- 1
-
De levels van de factor
Taal - 2
- hoeveel keer elke level herhaald moet worden.
6 Univariate samenvattingen
We beschouwen de hypothetische dataset in Table 6.1. Veronderstel dat de data tot stand kwam op basis van een taaltest die werd afgenomen in twee verschillende groepen van elk \(n=15\) participanten. De dataset werd opgesteld in het lange dataformaat en telt in totaal \(N=30\) observaties. We noteerden ook de talenkennis van de participanten en onderscheidden daarbij drie mogelijkheden: een-, twee- of meertalig. Table 6.1 geeft een overzicht van de eerste en laatste 3 participanten.
| Participant | Groep | Talenkennis | Score |
|---|---|---|---|
| 1 | A | eentalig | 14 |
| 2 | A | eentalig | 15 |
| 3 | A | meertalig | 13 |
| … | … | … | |
| 28 | B | tweetalig | 15 |
| 29 | B | tweetalig | 18 |
| 30 | B | meertalig | 9 |
De kolomnamen Groep, Talenkennis, en Score noemen we de variabelen van de dataset. Een variabele is een eigenschap van een entiteit die – zoals de naam het zegt – verschillende waarden kan aannemen. Participant is geen variabele, maar een uniek identificatienummer voor elke Participant.
We onderscheiden twee types variabelen:
- Categorische variabele (ook kwalitatief genoemd)
- Continue variabele (ook kwantitatief genoemd)
De waarden van een categorische variabele kunnen we onderverdelen in categorieën (ook “levels” genoemd). De variabele Groep is een voorbeeld van een categorische variabele met twee waarden. Beide waarden hebben een frequentie van \(15\) (er zijn \(n=15\) observaties voor “A” en \(15\) voor “B”). De variabele Score is een continue variabele. De laagst mogelijke waarde is \(0\) en de hoogst mogelijke waarde is \(20\). Deze waarden zijn het resultaat van een meting. De verdeling van een variabele geeft aan welke waarden de variabele aanneemt (of kan aannemen) en met welke frequentie. Het onderscheid tussen een categorische en continue variabele is cruciaal om een correcte samenvatting van een variabele te maken. Een variabele samenvatten betekent enerzijds de verdeling van de variabele beschrijven in samenvattende waarden en anderzijds de verdeling van de variabele visualiseren.
6.1 Een categorische variabele beschrijven
We creëren een categorische variabele Talenkennis met drie mogelijke waarden (“eentalig”, “tweetalig”, “meertalig”) en \(N=40\) observaties.
Hoeveel observaties hebben we voor elke waarde? Met andere woorden, wat is de verdeling van de variabele?
table(Taal) Taal
eentalig meertalig tweetalig
26 4 10 Wanneer we de respectievelijke frequenties delen door het totaal aantal observaties dan krijgen we de relatieve frequenties, wat een andere manier is om de verdeling te beschrijven.
prop.table((table(Taal)))Taal
eentalig meertalig tweetalig
0.65 0.10 0.25 Table 6.2 beschrijft de verdeling van de categorische variabele Talenkennis in een frequentietabel.
| Waarde | Frequentie | Relatieve freq. (%) | Cumulatieve freq. (%) |
|---|---|---|---|
| eentalig | \(26\) | \(65\%\) | \(65\%\) |
| tweetalig | \(10\) | \(25\%\) | \(90\%\) |
| meertalig | \(4\) | \(10\%\) | \(100\%\) |
We kunnen de verdeling visualiseren aan de hand van een staafdiagram. De hoogte van de staven geven de frequentie (of proportie) weer van elke waarde. Figure 6.1 geeft een voorbeeld in R:
barplot(table(Taal), xlab = "Talenkennis", ylab = "Aantal",
las = 1, col=("#F1A42B"))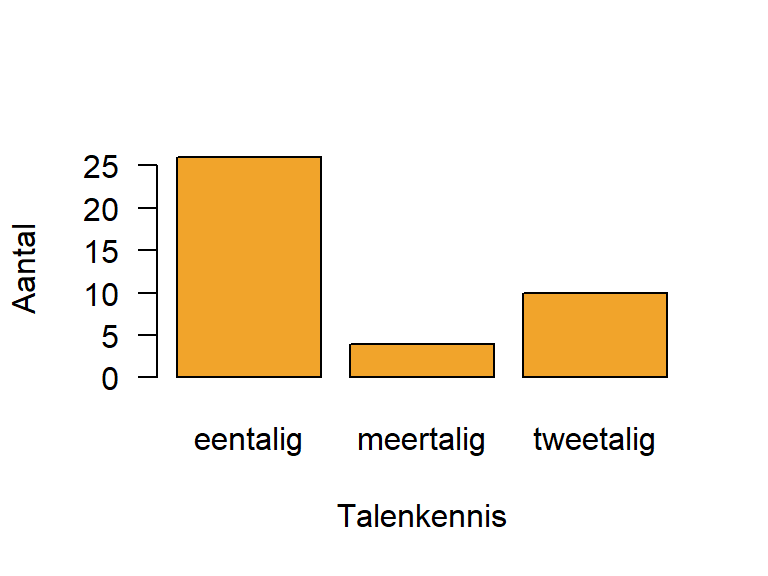
6.2 Een continue variabele beschrijven
Een continue variabele vatten we samen aan de hand van centrum- en spreidingsmaten:
Centrummaten
- Gemiddelde
- Mediaan
- Modus
Spreidingsmaten
- Minimum
- Maximum
- Quartielen (Decielen en Percentielen)
- Variantie & Standaardafwijking
- MAD
6.2.1 Steekproefgemiddelde
We beschouwen een dataset met de lichaamslengte van \(N=20\) basketbalspelers.
Lengte <- c(184, 217, 191, 196, 205, 177, 209, 185, 200, 189,
221, 221, 194, 173, 196, 201, 188, 182, 189, 196)Het gemiddelde van een steekproef is het wiskundig gemiddelde, dat gedefinieerd wordt als:
\[ \bar{X} =\frac{1}{n}\sum_{i=1}^{n}x_i \tag{6.1}\]
We berekenen het wiskundig gemiddelde door alle elementen uit de dataset (\(x_i\)) op te tellen (\(\sum\), de Griekse hoofdletter sigma) en vervolgens te delen door het totale aantal elementen (\(\frac{1}{n}\)). Equation 6.2 geeft de stappen weer.
\[ \begin{split} \bar{X} & =\frac{x_1+x_2+...+x_n}{n} \\ & =\frac{1}{n}(x_1+x_2+...+x_n) \\ & =\frac{1}{n} \sum_{i=1}^{n}x_i \end{split} \tag{6.2}\]
Het gemiddelde berekenen we door alle waarden op te tellen en te delen door het totale aantal observaties of we gebruiken de mean() functie.
sum(Lengte)/length(Lengte)[1] 195.7mean(Lengte, na.rm = TRUE) [1] 195.76.2.2 Gewogen gemiddelde
Het adjectief lovely komt \(N=2443\) maal voor in het British National Corpus (data via http://bncweb.lancs.ac.uk/). Het woord komt \(810\) keer voor bij mannelijke auteurs, \(1432\) keer bij vrouwelijke, en \(201\) keer bij auteurs waarvan het geslacht als “mixed” staat aangeduid in het corpus (“mixed” betekent dat het werk door meerdere auteurs van verschillende geslachten werd geschreven).
Om de gemiddelde frequentie van het woord lovely te berekenen kunnen we het wiskundig gemiddelde in Equation 6.1 niet gebruiken. We moeten er immers rekening mee houden dat de deelcorpora voor elk geslacht een verschillend aantal woorden bevat, zoals aangegeven in Table 6.3
| Subcorpus | Frequentie | Woorden corpus |
|---|---|---|
| mannen | 810 | 30662031 |
| vrouwen | 1432 | 14588254 |
| mixed | 201 | 6538929 |
Het gewogen gemiddelde houdt rekening met de grootte van de verschillende subcorpora.
\[ \begin{split} \text{gewogen gemiddelde} & =\frac{30662031*810+14588254*1432+6538929*201}{30662031+14588254+6538929}\\ & =\frac{30662031}{51789214}*810+\frac{14588254}{51789214}*1432+\frac{6538929}{51789214}*201\\ & = 908 \end{split} \tag{6.3}\]
De proporties \(\frac{30662031}{51789214}=0.59, \frac{14588254}{51789214}=0.28, \frac{6538929}{51789214}=0.13\) zijn de “gewichten” voor elk subcorpus. Het gewogen gemiddelde wordt gedefinieerd als in Equation 6.4:
\[ \bar{X}_w=\frac{\sum_jN_j\bar{x_j}}{\sum_jN_j} \tag{6.4}\]
Daarbij is \(j\) een index voor elk stratum in de data (hier: de drie subcorpora). \(N_j\) staat voor het aantal observaties in het stratum, dus is \(\sum_jN_j\) de totale som van alle observaties.
6.2.3 Mediaan
De mediaan is een locatiewaarde (ook wel volgordestatistiek genoemd). Voor een steekproef \(X_{(1)},...,X_{(n)}\) definiëren we:
\[ \begin{split} X_{(1)}&=\min_{1 \le i\le n} X_i, \\ X_{(2)}&=\text{tweede kleinste waarde} X_i, \\ \vdots \\ X_{(n)}&=\max_{1 \le i \le n} X_i.\\ \end{split} \]
We sorteren eerst alle observaties van laag naar hoog. De mediaan is de waarde waarvoor geldt dat de helft van alle observaties kleiner (of groter) is.
We sorteren alle waarden van de variabele Lengte:
sort(Lengte, decreasing = FALSE) [1] 173 177 182 184 185 188 189 189 191 194 196 196 196 200 201 205 209 217 221
[20] 221De kleinste waarde \(X_{(1)}\) is gelijk aan \(173\), de grootste \(X_{(20)}\) is gelijk aan \(221\).
De mediaan wordt gedefinieerd als in Equation 6.5:
\[ M= \begin{cases} X_{((n+1)/2)} &\text{als}~n~\text{oneven is} \\ (X_{(n/2)}+X_{(n/2+1)})/2 &\text{als}~n~\text{even is.} \end{cases} \tag{6.5}\]
Lengte bevat \(n=20\) observaties. De mediaan is dus het gemiddelde van de twee middelste waarden, \(X_{(10)}=194\) en \(X_{(11)}=196\), dus: \((194+196)/2=195\).
median(Lengte)[1] 195Wanneer we een oneven aantal observaties hebben, dan is de mediaan de middelste waarde. We voegen 1 observatie toe en gebruiken de indexfunctie om de elfde waarde (\(X_{((n+1)/2)}=(21+1)/2=11\)) uit de steekproef te halen.
Lengte <- c(Lengte, 200)
sort(Lengte, decreasing = FALSE)[11] [1] 196Vergelijk:
median(Lengte)[1] 1966.2.4 Modus
De modus is de waarde die het vaakst voorkomt. Die is vooral interessant bij categorische variabelen of wanneer de continue variabele afgeronde waarden bevat (zodat we meerder observatie hebben van dezelfde waarde). De modus kun je zoeken via table() om de waarde te zoeken met de hoogste frequentie.
6.2.5 Spreidingsmaten
Beschouw opnieuw de gesorteerde dataset Lengte:
sort(Lengte, decreasing = FALSE) [1] 173 177 182 184 185 188 189 189 191 194 196 196 196 200 200 201 205 209 217
[20] 221 221De spreiding van de data kunnen we samenvatten aan de hand van locatiewaarden, zoals:
min(Lengte) # minimum [1] 173median(Lengte)[1] 196max(Lengte) # maximum [1] 221range(Lengte) # bereik (= max-min)[1] 173 221quantile(x = Lengte, probs = c(0.25)) # het eerste quartiel25%
188 quantile(x = Lengte, probs = c(0.25, 0.75)) # de quartielen 25% 75%
188 201 quantile(x = Lengte, probs = c(0.10, 0.90)) # het eerste en negende deciel10% 90%
182 217 Het eerste kwartiel betekent dat \(25\%\) van de data kleiner is dan \(188\). Het negende deciel betekent dat \(90\%\) kleiner is dan 219. Enz.
6.2.6 Variantie en standaardafwijking
De standaardafwijking \(s\) en de variantie \(s^2\) van een steekproef zijn twee maten die de gemiddelde spreiding van een een continue variabele samenvatten. Beide zijn verwant: de de standaardafwijking is de vierkantswortel van de variantie.
De variantie is een maat voor de gekwadrateerde gemiddelde afwijking van alle observaties ten opzichte van het steekproefgemiddelde. Omdat de standaardafwijking een gekwadrateerde maat is, nemen we de vierkantswortel om op die manier een maat te krijgen in de eenheid waarin we meten.
De steekproefvariantie wordt gedefinieerd als Equation 6.6:
\[ s^2=\frac{1}{n-1}\sum_{i=1}^{n}(x_i-\bar{X})^2 \tag{6.6}\]
Het deel \(\sum_{i=1}^{n}(x_i-\bar{X})^2\) wordt ook een kwadratensom genoemd. De variantie deelt die som door het aantal observaties en is daardoor analoog aan een gemiddelde. Daarom noemt men de variantie ook wel een gemiddelde kwadratensom.
De standaardafwijking is de vierkantswortel van de variantie, zoals in Equation 6.7:
\[ s=\sqrt{s^2}=\sqrt{\frac{1}{n-1}\sum_{i=1}^{n}(x_i-\bar{X})^2} \tag{6.7}\]
Wat is de variantie en de standaardafwijking van onze variabele Lengte?
var(Lengte)[1] 176.9905sd(Lengte)[1] 13.30378Merk op dat het kwadraat nodig is omdat de som van de afwijkingen van alle observaties ten opzichte van het gemiddelde nul is.
round(sum(Lengte-mean(Lengte)),0)[1] 0Er bestaan ook andere oplossing om nul te vermijden. We kunnen bijvoorbeeld de absolute waarde nemen, zoals in Equation 6.8. We spreken in dat geval van de gemiddelde absolute afwijking, ook wel MAD genoemd (“Mean Absolute Deviation”).
\[ \text{MAD}=\frac{1}{n-1}\sum_{i=1}^{n}|x_i-\bar{X}| \tag{6.8}\]
6.2.7 Boxplot
De boxplot in Figure 6.2 visualiseert de locatiewaarden van een continue variabele, meer bepaald:
- het minimum
- het eerste kwartiel
- de mediaan: de streep in de box
- het derde kartiel
- het maximum
- outliers naar boven of beneden, indien die aanwezig zijn.
boxplot(Lengte,
col = "#F1A42B",
Las = 1,
ylab = "Lengte (cm)")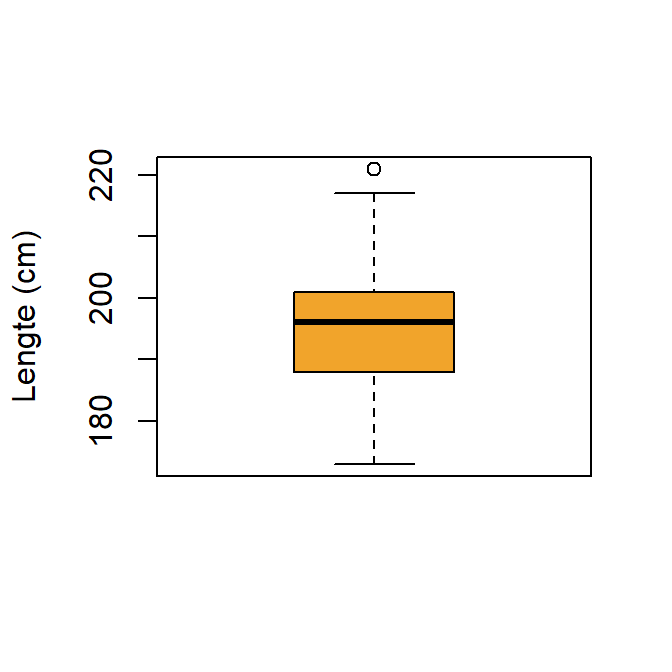
- De bolletjes zijn outliers. Outliers worden in de boxplot gedefinieerd als observaties die meer dan \(1,5\) maal de interkwartielafstand (IKA) verwijderd zijn van het dichtsbijzijnde kwartiel.
- de whiskers zijn de kleinste/grootste observaties die geen outliers zijn.
Belangrijk: de whiskers geven niet de grenswaarde \(1.5\) maal de IKA weer!
6.2.8 Histogram
Een histogram laat toe om de vorm van de verdeling te bekijken. Is de verdeling symmetrisch? Vertoont de verdeling meerdere pieken (“modi”) of is er een duidelijk scheefheid en staart? Figure 6.3 visualiseert de variabele Lengte.
hist(Lengte,
col = "#F1A42B",
xlab = "Lengte (cm)",
main = "")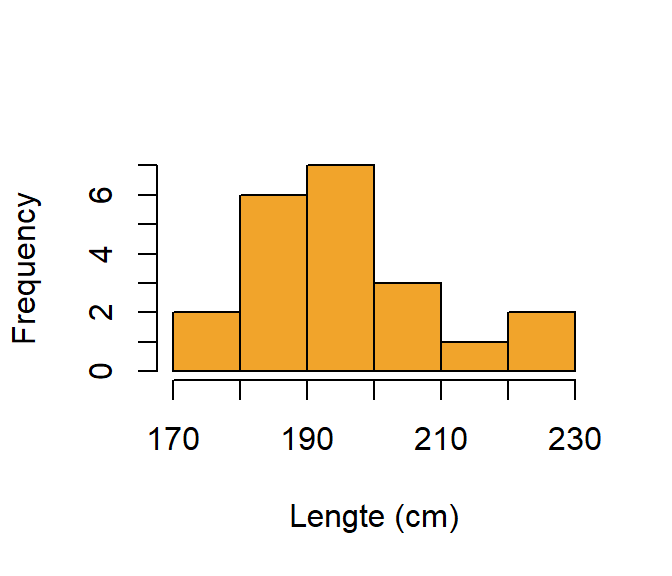
Figuur Figure 6.4 toont een duidelijk scheve verdeling. We noemen dit een linksscheve verdeling of een verdeling met een zware rechtse staart.
hist(exp(rnorm(100)),
main="",
xlab = "",
ylab = "",
col = "#F1A42B")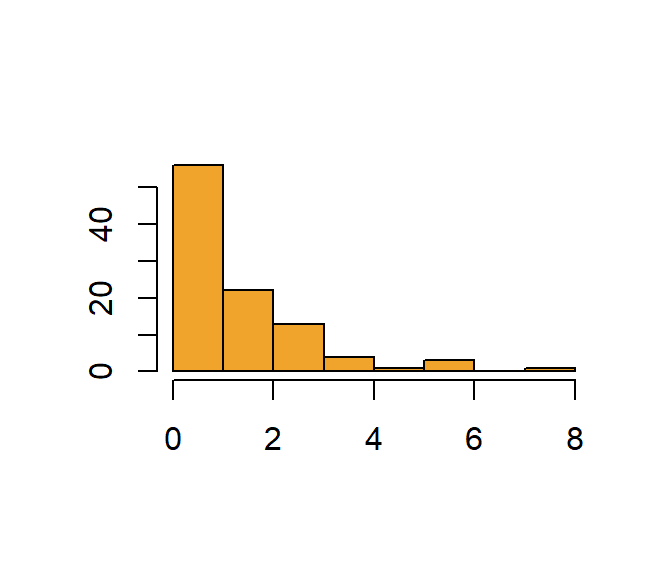
Figure 6.5 toont wat er gebeurt als we het aantal bins aanpassen.
hist(Lengte,
col = "#F1A42B",
breaks = 6,
main = "6 breaks",
xlab = "Lengte (cm)")
hist(Lengte,
col = "#F1A42B",
breaks = 40,
main = "40 breaks",
xlab = "Lengte (cm)")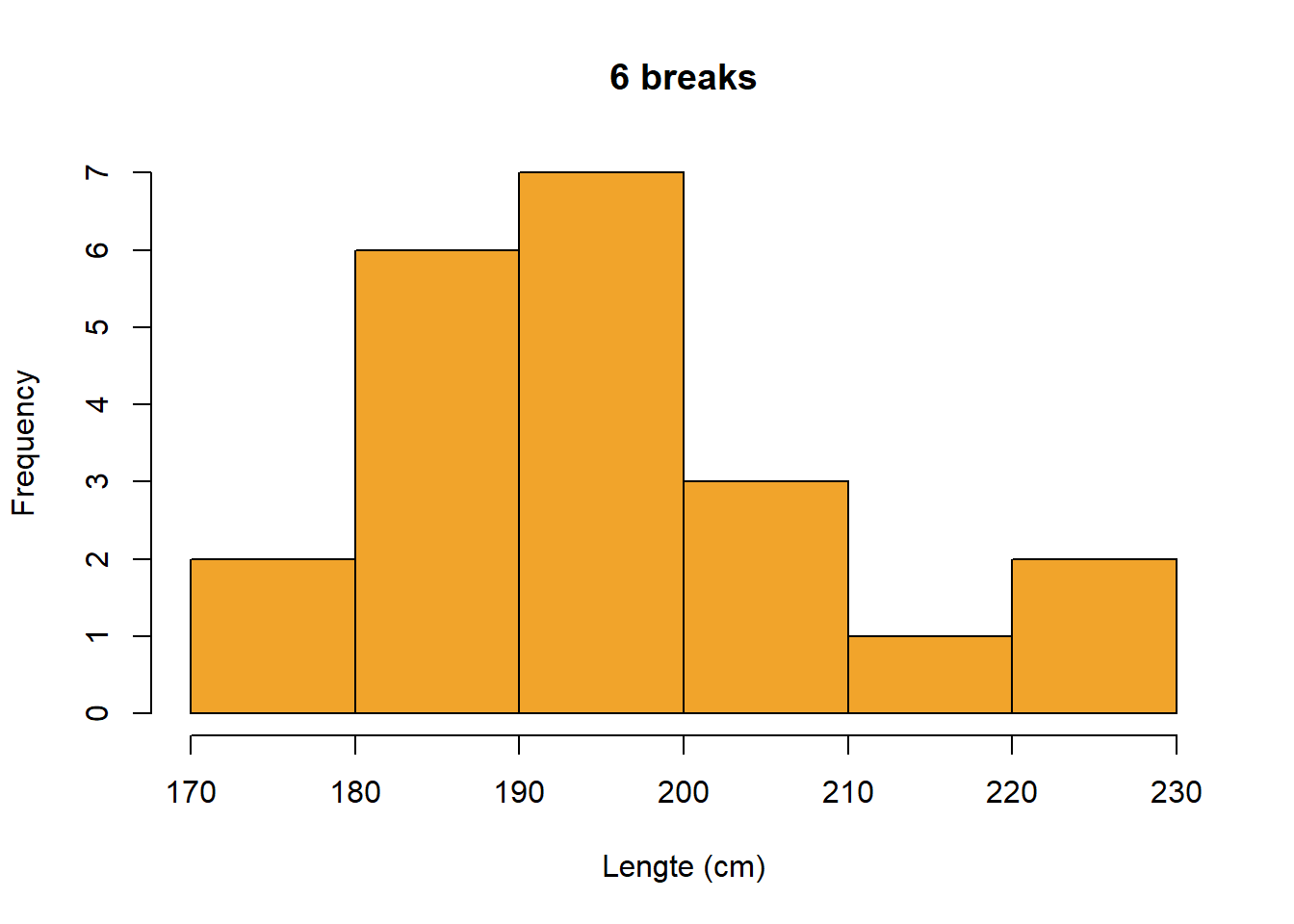
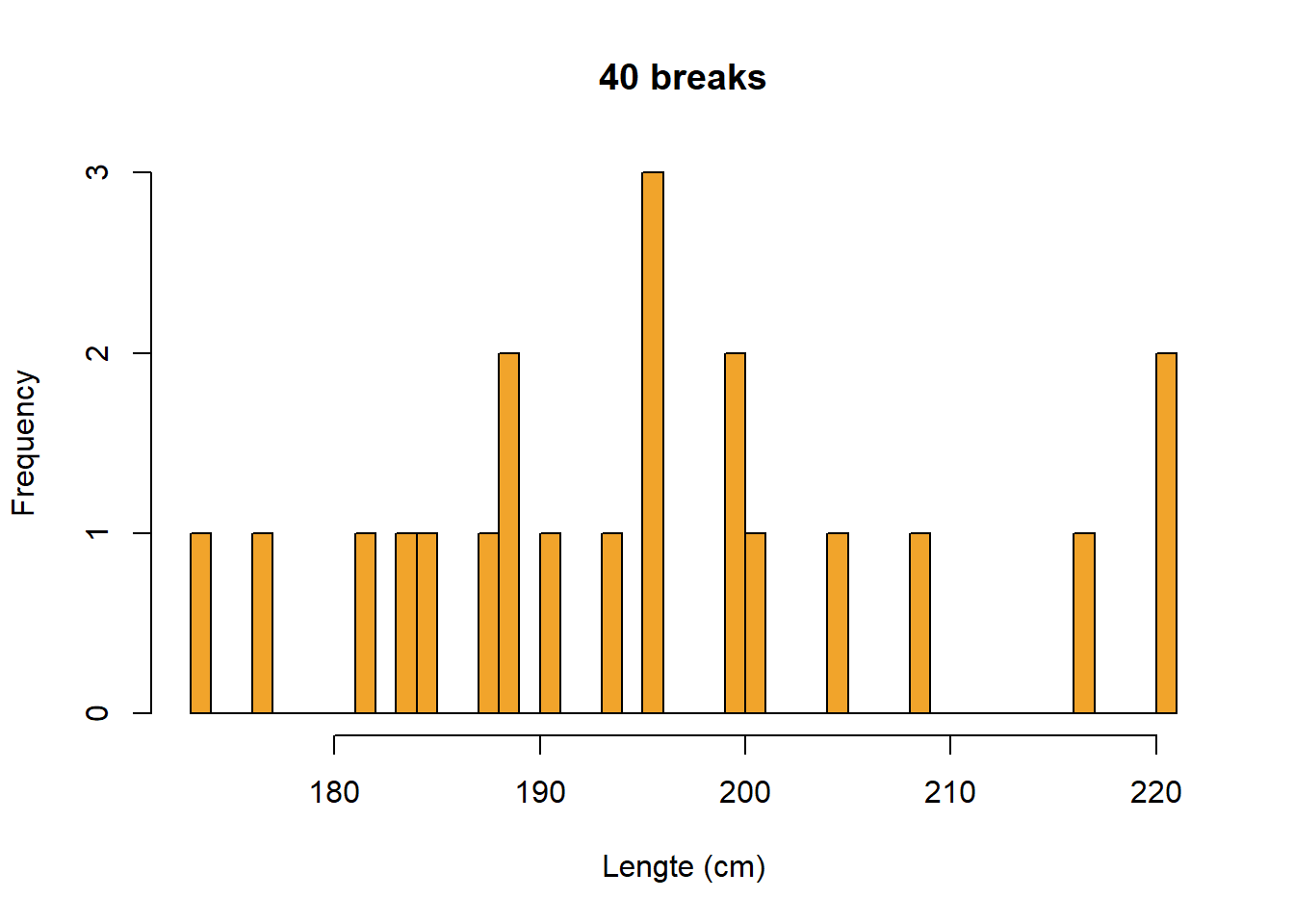
6.3 Samenvatting en vooruitblik
We zijn dit hoofdstuk gestart met een univariate beschrijving van de data. We weten nu wat een variabele is, dat er twee types bestaan (continue vs. categorische) en hoe we beide types kunnen samenvatten en visualiseren. In de volgende hoofdstukken gaan we variabelen met elkaar in verband brengen en verder analyseren.
We hebben in dit hoofdstuk een samenvatting gemaakt van steekproeven. De samenvattende waarden die we berekend hebben, zijn schatters voor de parameters uit een populatie. Het steekproefgemiddelde \(\bar{X}\) en de steekproefstandaardafwijking \(s\) zijn schatters voor de populatieparameters \(\mu\) en \(\sigma\). We gaan dit idee verder uitwerken in het volgende hoofdstuk over de normale verdeling.
6.4 Terminologie
- variabele
- verdeling (distributie)
- waarden
- categorieën (levels)
- categorische variabele
- continue variabele
- histogram
- boxplot
- staafdiagram (barplot)
- minimum
- maximum
- bereik
- kwantielen
- percentielen
- variantie
- standaardafwijking
- interkwartielafstand
- MAD
- kwadratensom
- gemiddelde
- mediaan
- modus
- frequentie
- proportie
- schatter
- parameter
- steekproef
- populatie
Functies
- mean
- median
- var()
- sd()
- table()
- quantile()
- summary()
- fivenum()
- range()
- min()
- max()
- barplot()
- hist()
- boxplot()
6.5 Oefeningen
- Een continue variabele verkennen. Degree of Reading Power (DRP) is een score voor de leesvaardigheid van kinderen. Smith (1987) verzamelde een dataset met N = 44 scores: 40 26 39 14 42 18 25 43 46 27 19 47 19 26 35 34 15 44 40 38 31 46 52 25 35 35 33 29 34 41 49 28 52 47 35 48 22 33 41 51 27 14 54 45
- Maak een vector genaamd DRP met de 44 scores.
- Wat is de kleinste DRP-waarde?
- Wat is de hoogste DRP-waarde?
- Wat is de 5e waarde uit de vector? (gebruik een functie)
- Selecteer een aselecte steekproef van tien scores uit DRP. Geef die vector de naam DRP_s.
- Bereken de volgende statistieken:
- gemiddelde
- mediaan
- modus
- variantie
- standaardafwijking
- Hoeveel observaties telt de dataset? (gebruik een functie)
- Wat is in deze dataset de kans dat DRP groter is dan \(30\)?
- Een continue variabele visualiseren. Beschouw opnieuw de DRP-dataset. We wensen de data te visualiseren.
- Visualiseer de data aan de hand van een groene boxplot.
- Verander het label van de y-as naar “Score voor DRP”
- Visualiseer de data aan de hand van een histogram.
- Is de verdeling symmetrisch?
- Zijn er outliers in de data?
- Een categorische variabele beschrijven. De dataset
inversion.csvbevat data over inversie in de West-Vlaamse dialecten.- Open de dataset in R
- Geef een numerieke samenvatting van de variabele
inversion(geobserveerde frequentie & proporties). - Geef een visuele samenvatting van de variabele
inversion
- De
Falsebeginnersdataset verkennen.- Open de dataset en geef de naam
fb - Vat alle variabelen samen met 1 functie
- Hoeveel rijen en kolommen bevat de dataset?
- Vat de variabelen
ThuistaalenGeslachtsamen. - Visualiseer de twee variabelen aan de hand van een barplot.
- Vat de variabele
PPVTsamen aan de hand van:- minimum
- 2e kwartiel
- mediaan
- gemiddelde
- 3e kwartiel
- maximum
- variantie
- standaardafwijking
- Bereken voor
PPVTde Median Absolute Deviation (MAD).
- Open de dataset en geef de naam
- Lexicale decisie. Bij een lexicale decisietaak moeten participanten zo snel mogelijk aanduiden of een woord een bestaand of onbestaand woord is. De reactiesnelheid wordt daarbij gemeten. Het
languageRpackage bevat de datasetlexdecmet lexicale decisiedata voor 79 Engelse naamwoorden die beoordeeld werden door 21 participanten.- laad het
languageRpackage via library(“languageR”) - vat de
lexdecsamen metsummary() - Geef een numerieke samenvatting van
RT(= Reactietijd). RTwerd getransformeerd via de logtransformatie. Gebruik de exponentiële functie om terug te transformeren naar de gemeten waarden.- Wat is de gemiddelde reactietijd? Interpreteer.
- Maak een histogram van de loggetransformeerde
RTen van de niet-getransformeerdeRT(dus na de exponentiële transformatie). Vergelijk beide verdelingen.
- laad het