12 Lineaire regressie
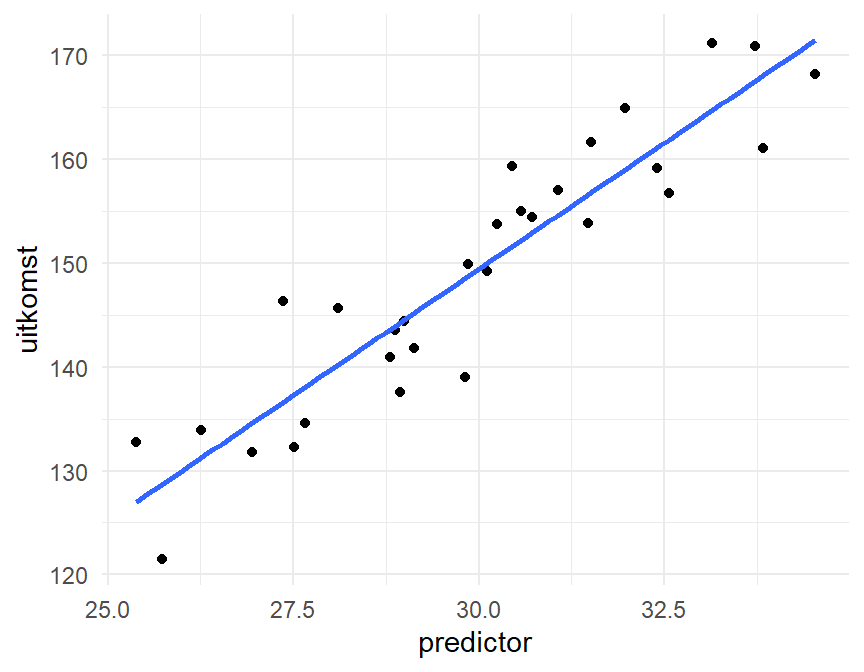
We hebben onze analyse tot nu toe beperkt tot één of twee variabelen en enkele eenvoudige basistesten zoals de t-test, de chikwadraattest en de ANOVA. In dit hoofdstuk breiden we dit uit met de regressie analyse. Deze methode laat toe om ook het effect van meerdere variabelen of predictoren te onderzoeken op een continue uitkomstvariabele, maar we beginnen met het enkelvoudig lineaire regressiemodel. Enkelvoudige regressie betekent dat we het effect van 1 continue variabele (ook wel predictor, input, of onafhankelijke variabele genoemd) op 1 andere continue variabele (ook wel uitkomst, output, of afhankelijke variabele genoemd). Lineair betekent dat we uitgaan van een rechtlijnige relatie. We gaan dus een rechte schatten op basis van een puntenwolk, zoals in Figure 12.1, die gebaseerd is op een hypothetische en gesimuleerde dataset.
Een regressie-analyse kan verschillende doelstellingen hebben:
- als een algemene beschrijving van relaties tussen variabelen (zonder causale implicaties over oorzaak-en-gevolg)
- als voorspelling van toekomstige of mogelijke observaties
- als een evaluatie van het causale effect van (een) predictor(en) op een uitkomstvariabele
De derde doelstelling is minder evident in het licht van de bekende uitspraak “correlatie is geen causatie”. Die uitspraak klopt, zeker en vast, maar causale verbanden worden tegenwoordig wel getest met complexere regressiemodellen, zoals Structural Equation Models en/of Causal Path Models. Ook met de tweede doelstelling is veel voorzichtigheid geboden: voorspellen – zeker buiten de datapunten van de predictor (bvb. in de toekomst) –, is immens veel moeilijker dan een beschrijving geven van de relatie tussen twee variabelen. In dit hoofdstuk ligt de nadruk op het louter beschrijven van de gegevens en het interpreteren en begrijpen van het enkelvoudig lineair regressiemodel. We leggen de fundamenten voor complexere regressie-analyses.
We beginnen dit hoofdstuk zoals altijd met een visualisatie van de relatie tussen twee continue variabele. We gebruiken opnieuw falsebeginners dataset. We voegen eerst een regressielijn toe en bekijken vervolgens de concepten covariantie en correlatie, die een numerieke samenvatting geven voor de lineaire relatie tussen twee continue variabelen. Vervolgens licht ik de verschillende aspecten van de regressie analyse toe: punt- en intervalschatters voor het intercept en de richtingscoeëfficiënt, de voorspelde waarden en de residuelen, de kleinste kwadratenmethode om het het model te schatten, een statistische test en een betrouwbaarheidsinterval voor de geschatte parameters van het model, het evalueren van de modelkwaliteit aan de hand van de assumpties en de verklaarde variantie (\(R^2\)).
In dit hoofdstuk heb je de volgende packages nodig:
library(tidyverse)
library(ggplot2)
library(gmodels)
library(easystats)
library(broom)
library(modelbased)
library(see)12.1 Data: Falsebeginners
We openen de data en verwijderen de rijen met ontbrekende waarden. We wensen PPVT (een variabele die de woordenschatkennis operationaliseert) te modelleren in functie van een algemene taalvaardigheidsscore die we berekenen als de som van Spreken, Luisteren, en SchrijvenLezen. We creëren de variabele Taalvaardigheid.
fb <- read.delim("Falsebeginners.txt", stringsAsFactors=TRUE) |>
na.omit(fb)
fb$Taalvaardigheid <- fb$Spreken + fb$Luisteren + fb$SchrijvenLezen12.2 Datavisualisatie
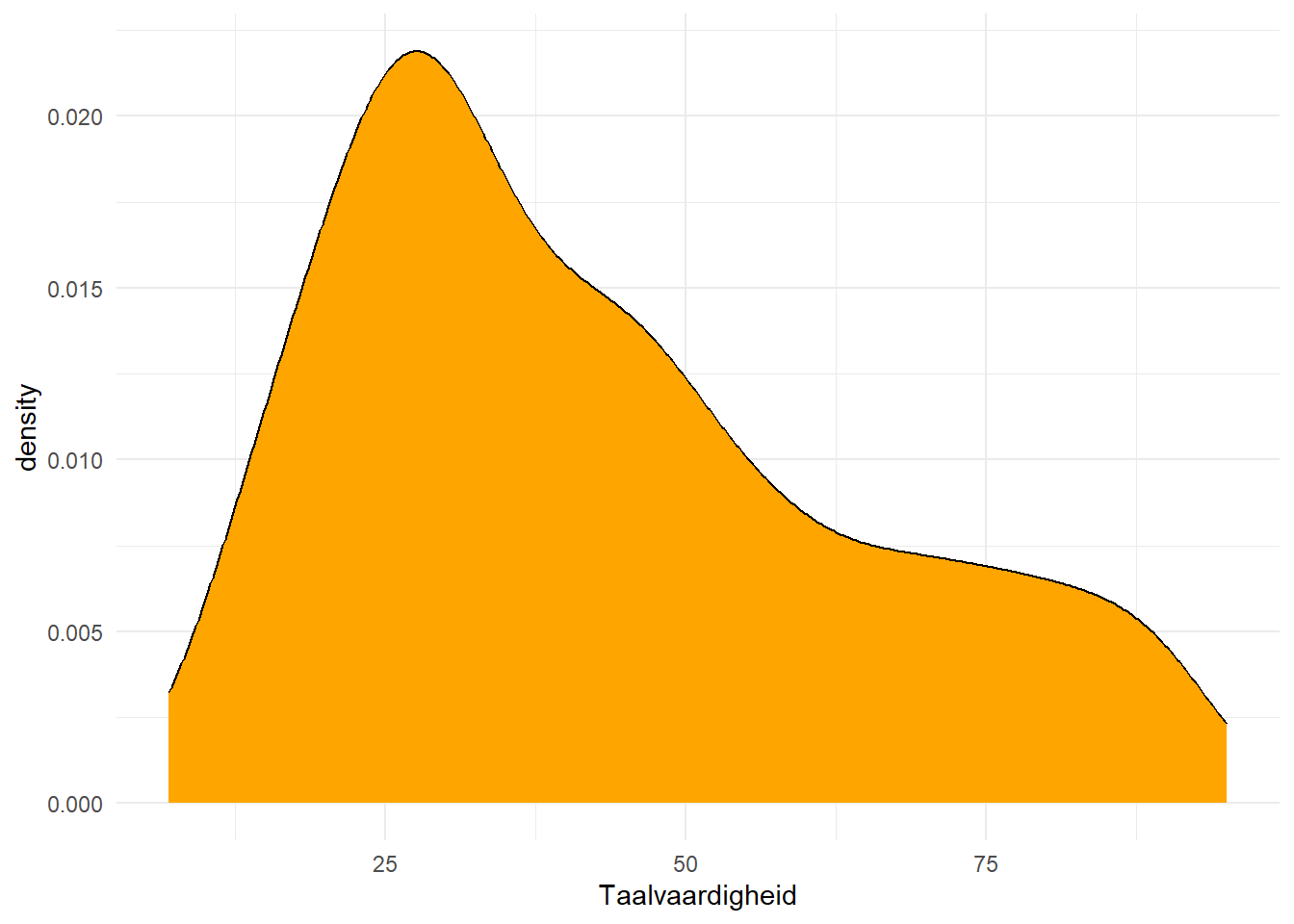
Figure 12.2 toont de verdeling van de twee variabele apart.
ggplot(fb, aes(x=PPVT)) +
geom_density(fill = "orange") +
theme_minimal()
ggplot(fb, aes(x=Taalvaardigheid)) +
geom_density(fill= "orange") +
theme_minimal()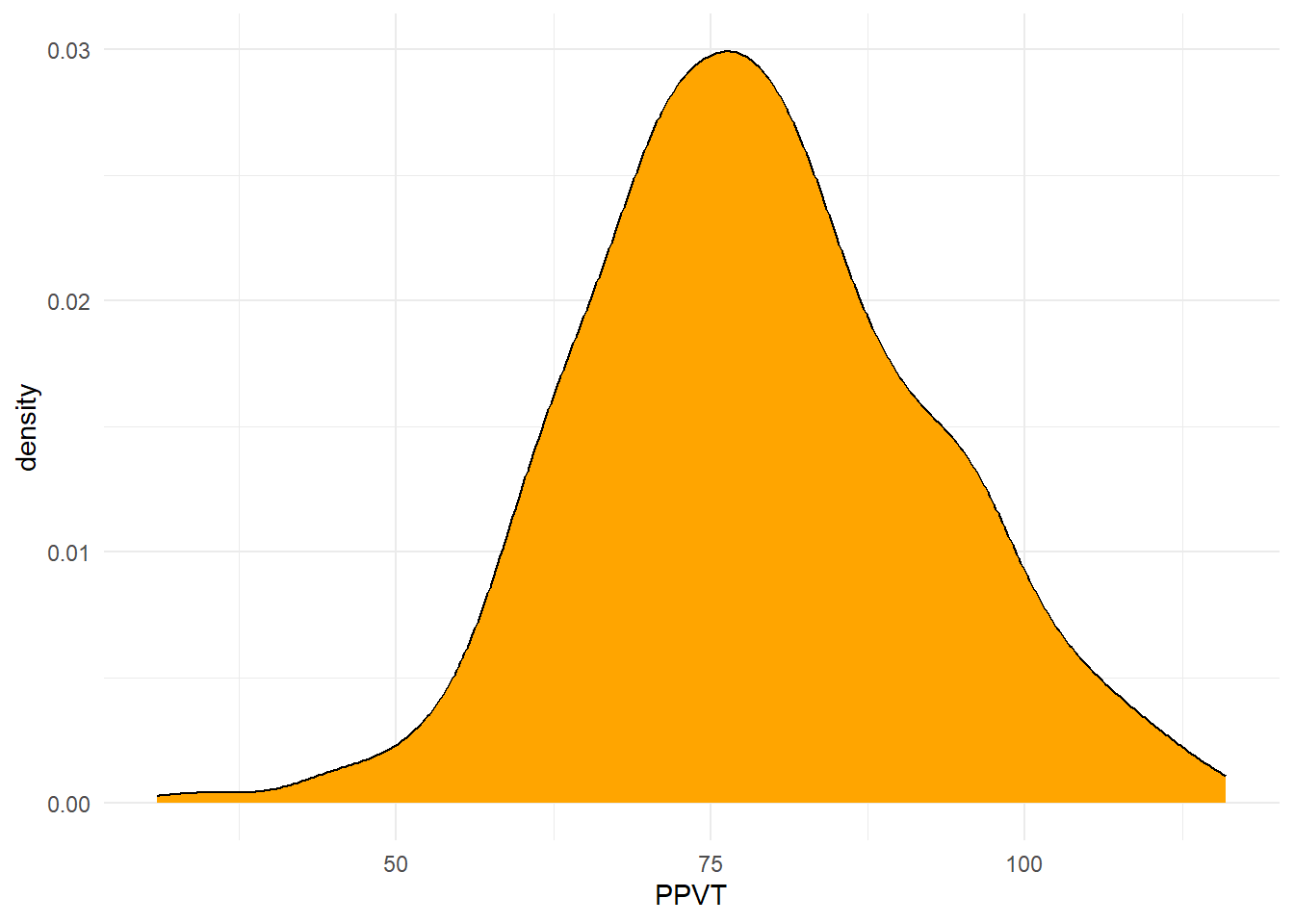
We stellen ons nu de volgende vraag:
- als we Taalvaardigheidscore kennen, kunnen we dan voorspellen wat de gemiddelde PPVT-score zal zijn?
Dit is een zeer algemene vraag waarbij het antwoord afhankelijk is van de relatie die we tussen beide variabele aannemen. Er zijn allerlei relaties mogelijk, maar we beperken ons hier tot een lineair verband, wat betekent dat we verwachten dat de relatie tussen beide variabelen weergegeven kan worden als een rechte lijn.
Als eerste stap in onze analyse van dit lineair verband kijken we naar de scatterplot in Figure 12.3, die de bivariate relatie tussen de twee variabelen weergeeft.
ggplot(fb, aes(x = Taalvaardigheid, y = PPVT)) +
geom_point(size=0.8) +
stat_smooth(method = "lm",
formula = y ~ x,
geom = "smooth",
se = FALSE) +
theme_minimal()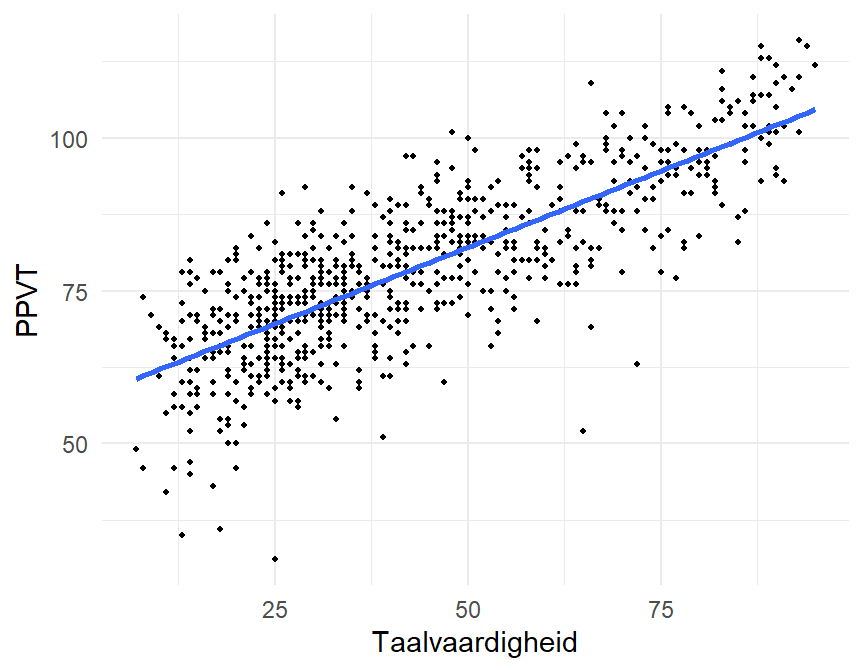
De figuur toont mooi hoe de taalvaardigheid toeneemt naarmate PPVT stijgt. Het verband lijkt ook lineair te zijn: de rechte die we aan de figuur hebben toegevoegd, lijkt de relatie tussen beide variabelen correct samen te vatten. Die rechte geeft de toename weer in de gemiddelde PPVT in functie van Taalvaardigheid. Vooraleer we de rechte schatten – het intercept en de richtingscoëfficiënt schatten –, bekijken we eerst hoe we de bivariate relatie tussen beide variabelen kunnen meten aan de hand van de covariantie en/of correlatie.
12.3 Covariantie en correlatie
Een manier om en lineair verband tussen twee variabelen samen te vatten is via de covariantie: een schatter voor de manier waarop de varianties van beide variabelen gerelateerd zijn. De steekproefcovariantie tussen twee variabelen \(X\) en \(Y\) wordt gedefinieerd door Equation 12.1:
\[ s_{XY}=\frac{1}{n-1}\sum_{i=1}^{n}(x_i-\bar{X})(y_i-\bar{Y}) \tag{12.1}\]
Deze formule is analoog aan de variantie, maar hier hebben we een product tussen twee variabelen in plaats van een kwadraat. Ter herinnering, dit is de formule voor de variantie, met twee termen voor de afwijking ten opzichte van het gemiddelde in plaats van het kwadraat om de analogie te benadrukken:
\[s^2=\frac{1}{1-n}\sum_{i=1}^{n}(x_i-\bar{X})(x_i-\bar{X})\] In R krijgen we de covariantie via cov():
cov(fb$PPVT, fb$Taalvaardigheid)[1] 233.2063We weten dat varianties moeilijk te interpreteren zijn en dat we de vierkantswortel trekken om de spreidingsmaat beter te begrijpen. Dat geldt ook voor de covariantie. We gebruiken daarom liever de correlatie, die gemeten wordt aan de hand van de correlatiecoëfficiënt in Equation 12.2:
\[ \begin{split} r_{XY}&=\frac{1}{n-1}\sum_{i=1}^{n} \left( \frac{ X_i-\bar{X}}{s_X} \right) \left( \frac{Y_i-\bar{Y}}{s_Y} \right)\\ &= \frac{s_{XY}}{s_Xs_Y} \end{split} \tag{12.2}\]
\(r\) is dus een covariantie van de gestandaardiseerde variabelen. Dit is altijd een waarde tussen \(-1\) en \(+1\), die we kunnen interpreteren zoals in Table 12.1 (in absolute waarden). Om wat feeling te krijgen voor verschillende correlatiematen kun je dit online spel spelen: https://www.guessthecorrelation.com/.
| \(r\) | Interpretatie |
|---|---|
| \(r<0.20\) | zeer zwakke correlatie |
| \(0.20<r<0.40\) | zwakke correlatie |
| \(0.40<r<0.60\) | matige correlatie |
| \(0.60<r<0.80\) | sterke correlatie |
| \(r>0.80\) | zeer sterke correlatie |
In deze steekproef bedraagt de correlatie tussen Taalvaardigheid en PPVT \(0.79\), wat wijst op een sterke positieve correlatie tussen beide variabelen.
round(cor(fb$PPVT, fb$Taalvaardigheid),2)[1] 0.79Opgepast, een correlatie gaat uit van lineaire verbanden en is niet resistent tegen outliers (met ander woorden, speciale waarden kunnen een sterk vertekenend effect hebben op de schatting van de correlatie).
Ten slotte moet ik hier voor de volledigheid nog vermelden dat de covariantie en correlatie die we hier berekend hebben, schatters zijn voor de covariantie (\(Cov\)) en correlatie (\(\rho\) ‘rho’) van de populatie. Vergeet immers niet dat we slechts twee steekproeven hebben voor de populaties waarin we geïnteresseerd zijn. Deze basisgedachte waarbij we een onderscheid maken tussen een populatie en een steekproef zal nog belangrijker blijken bij het regressiemodel.
12.4 Het enkelvoudige lineaire regressie model
Een model is een theoretisch, conceptueel of een wiskundig idee over de werkelijkheid of de ongekende populatie. Stel dat we ervan uitgaan dat er tussen PPVT en Taalvaardigheid inderdaad een enkelvoudig lineair verband bestaat, dan kunnen we dit wiskundig neerschrijven als het regressiemodel in Equation 12.3:
\[ Y=\beta_0+\beta_1X_1+\epsilon \tag{12.3}\]
- \(Y\) staat voor elke mogelijke observatie in uitkomstvariabele in de populatie
- \(\beta_i\) zijn ongekende parameters, met:
- \(\beta_0\) is het intercept van de regressierechte in de populatie.
- \(\beta_1\) is de richtingscoëfficiënt van de regressierechte in de populatie
- \(X_1\) is de naam van de predictorvariabele
- \(\epsilon\) is de term met de residuelen, het verschil tussen de gemiddeldes op de rechte en de observaties voor de uitkomstvariabele. \(\epsilon_i\) is onafhankelijk en normaal verdeeld, \(N(0,\sigma^2)\)
We kunnen dit model ook neerschrijven door de variabelen \(Y\) en \(X\) te vervangen door de namen van de variabelen:
\[ PPVT=\beta_0+\beta_1Taalvaardigheid+\epsilon \] De vergelijking zonder de term voor de residuelen \(\epsilon\) is de kern van het theoretisch model dat we willen schatten:
\[ \mu_Y=\beta_0+\beta_1X_1 \tag{12.4}\]
De gemiddelde verandering \(\mu_y\) is een “lopend” gemiddelde: een populatiegemiddelde dat verandert naarmate \(X\) verandert. Vergelijk dat met het “gewone” populatiegemiddelde \(\mu\) dat we niet kennen maar dat we kunnen schatten aan de hand van de puntschatter \(\bar{X}\). Nu willen we een populatierechte schatten op basis van een steekproefrechte.
Als we Equation 12.4 inpluggen in Equation 12.3, dan krijgen we Equation 12.5, en die vergelijking is analoog aan de vergelijking Equation 12.6, die we in hoofdstuk 7 gezien hebben.
\[ Y_i=\mu_y+e_i \tag{12.5}\]
\[ x_i=\mu+e_i \tag{12.6}\]
Het regressiemodel waarvan we aannemen dat die bestaat in de populatie kennen we niet, maar kunnen wel een steekproef creëren en op basis van de statistieken van de steekproef kunnen we de parameters van het populatiemodel schatten.
Voor de steekproef noteren we het enkelvoudig regressiemodel als in Equation 12.7.
\[ Y_i=b_0+b_1X_1+e_1 \tag{12.7}\]
De gefitte regressierechte van de steekproef is gelijk aan Equation 12.8. Het verschil met Equation 12.7 is dat er hier geen term met de residuelen staat; de gefitte rechte betreft immers de gemiddelde verandering in de steekproef.
\[ \hat{Y}=b_0+b_1X_1 \tag{12.8}\]
We vullen straks alle elementen uit deze vergelijkingen in op basis van onze schattingen in R. Eerst nog even een overzicht van de regressieparameters en hun schatters in Table 12.2.
| Parameter | Schatter |
|---|---|
| \(\beta_0\) | \(b_0\) |
| \(\beta_1\) | \(b_1\) |
| \(\sigma_{\epsilon}\) | \(S_e\) |
We nemen ook aan dat de residuelen normaal verdeeld zijn en een gelijke verdeling vertonen voor alle waarden van \(x\): \(\epsilon \sim N(\mu = 0, \sigma^2)\)
12.5 Puntschatters
We schatten \(\mu_y=\beta_0+\beta_1X_1+\epsilon\) door \(\hat{y}=b_0+b_1X_1+e\). De schatters kunnen (onder meer) als volgt berekend worden:
- \(b_1 = r\frac{s_y}{s_x}\) als schatter voor \(\beta_1\)
- \(b_0=\hat{y}-b_1\hat{x}\) als schatter voor \(\beta_0\)
- \(s^2=\frac{\sum{e_i^2}}{n-2}=\frac{\sum{y_i}-\hat{y}_i^2}{n-2}\) als schatter voor \(\sigma^2\) van \(\epsilon\).
Voor het schatten van de parameters maken we natuurlijk dankbaar gebruik van R. De brede beschikbaarheid van statistische software heeft voor een revolutie gezorgd in de statistiek en de verspreiding ervan in de andere wetenschappen, waaronder de taalwetenschap.
12.6 Het regressiemodel schatten met R
We gebruiken de lm() functie.
- 1
- verminder het aantal decimalen (voor later)
- 2
-
creëer het object “mdl” met
lm(). Let op de formulenotatie met \(\sim\) - 3
- geef een samenvatting van het regressiemodel.
Call:
lm(formula = PPVT ~ Taalvaardigheid, data = fb)
Residuals:
Min 1Q Median 3Q Max
-38.59 -5.59 0.40 5.89 20.91
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 57.0730 0.6814 83.8 <2e-16 ***
Taalvaardigheid 0.5008 0.0142 35.3 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 8.37 on 744 degrees of freedom
Multiple R-squared: 0.626, Adjusted R-squared: 0.625
F-statistic: 1.24e+03 on 1 and 744 DF, p-value: <2e-16De schatters van het regressiemodel worden gegeven onder “Estimate”:
- (Intercept) (\(=57.0730\)): het intercept, of de y-waarde voor \(Taalvaardigheid=0\)
- Taalvaardigheid (\(=0.5008\)): de richtingscoëfficiënt voor de predictor
Taalvaardigheid.
We kunnen de geschatte regressierechte – de schatting voor het regressiemodel – neerschrijven, door de schatter in te vullen in Equation 12.8.
\[ \begin{split} \hat{Y}&=b_0+b_1X_1\\ \widehat{PPVT}&=57+0.5*\text{Taalvaardigheid} \end{split} \]
12.7 Voorspelde waarden en Residuelen
Op basis van de regressierechte kunnen we voor elke waarde voor Taalvaardigheid een gemiddelde (of “gefitte” of “voorspelde”) waarde voor PPVT schatten.
Wat is bijvoorbeeld de geschatte PPVT voor een leerling met een Taalvaardigheidsscore van \(25\)?
57+0.5*25[1] 69.5En zo kunnen we voor elke Taalvaardigheidsscore de verwachte waarde berekenen:
# Taalvaardigheid = 30
57+0.5*30 [1] 72# Taalvaardigheid = 43
57+0.5*43 [1] 78.5# Taalvaardigheid = 80
57+0.5*80 [1] 97We voegen die voorspelde PPVT-waarden ter illustratie toe aan de scatterplot met regressielijn in Figure 12.4.
ggplot(fb, aes(x=Taalvaardigheid, y=PPVT)) +
geom_point(size=0.8) +
stat_smooth(method = "lm",
formula = y ~ x,
geom = "smooth", se = FALSE) +
geom_point(x = 25, y = 70, col = "#F1A42B", size = 3) +
geom_point(x = 30, y = 72.1, col = "#F1A42B", size = 3) +
geom_point(x = 43, y = 78.1, col = "#F1A42B", size = 3) +
geom_point(x = 80, y = 97, col = "#F1A42B", size = 3) +
theme_minimal() 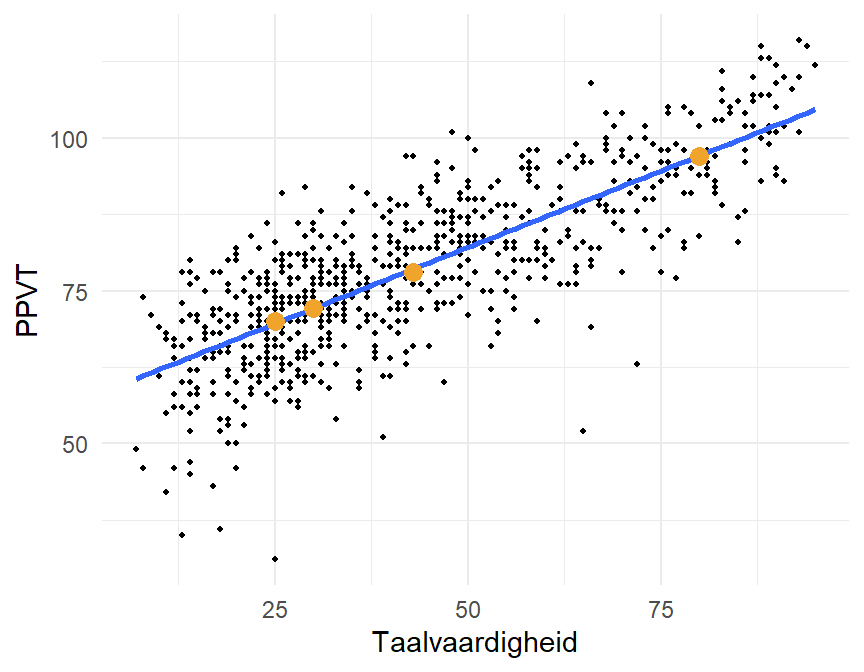
De vier voorspelde waarden liggen uiteraard op de regressielijn. Maar kijk nu naar de voorspelde waarden voor PPVT voor Taalvaardigheid gelijk aan \(25\). Veel van de werkelijk geobserveerde PPVT-scores voor deze taalvaardigheid liggen niet op de regressielijn. De geobserveerde waarden \(y_i\)) zijn verschillend van de gefitte waarde (\(\hat{y}_i\)). Dit zijn de errors of de residuelen (soms ook residuen genoemd), die we definiëren als in Equation 12.9:
\[ e_i=\hat{y}_i-y_i \tag{12.9}\]
De lm() functie creëert automatisch ook voorspelde waarden en de residuelen voor elke waarde \(x\). We bekijken de eerste \(10\) voorspelde waarden en de residuelen:
head(mdl$residuals) 1 2 3 4 5 6
0.908 2.396 0.863 -6.119 1.900 0.383 head(mdl$fitted) 1 2 3 4 5 6
69.1 76.6 97.1 86.1 74.1 84.6 Het broom package heeft functies om de output van een regressiemodel mooier (in tidyvorm) voor te stellen. De dataset kunnen we daarbij uitbreiden met voorspelde waarde (hieronder “.fitted”) en residuelen (“.resid”).
tidymdl <- augment(mdl)
head(tidymdl)# A tibble: 6 × 9
.rownames PPVT Taalvaardigheid .fitted .resid .hat .sigma .cooksd
<chr> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 70 24 69.1 0.908 0.00236 8.37 0.0000140
2 2 79 39 76.6 2.40 0.00138 8.37 0.0000569
3 3 98 80 97.1 0.863 0.00532 8.37 0.0000286
4 4 80 58 86.1 -6.12 0.00200 8.37 0.000538
5 5 76 34 74.1 1.90 0.00157 8.37 0.0000405
6 6 85 55 84.6 0.383 0.00177 8.37 0.00000186
# ℹ 1 more variable: .std.resid <dbl>We bekijken de gefitte waarde voor alle Taalvaardigheidscores gelijk aan \(25\).
tidymdl[tidymdl$Taalvaardigheid == 25 ,
c(".rownames",
"PPVT", "Taalvaardigheid",
".fitted", ".resid")]# A tibble: 22 × 5
.rownames PPVT Taalvaardigheid .fitted .resid
<chr> <int> <int> <dbl> <dbl>
1 61 31 25 69.6 -38.6
2 132 64 25 69.6 -5.59
3 144 57 25 69.6 -12.6
4 163 69 25 69.6 -0.593
5 170 64 25 69.6 -5.59
6 193 69 25 69.6 -0.593
7 208 71 25 69.6 1.41
8 215 74 25 69.6 4.41
9 276 80 25 69.6 10.4
10 378 76 25 69.6 6.41
# ℹ 12 more rowsEen van de gefitte waarden (met name .rownames = \(61\)) wijkt duidelijk af van de voorspelde waarde. Betekent dit dat het model verkeerd is of is dit een realistische waarde die we slechts 1 keer gesampled hebben? Op basis van de statistische analyse kunnen we dit eigenlijk niet weten. En daarom is steeds kennis van zaken nodig alsook replicatieonderzoek. Misschien was de steekproef gebiased in een bepaalde richting; hebben we in onze steekproef vooral leerlingen met een hoge PPVT? Ik benadruk opnieuw het belang van een correcte dataverzameling: correcte metingen op basis van aselecte steekproeven en een uitgekiend experimenteel design bepalen de kwaliteit van elke statistische analyse. Negatiever geformuleerd: “garbage in, garbage out”.
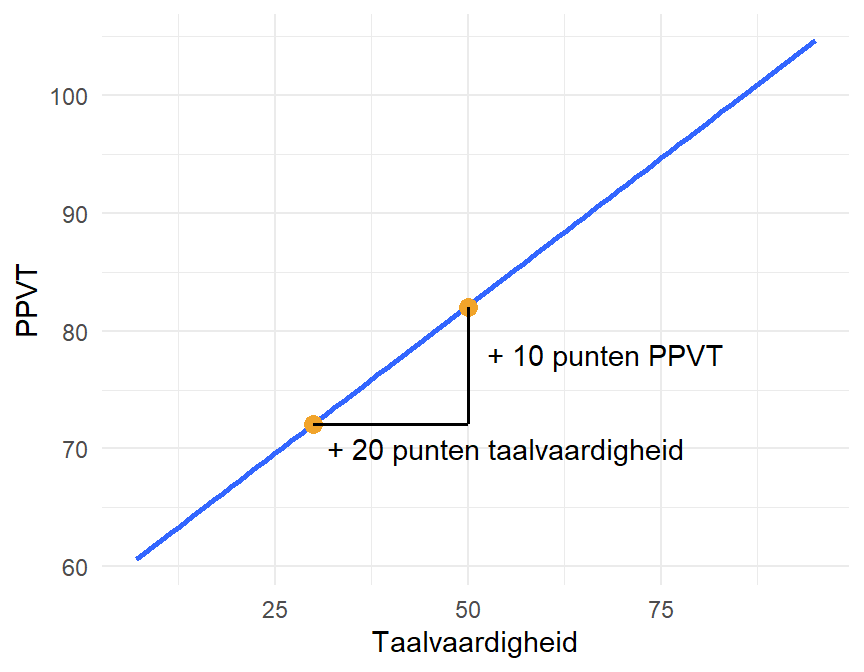
Naast het maken van een voorspelling voor elke waarde, kunnen we het regressiemodel ook gebruiken om veranderingen te voorspellen. De interpretatie van de richtingscoëfficiënt is immers dat deze term de gemiddelde verandering in \(Y\) weergeeft voor 1 eenheid toename in \(X\).
Op basis van ons model verwachten we dus dat PPVT met \(0.5\) toeneemt voor elke eenheid in Taalvaardigheid. Soms is het eenvoudiger om de verwachte verandering te transformeren door een vermenigvuldiging: als Taalvaardigheid met \(20\) eenheden toeneemt dan verwachten we een stijging van \(10\) punten voor PPVT. Figure 12.5 visualiseert deze verandering voor één punt, maar dezelfde redenering geldt voor elk punt op de x-as.
12.8 Kleinste Kwadratenmethode
De schatters geven de beste rechte, dit is de rechte die de gemiddelde verandering in \(Y\) zo correct mogelijk weergeeft op basis van een verandering in \(X\). Maar hoe weten we nu wat de “beste” recht is? En dat de schatters het beste resultaat opleveren. Dit is materie voor een fundamenteler vak over de fundamenten van de statistische inferentie, maar wat bedoeld wordt met “beste” en wat de methode is om die beste rechte te schatten, kan vrij intuïtief uitgelegd worden.
We kunnen de “beste” rechte definiëren als de rechte met de kleinste som van de residuelen. De residuelen geven de afstand weer tussen de geobserveerde waarden en de voorspelde waarden. Welnu, als we de total afstand zo klein mogelijk maken, dan hebben we de “beste” rechte, de rechte die het dichtst bij alle punten ligt.
Maar we kunnen de residuelen niet zomaar met elkaar optellen. Immers, we hebben hetzelfde probleem als bij de berekening van de variantie: als we de residuelen optellen komen we sowieso bij \(0\) uit omdat het gemiddelde in het midden ligt. We kunnen dezelfde oplossing toepassen: we tellen de kwadraten van de residuelen op en zoeken - met enige wiskundige magie die we in deze toepassingsgerichte cursus overslaan - het minimum:
\[ KKS =min \left( \sum_{i=1}^{n}(y_i-\hat{y}_i)^2 \right) \]
12.9 Statistische inferentie
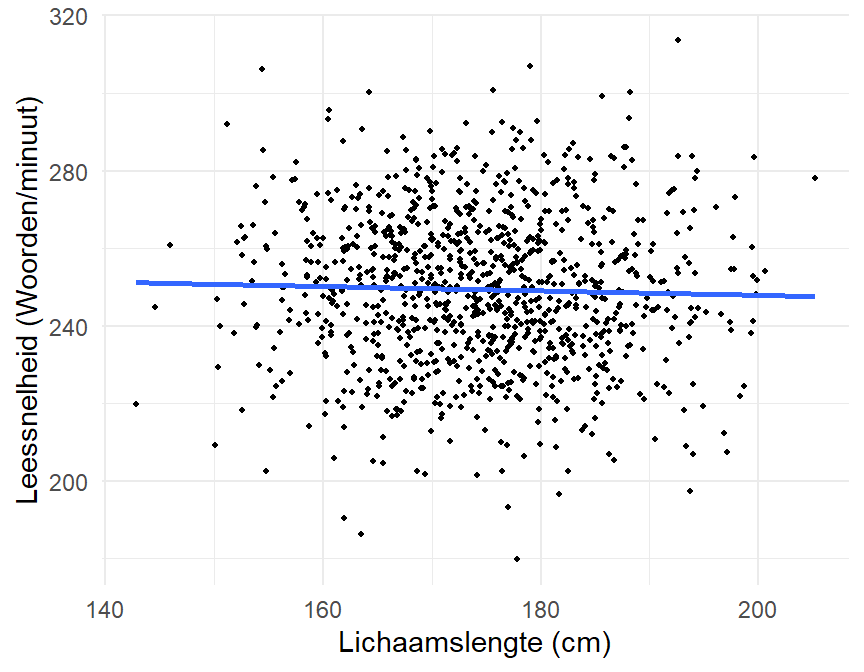
Bij een enkelvoudig lineaire regressie is het relevant om te onderzoeken of de richting van de rechte significant afwijkt van \(0\). De richtingscoëfficient is nul wanneer de rechte horizontaal loopt, waarbij er dus geen verandering is in \(Y\) bij een verandering in \(X\). Er is bijvoorbeeld geen verband tussen de lichaamslengte van volwassen personen en hun gemiddelde leessnelheid, zoals weergegeven in Figure 12.6.
We formuleren de nul- en de alternatieve hypothese:
- \(H_0\): \(\beta_1=0\)
- \(H_A\): \(\beta_1\neq0\) (of een eenzijdig alternatief)
De teststatistiek vergelijkt de schatter voor \(\beta_1\) met \(0\) rekening houdend met de variabiliteit in de schatting.
\[ T=\frac{b_1-0}{SE_{b_1}}\sim t_{n-2} \]
Ik voeg hier expliciet \(-0\) aan toe om duidelijk te maken dat we de schatter vergelijken met de verwachte waarde onder de nulhypothese. Merk op dat dit analoog is aan de t-test voor één gemiddelde. De teststatistiek volgt onder de nulhypothese een t-verdeling met \(n-2\) vrijheidsgraden.
Beschouw opnieuw de R-output voor ons regressiemodel:
summary(mdl)
Call:
lm(formula = PPVT ~ Taalvaardigheid, data = fb)
Residuals:
Min 1Q Median 3Q Max
-38.59 -5.59 0.40 5.89 20.91
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 57.0730 0.6814 83.8 <2e-16 ***
Taalvaardigheid 0.5008 0.0142 35.3 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 8.37 on 744 degrees of freedom
Multiple R-squared: 0.626, Adjusted R-squared: 0.625
F-statistic: 1.24e+03 on 1 and 744 DF, p-value: <2e-16De schatter \(b_1\) is gelijk aan \(0.5008\) en de \(SE\) is gelijk aan \(0.0142\). De teststatistiek is dus \(0.5008/0.0142=35.3\). Een zeer grote teststatistiek met een zeer kleine cumulatieve proportie (P-waarde, hier symbolisch weergegeven als “Pr(>|t|)”).
We kunnen ook de pt() functie gebruiken om de p-waarde te berekenen.
pt(q = 35.3, df = 746-2, lower.tail = FALSE)*2[1] 4.09e-161We kunnen op dezelfde manier testen of het intercept verschillend is van \(0\) maar meestal is dat niet zo relevant.
12.10 Betrouwbaarheidsintervallen
Een \((100-\alpha)\) betrouwbaarheidsinterval voor \(\beta_0\) en \(\beta_1\) schatten we als volgt:
- Ondergrens: \(b_i-t^*SE_{b_i}\)
- Bovengrens: \(b_i+t^*SE_{b_i}\)
Met \(t^*\) de kritische waarde voor het betreffende BI voor een t-verdeling met \(n-2\) vrijheidsgraden. (\(t^*\) zal doorgaans dicht bij \(2\) liggen).
We kunnen het BI vragen via R:
confint(mdl, level = 0.95) 2.5 % 97.5 %
(Intercept) 55.735 58.411
Taalvaardigheid 0.473 0.52912.11 Assumpties
De gebruikelijke parametrische assumpties gelden voor het enkelvoudig lineair regressiemodel:
- onafhankelijkheid: is elk datapunt onafhankelijk van de andere tot stand gekomen? Als er meerdere metingen zijn voor dezelfde participant, dan is er sprake van clustering in de data en is deze assumtie geschonden. Clustering kan in rekening gebracht worden via een gemengd model (wordt niet behandeld in dit handboek)
- normaliteit van de residuelen. De spreiding van de observaties rond de geschatte rechte moet normaal verdeeld zijn.
- homoscedasticiteit: De spreiding van de observaties rond de geschatte rechte moet gelijkmatig verdeeld zijn
- lineariteit: De rechte moet een correct model zijn
De assumpties kunnen we op dezelfde manier testen als bij de t-test. De mensen die de lm() functie ontwikkeld hebben, wisten ook dat assumpties belangrijk zijn en daarom kunnen de voornaamste assumpties met de simpele plot() functie onderzocht worden. Het argument van de functie is het object van de lm() functie dat we eerder gemaakt hebben.
plot(mdl) 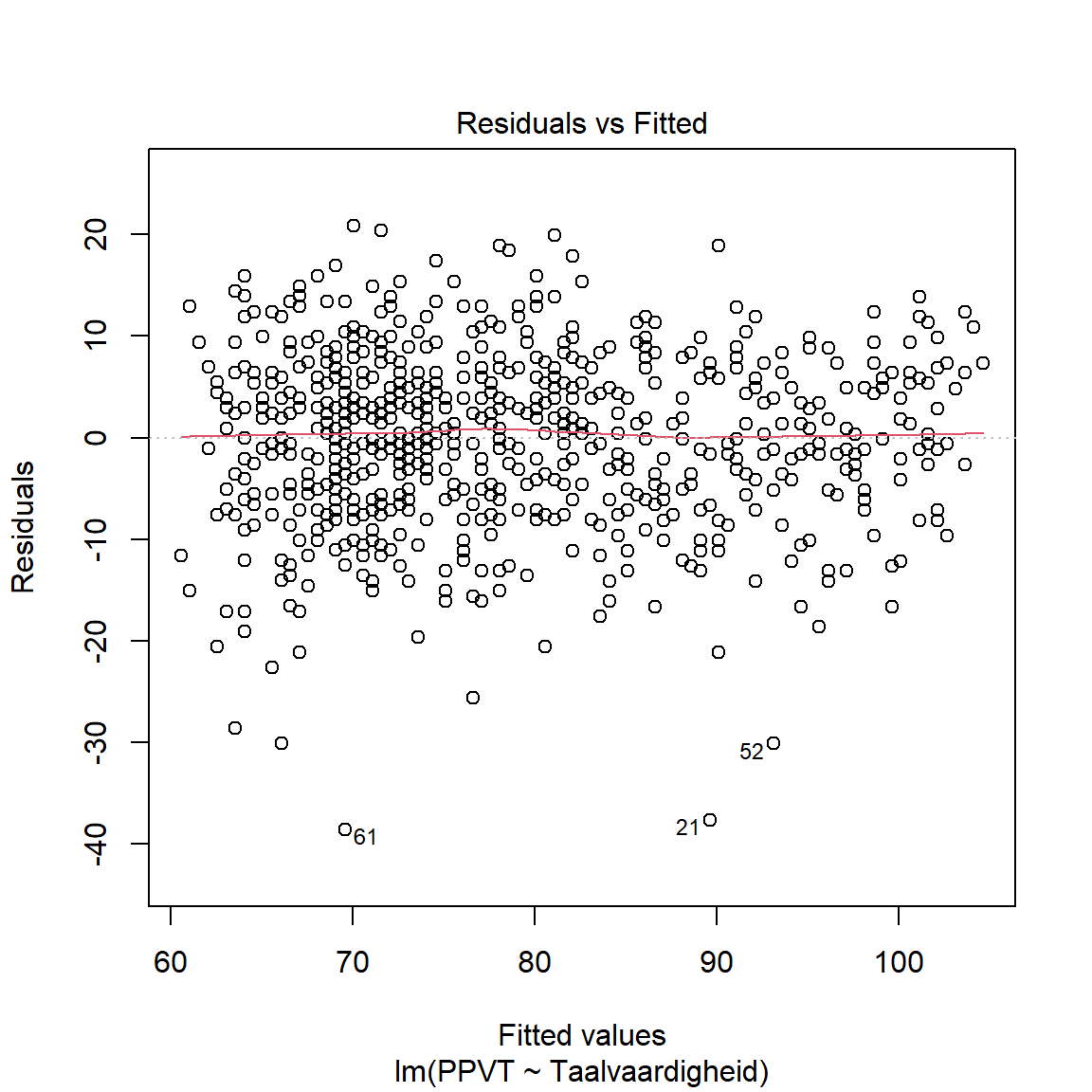
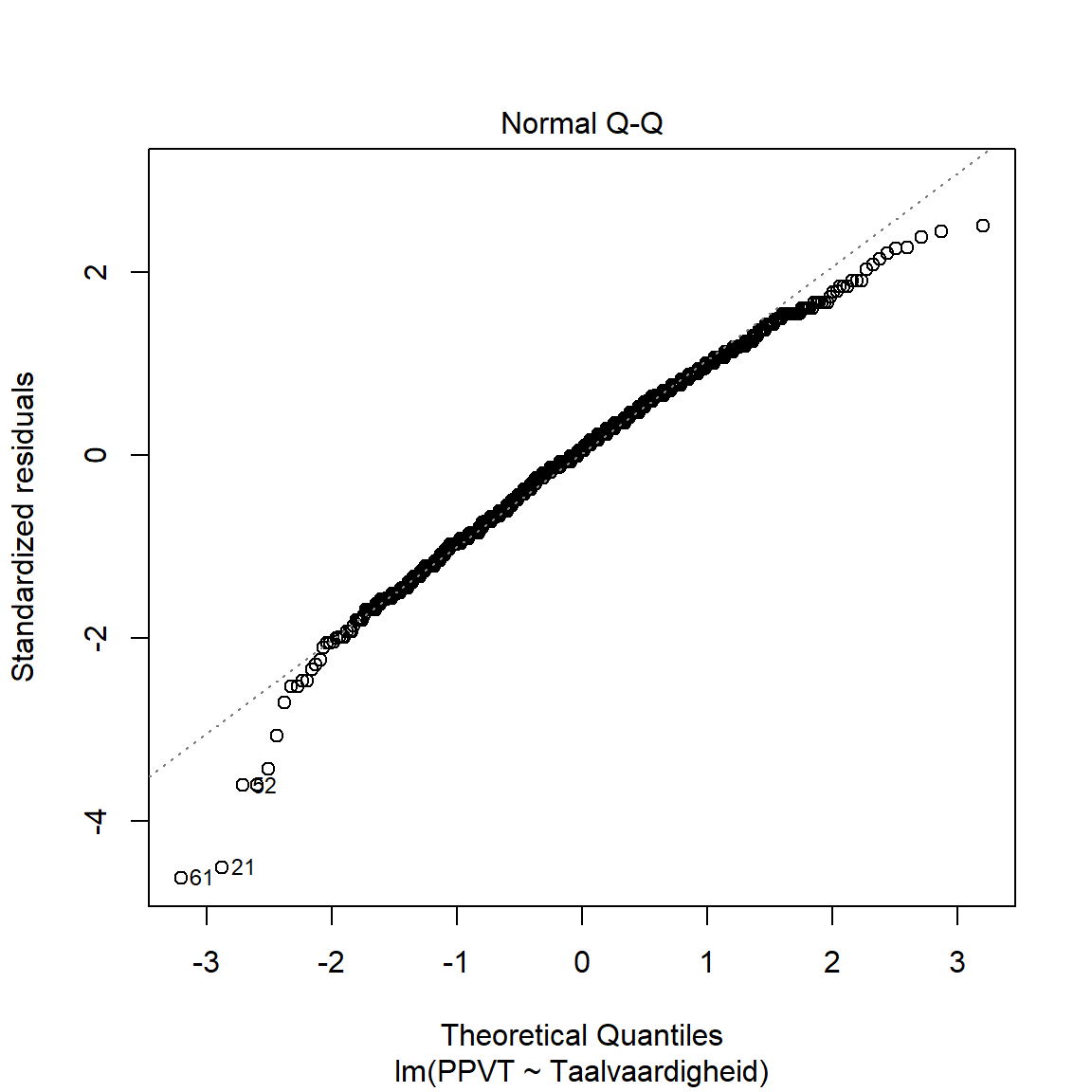
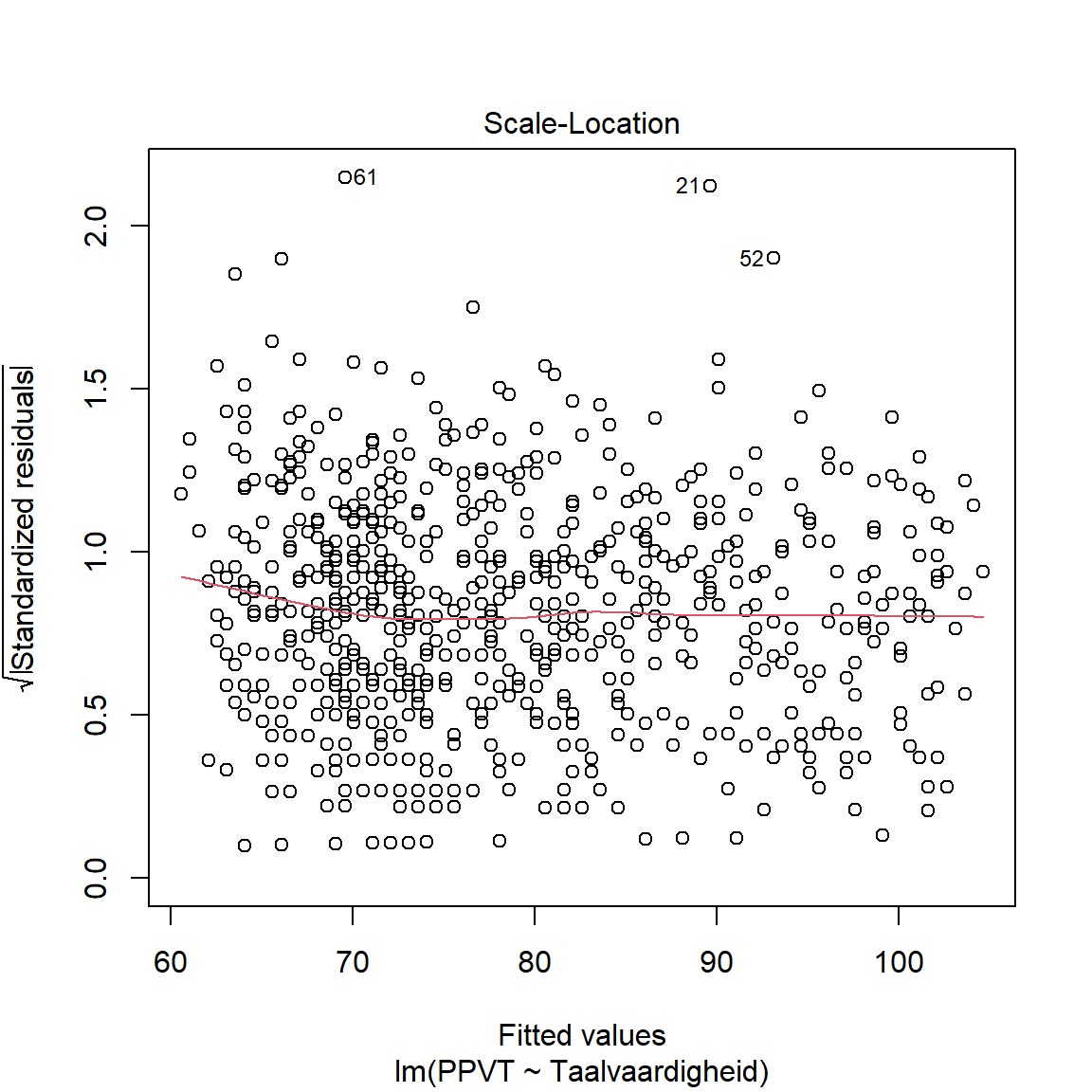
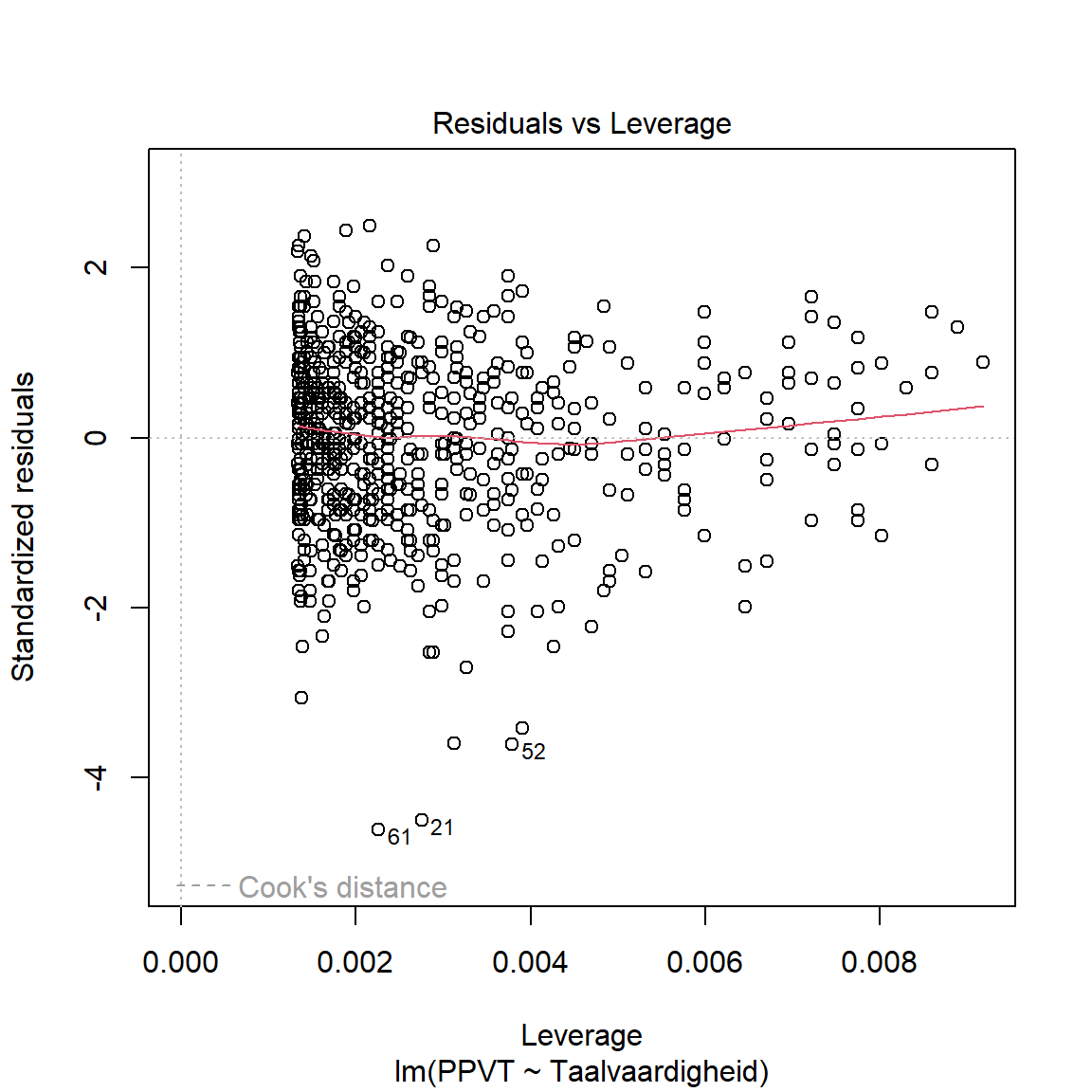
- Via de linkse figuren onderzoeken we homoscedasticiteit: we wensen geen patroon te zien in de datapunten rond de rode lijn.
- Via de qq-plot (rechts bovenaan) onderzoeken we de normaliteit van de residuelen. We verwachten dat de punten op de lijn liggen.
- Via de leverage-plot (rechts onderaan) bekijken we of er bepaalde observaties zijn die ver afliggen van de gefitte rechte. Dit zijn outliers binnen het model die een sterke invloed kunnen uitoefenen op de modelschatting.
Het performance package laat ook toe om de modelassumpties te evalueren.
performance::check_model(mdl)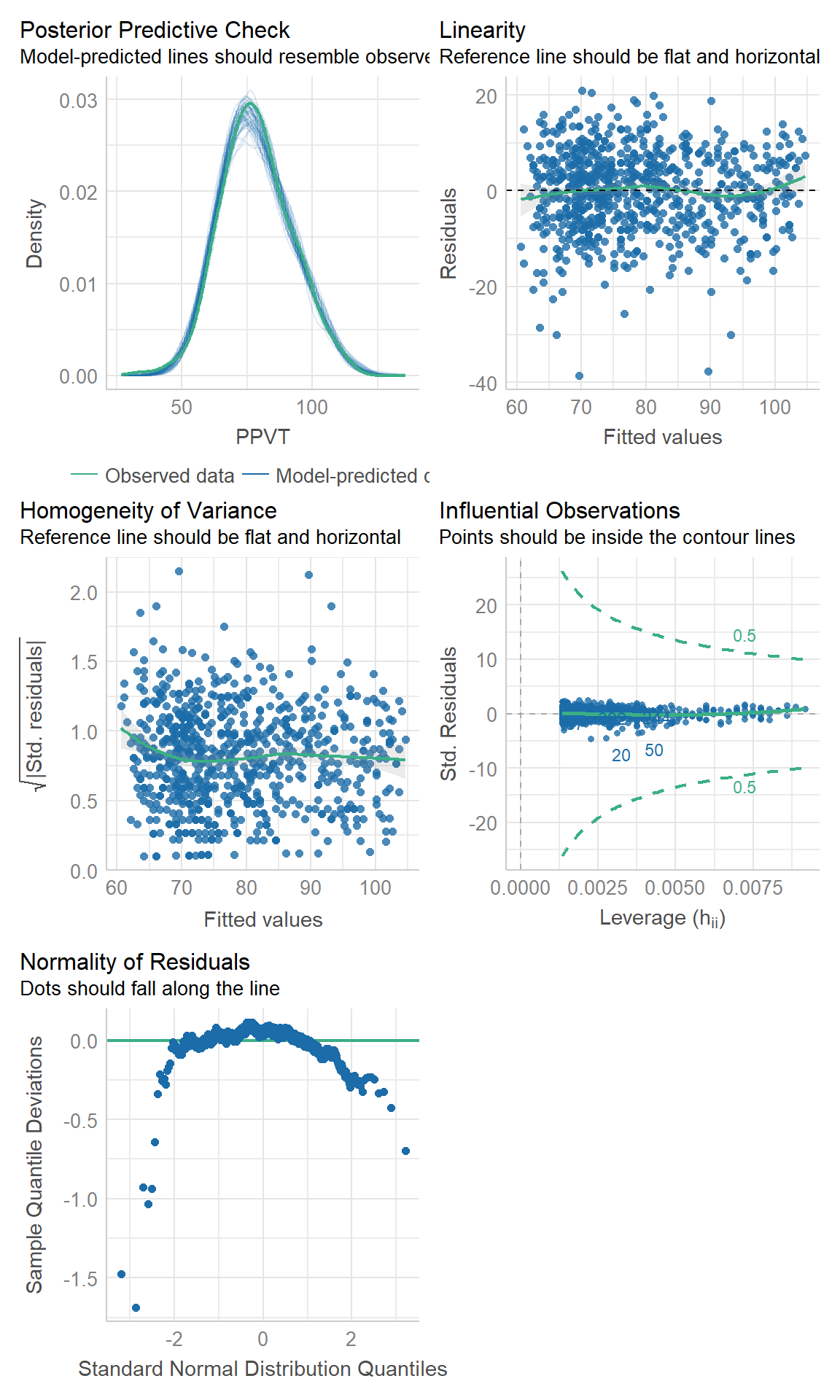
12.12 Verklaarde variantie \(R^2\)
In hoofdstuk 11 over de ANOVA hebben we gezien dat we een statistisch model conceptueel kunnen schrijven als \(Data = Fit + Residueel\). We hebben dit vertaald in termen van de variantie \(SSTO = SSTR + SSE\). We kunnen dit toepassen op een regressiemodel.
\[ \begin{split} SStotaal&= SSregressie + SSerror\\ \sum(y_{i}-\bar{y})²&=\sum(\hat{y}_i-\bar{y})^2+\sum(y_i-\hat{y}_i)^2 \end{split} \]
- \(SSTotaal\) betreft de afwijkingen van alle waarden van PPVT \(y_i\) ten opzichte van het algemeen gemiddelde \(\bar{y}\).
- \(SSregressie\) betreft de afwijkingen van de gefitte waarden \(\hat{y}_i\) ten opzichte van het algemeen gemiddelde \(\bar{y}\).
- \(SSerror\) betreft de afwijkingen van alle waarden van PPVT \(y_i\) ten opzichte van de gefitte waarden \(\hat{y}_i\).
We kunnen de kwadratensommen bereken.
SSregressie <- sum((fitted(mdl) - mean(fb$PPVT))^2)
# 87008
SSerror <- sum((fitted(mdl) - fb$PPVT)^2) # error
# 52078
SStotaal <- SStotaal <- sum((fb$PPVT-mean(fb$PPVT))^2) # totaal
# 139086Of, gemakkelijker, we gebruiken de anova() functie.
anova(mdl)Analysis of Variance Table
Response: PPVT
Df Sum Sq Mean Sq F value Pr(>F)
Taalvaardigheid 1 87008 87008 1243 <2e-16 ***
Residuals 744 52078 70
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1De anovatabel is belangrijk bij de meervoudige regressie om na te gaan welke variabelen significant bijdragen tot het model. Op basis van een F-test kunnen we hier besluiten dat de rechte significant afwijkt van nul, maar dat wisten we natuurlijk al op basis van de t-test.
Maar waarom hebben we die kwadratensommen dan wel nodig? Welnu, we kunnen de totale variantie in de data (= de variantie van de uitkomstvariabele) te vergelijken met de residuele variantie van de regressie. Op basis daarvan definiëren we de determinatiecoëfficiënt of het percentage verklaarde variantie \(R^2\):
\[ R^2=1-\frac{\sum(y_i-\hat{y}_i)^2}{\sum(y_i-\bar{y})^2}=1-\frac{SSerror}{SStotaal} \]
Of, equivalent:
\[ R^2=\frac{\sum(\hat{y}_i-\bar{y})^2}{\sum(y_i-\bar{y})^2}=\frac{SSregressie}{SStotaal} \]
In het gefitte model voor PPVT wordt ongeveer \(63\%\) van de variantie wordt verkaard door de lineaire regressie.
summary(mdl)$r.squared[1] 0.626Figure 12.8 toont mooi de intuïtie achter het concept van de verklaarde variantie
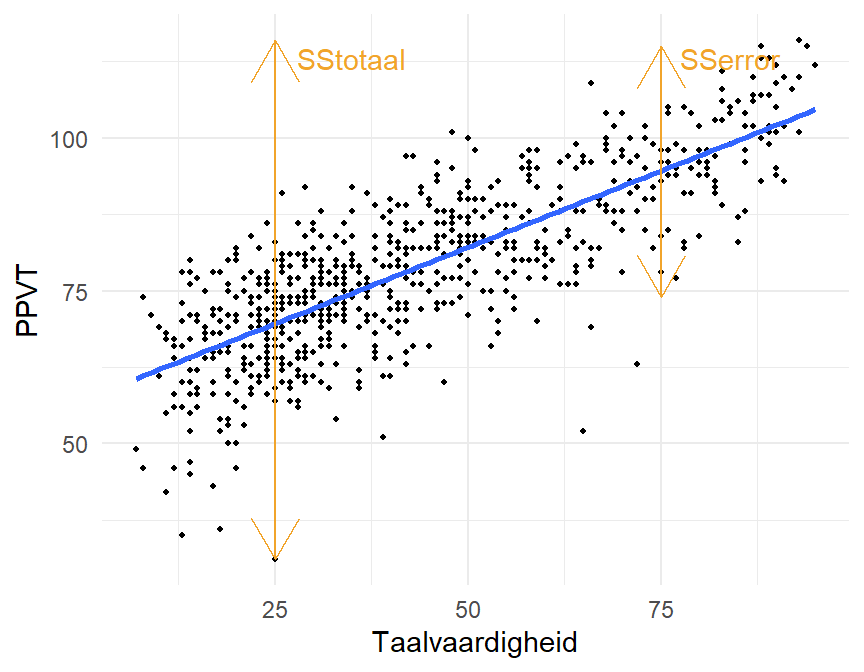
De \(SSerror\) verklaart een deel van de \(SStotaal\). Hoe kleiner SSerror hoe dichter de punten bij de regressielijn liggen, en hoe meer variantie de rechte (het model) dus “verklaart”.
Met een \(R^2\) van \(62\%\) is er nog wat ruimte ter verbetering. Zou geslacht een significant verschil maken?
mdl3 <- lm(PPVT ~ Taalvaardigheid*Geslacht, data = fb)
summary(mdl3)
Call:
lm(formula = PPVT ~ Taalvaardigheid * Geslacht, data = fb)
Residuals:
Min 1Q Median 3Q Max
-38.74 -5.24 0.60 5.65 20.71
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 56.0230 0.9753 57.44 < 2e-16 ***
Taalvaardigheid 0.5487 0.0189 28.97 < 2e-16 ***
Geslachtvrouw 3.0094 1.3460 2.24 0.026 *
Taalvaardigheid:Geslachtvrouw -0.1295 0.0283 -4.57 5.7e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 8.17 on 742 degrees of freedom
Multiple R-squared: 0.644, Adjusted R-squared: 0.642
F-statistic: 447 on 3 and 742 DF, p-value: <2e-16Geslacht is inderdaad significant in interactie met Taalvaardigheid (P < 0.0001). Een interactie betekent dat we niet zomaar een conclusie kunnen vormen voor de hoofdeffecten apart, maar dat we steeds rekening moeten houden met hun gezamelijk effect. Vrouwen hebben een lichtjes negatief effect in vergelijking met mannen naarmate hun taalvaardigheid stijgt. Dit zien we ook mooi in de effectplot in Figure 12.9.
predicted <- estimate_expectation(mdl3)
plot(predicted) +
theme_minimal() +
ggtitle(label = "")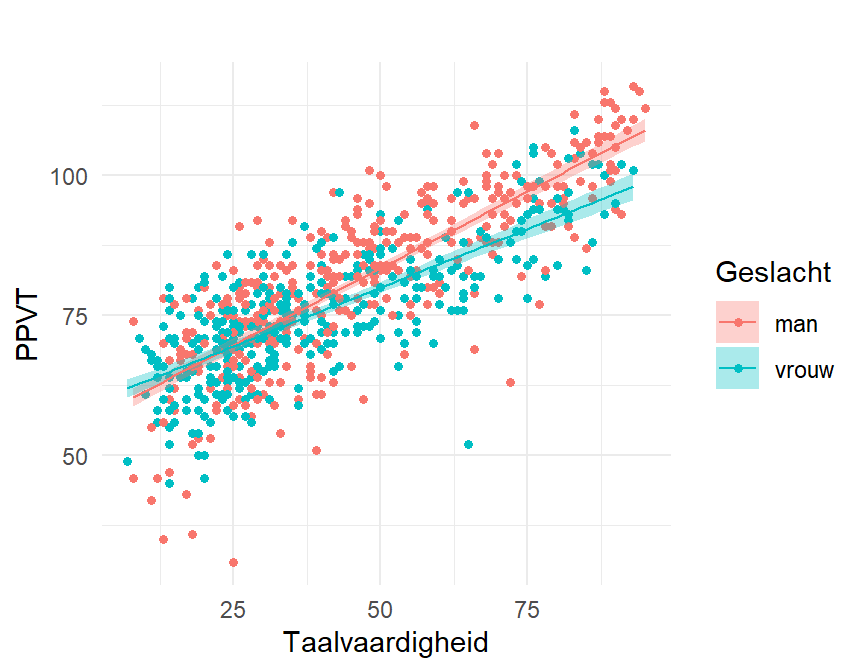
Voor een taalvaardigheid van 25 scoren mannen en vrouwen ongeveer gelijk, terwijl voor een taalvaardigheid van \(75\) mannen enkele punten hoger scoren dan vrouwen. OF dit verschil ook praktisch relevant is, kan enkel beoordeeld worden op basis van achtergrondkennis. Misschien is dit kleine verschil significant in het model, maar weinig praktisch relevant in de realiteit.
We bekomen met dit mogel een \(R^2\) van \(64\%\), een lichte verbetering ten opzichte van het enkelvoudige model. Andere variabelen kunnen allicht ook nog bijdragen tot het verklaren van de variantie in PPVT. En hier begint een moeilijke queeste: het fitten van complexere regressiemodellen. Want we kunnen niet enkel andere variabelen toevoegen, er zijn ook nog andere – niet-lineaire – modellen mogelijk. En zo kunnen we blijven zoeken naar het “beste” model.
12.13 Samenvatting en vooruitblik
In dit hoofdstuk hebben we een tipje van de sluier gelicht van de regressieanalyse. We zijn gestart met het enkelvoudig lineair regressiemodel, waarbij we de lineaire relatie tussen twee continue variabelen onderzocht hebben. Vanaf nu ben je klaar voor het echte werk. Het regressiemodel kan uitgebreid worden met zowel continue als categorische predictoren, waarbij ook interacties in rekening kunnen gebracht worden. Het is ook mogelijk om met categorische uitkomsten te werken. Het logistisch regressiemodel is geschikt voor binaire uitkomsten, het multinomiale model voor meerdere categorische uitkomsten. Verder kan de lineariteitsassumptie losgelaten worden en kunnen er niet-lineare verbanden gefit worden. Er zijn meerdere uitkomsten tegelijkertijd mogelijk en het is zelfs mogelijk om verschillende regressievergelijkingen in één groot netwerk samen te brengen (cf. “Structural Equation Models”). Een andere uitbreiding is met zogenaamde random effects, waarbij er voor verschillende items en participanten eigen effecten toegelaten worden (random intercepts en random slopes). En als je model niet voldoet aan de assumpties zijn allerlei niet-parametrische opties en andere aanpassingen mogelijk. Welkom in de wondere wereld van de statistiek.
12.14 Terminologie
- covariantie
- correlatie
- regressiemodel
- gefitte regressielijn
- parameters: \(\beta_0\), \(\beta_1\), \(\epsilon\)
- schatters: \(b_0\), \(b_1\), \(e\)
- errors/residuelen
- een model fitten/schatten
- geobserveerde waarden
- voorspelde waarden
- kleinste kwadratenmethode
- verklaarde variantie R²
Functies:
- lm()
- summary()
- plot()
- fitted()
- residuals()
12.15 Oefeningen
- Correlatie. Er bestaan verschillende intelligentietesten om (analytische) intelligentie te meten. De dataset
IQ_tests_Kaufman2009.txtbevat de scores van 12 personen voor drie IQ-testen (KABC-II, WISC-III en WJ-III). (bronnen: Kaufman (2009) en https://en.wikipedia.org/wiki/Intelligence_quotient).- Maak een correlatieplot om de samenhang te vergelijken.
- Maak een correlatiematrix om de correlaties te meten en te vergelijken/
- Formuleer je besluit.
- Lexicale decisie. Het is te verwachten dat reactiesnelheden vertragen naarmate een test vordert. Beschouw opnieuw de
lexdecdataset en fit een regressiemodel met RT als uitkomstvariabele en Trial als predictor.- Wat verwacht je van de regressielijn? Teken jouw verwachting met de hand op een blad papier.
- Visualiseer de samenhang tussen beide variabelen aan de hand van een scatterplot met een geschatte regressielijn. Interpreteer de figuur en vergelijk met jouw tekening.
- Fit vervolgens een enkelvoudig regressiemodel.
- Schrijf de regressievergelijking op en interpreteer alle elementen.
- Ga alle noodzakelijke veronderstellingen na.
- Geef het 95 % betrouwbaarheidsinterval voor de parameter
Trial - Is de richtingscoëfficiënt significant verschillend van \(0\)?
- Geef een praktische interpretatie van je bevindingen.
- Talenkennis. Table 12.3 geeft de schoolresultaten (op 100) voor Frans en Duits voor twintig leerlingen.
- Zet de tabel om naar een dataframe
- Maak een scatterplot en voeg een regressielijn toe
- Bereken de correlatie
- Fit een regressiemodel om na te gaan of er een positief verband bestaat tussen de resultaten voor beide talen.
| Leerling | Frans | Duits |
|---|---|---|
| 1 | 72 | 63 |
| 2 | 48 | 40 |
| 3 | 34 | 61 |
| 4 | 58 | 52 |
| 5 | 80 | 68 |
| 6 | 41 | 54 |
| 7 | 35 | 30 |
| 8 | 55 | 54 |
| 9 | 61 | 52 |
| 10 | 60 | 49 |
| 11 | 74 | 80 |
| 12 | 45 | 49 |
| 13 | 48 | 51 |
| 14 | 50 | 47 |
| 15 | 58 | 45 |
| 16 | 63 | 61 |
| 17 | 56 | 50 |
| 18 | 64 | 60 |
| 19 | 28 | 41 |
| 20 | 59 | 58 |
- Regressie met gestandaardiseerde waarden. Beschouw opnieuw de dataset in oefening 3. Wanneer beide variabelen gestandaardiseerd zijn (beide hebben dan gemiddelde \(\bar{X} = 0\) en standaardafwijking \(s = 1\)), dan is \(\beta_0 = 0\) en \(\beta_1 = r\). Fit een regressiemodel met de gestandaardiseerde variabelen en ga na of dit inderdaad het geval is.