tussen beide omgevingen een verschil is in de gemiddelde lengte van de vocaal. Table 9.1 bevat \(N=20\) metingen van een de vocaal geproduceerd door 10 Participanten (bron oefening en dataset: Butler (1985)).
- Creëer een dataframe in R in hetzelfde wijde dataformaat als de tabel.
- Geef een univariate samenvatting voor de
Lengtevan de vocaal in beideOmgevingen. - Visualiseer beide variabelen.
- Transformeer de dataframe naar het lange dataformaat. Gebruik “Omgeving” en “LengteVoc” als de namen voor de nieuwe variabelen.
- Visualiseer
LengteVocin functie van Omgeving aan de hand van overlappende histogrammen. - Visualiseer het verschil tussen de lengtes in de twee omgevingen aan de hand van een spaghettiplot.
| Participant | Omgeving 1 | Omgeving 2 |
|---|---|---|
| 1 | 22 | 26 |
| 2 | 18 | 22 |
| 3 | 26 | 27 |
| 4 | 17 | 15 |
| 5 | 19 | 24 |
| 6 | 23 | 27 |
| 7 | 15 | 17 |
| 8 | 16 | 20 |
| 9 | 19 | 17 |
| 10 | 25 | 30 |
- Gepaarde data analyseren met een gepaarde t-test. Beschouw opnieuw de
Omgevingdataset uit de vorige oefening. Gebruik een gepaarde t-test om na te gaan of er een verschil is in de Lengtes van de vocaal in beide omgevingen- Formuleer de nul- en de alternatieve hypothese.
- Ga na of het verschil tussen de Lengtes normaal verdeeld is.
- Voer de test uit en formuleer je conclusie als antwoord op de onderzoeksvraag.
- Lexicale decisie. Beschouw opnieuw de
lexdecdataset uit hetlanguageRpackage. De dataset bevat meerdere binaire categorische variabelen. Onderzoek het verschil in gemiddelde reactietijd in relatie tot een van deze categorische variabelen. Voer een volledige statistische analyse uit. Zorg voor een mooie visualisatie van de data.
Antwoord: de P-waarde is de kans onder de nulhypothese om een waarde te vinden die nog groter is dan de teststatistiek \(F\).↩︎