345+342[1] 687In dit eerst hoofdstuk maak je kennis met de software R (R Core Team 2023) en de grafische user interface (“GUI”) RStudio. Wanneer je het programma R opent dan krijg je het lege venster in Figure 2.1 te zien. Er valt niets te pointen en te klikken en als je niets te zeggen hebt, dan gebeurt er ook niets. Een intimiderende ervaring. Enkel de ervaren R-experts zullen R op die manier nog gebruiken en zelfs zij zullen een R-script voorbereiden om het nadien te laten runnen in R.
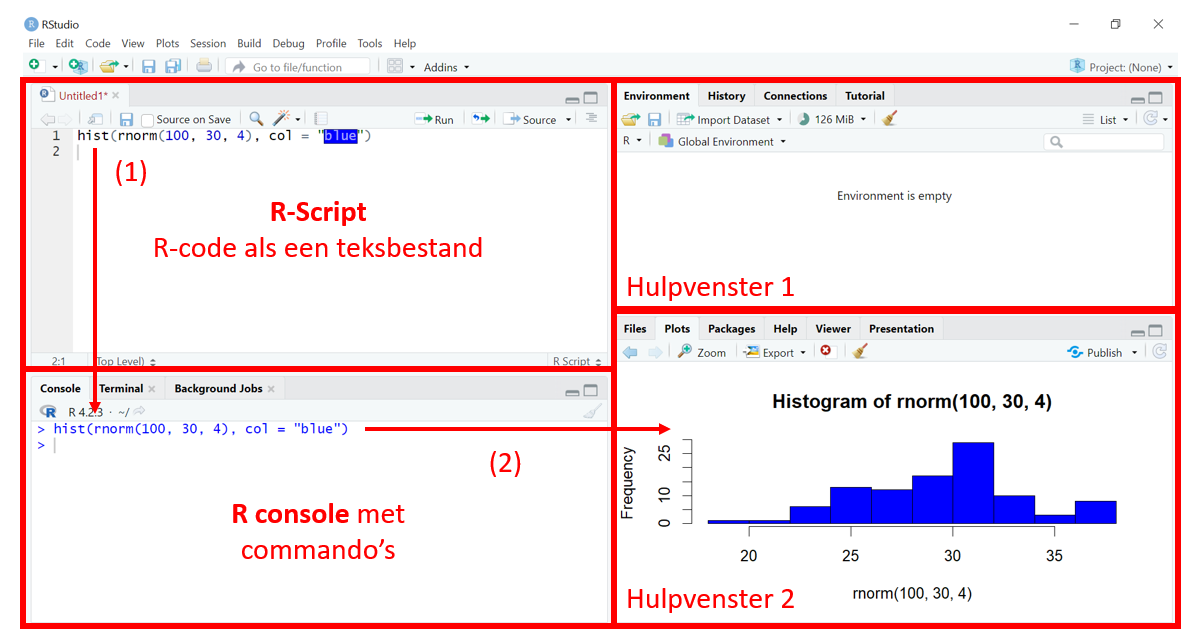
Tegenwoordig gebruiken de meeste onderzoekers de grafische interface RStudio. RStudio werd ontwikkeld en wordt nog steeds onderhouden door het bedrijf Posit (https://posit.co/). In R-studio krijg je vier vensters te zien, zoals in Figure 2.2. Links bovenaan schrijf je het R-script, een tekstbestand met de commando’s die je in R wil uitvoeren. Dat script wordt naar de console gestuurd, die het op zijn beurt evalueert. Hier maken we een figuur en die krijgen we onmiddellijk te zien in het hulpvenster met het tabblad “Plots”. Rechts bovenaan staat nog een hulpvenster met onder meer een tabblad met de geschiedenis van de commando’s die je hebt ingegeven en met een overzicht van de objecten en hun structuur in “Environment”.
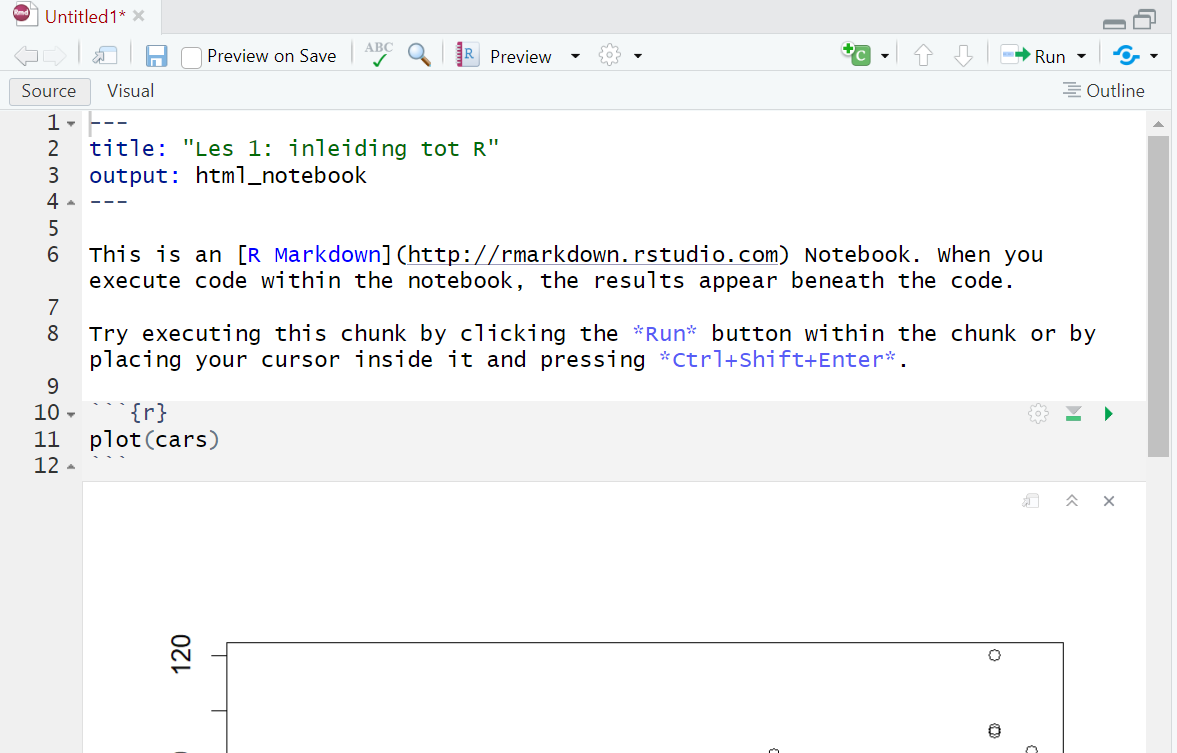
Sinds kort wordt er gewerkt met een R notebook. Daarbij krijg je code en output in één venster te zien zoals Figure 2.3. De R-console en het outputvenster met de plots worden daarbij (quasi) niet meer gebruikt. Een van de grote voordelen van een notebook is dat je naast je code en de output ervan ook gewone tekst met opmaak kunt schrijven en zelfs ook tabellen en figuren kunt toevoegen. Bovendien kun je het notebook weergeven als een pdf-, html- of Word-document. Ook slides zijn mogelijk (powerpoint, maar ook revealjs).
R leer je al doende, door code te schrijven en te herschrijven. Copy-pasten is goed, zelf schrijven is beter.
In dit eerste hoofdstuk werk ik stap voor stap uit hoe je R commando’s kunt geven, welke functies er bestaan en hoe je eenvoudige figuren kunt maken. Elke taal vergt oefening en herhaling. Je leert nieuwe woordenschat en syntaxis, maakt fouten, maar door veel code uit te proberen, zul je als statistische ontdekkingsreiziger vertrouwd raken met de wondere wereld van R.
Als eerste kennismaking gebruiken we R als een rekenmachine. Wat is de som van \(345\) en \(342\)? Schrijf onderstaande bewerking in de R console (het linker beneden venster in RStudio) en druk op enter:
345+342[1] 687Normaal gaan we niet rechtstreeks in de R console werken. We gebruiken daarentegen een R-script (File > New File > R script) of een R Notebook (File > New File > R notebook).
Een klein overzicht van de belangrijkste bewerkingen:
4-1[1] 34/2[1] 22^2 # twee tot de tweede macht[1] 4sqrt(4) # sqrt = square root of vierkantswortel[1] 2(34-4)+(5+4) # haakjes [1] 39pi # 3.1415...[1] 3.1415935^2 # 5 tot de tweede macht. [1] 25log(25,5) # logaritme van het grondtal 5 van 25[1] 2exp(2) # e^2 = 2.7182^2[1] 7.389056Merk op dat alles wat nat na “#” komt niet geëvalueerd wordt en als commentaar gebruikt wordt.
In R werken we vooral met functies. Een functie heeft een naam en argumenten: Naam(arg_1, arg_1, …). Heel eenvoudig uitgelegd: een functie “doet iets” met de argumenten. We wensen, bijvoorbeeld, het resultaat van het quotiënt \(25/6\) (= 4.1666667) af te ronden tot op twee cijfers na de komma. We gebruiken hiervoor de functie round():
[1] 4.17Strikt genomen hoeven we de namen van de argumenten (hier: “x=” en “digits=”) niet te schrijven, maar het maakt de code wel leesbaarder. Vergelijk bovenstaande code met deze hieronder. Beide geven hetzelfde resultaat, maar de eerste biedt meer informatie aan de gebruiker. Code documenteren is belangrijk om nadien nog te weten wat je gedaan hebt of wanneer iemand anders je code wil lezen.
round(25/6, 2)[1] 4.17We kunnen ook alle argumenten na mekaar schrijven, maar om de leesbaarheid van de R-code zo duidelijk mogelijk te houden, zal ik in de eerste drie hoofdstukken over R alle argumenten op een nieuwe lijn plaatsen en apart becommentariëren. Vergelijkbare functies zijn ceiling en floor.
ceiling(5.67) [1] 6floor(5.67)[1] 5Wanneer je R opent dan open je een aantal packages (soms vertaald naar “pakketten”, maar ik ben geen neologist en gebruik schroomloos de Engelse terminologie). Base-R is een van de packages die automatisch geopend worden. Naast base-R zijn er veel andere packages die door R-gebruikers werden geschreven en die een specifiek set aan functies en datasets bevatten. Om die andere packages te gebruiken, moet je die eerst installeren via install.packages() en daarna openen met library(). Hier installeren en openen we het package bayesplot (Gabry and Mahr 2022).
install.packages("bayesplot")
library("bayesplot")Nog gemakkelijker (maar minder repliceerbaar is via het tabblad Packages, waar je de gewenste pakketten kunt aanklikken (2 in Figure 2.4). Indien ze nog niet geïnstalleerd zijn, krijg je een dialoogvenster om dat wel te doen of je gebruikt eerst Install (1).
De assignment operator kent een naam toe aan een object.
1x <- 10R weet nu dat x de naam is voor de waarde \(10\). Wanneer we x evalueren dan krijgen we \(10\) als resultaat.
x[1] 10In feite gebruiken we hier de functie print(), maar die hoeven we niet te expliciteren:
print(x)[1] 10We kunnen nu x gebruiken in plaats van \(10\):
x+9[1] 19Het is ook mogelijk om zelf functies te schrijven. Hier maken we een functie om het kwadraat van een getal te berekenen.
kwad <- function(x){x^2}We passen onze functie toe op een vector van getallen.
kwad(c(1,2,3,4,5))[1] 1 4 9 16 25In dit handboek werken we met bestaande functies.
Een van de belangrijkste objecten in R is de vector, een rij van gelijksoortige gegevens (bvb. allemaal numerieke objecten, allemaal integers, allemaal characters). We maken een vector van 5 getallen en geven die de naam mydata:
mydata <- c(4,6,8,2,7)
mydata[1] 4 6 8 2 7Om een vector te maken van getallen gebruiken we de functie c(), wat staat voor “concatenate” of samenvoegen.
Hoeveel elementen bevat mydata? Of, met andere woorden, hoe lang is de vector mydata?
length(mydata)[1] 5R werkt vectorieel. We kunnen elke observatie in mydata optellen met \(3\):
mydata+3[1] 7 9 11 5 10Dit lijkt logisch, maar in andere programmeertalen zou je daarvoor een loop moeten schrijven om te zeggen dat elke observatie uit de vector met 3 moet vermeerderd worden.
Je kunt ook een vector van woorden maken:
vrienden <- c("Beatrijs", "Fatemeh", "Leo", "Astrid", "Lize")Dit is een zogenaamde “character vector”
str(vrienden) chr [1:5] "Beatrijs" "Fatemeh" "Leo" "Astrid" "Lize"Hoeveel vrienden zijn er?
length(vrienden)[1] 5We maken een vector of variabele met de naam WordsPerSentence.
WordsPerSentence<-c(12,3,34,23,23,34,12,23,12,
23,34,23,12,23,34,23,26,27) En we passen enkele functies uit base-R toe op onze vector:
max(WordsPerSentence) # maximum[1] 34min(WordsPerSentence) # minimum [1] 3sum(WordsPerSentence) # som[1] 401mean(WordsPerSentence) # gemiddelde[1] 22.27778median(WordsPerSentence) # mediaan[1] 23range(WordsPerSentence) # bereik (max - min)[1] 3 34var(WordsPerSentence) # variantie [1] 81.38889sortedorder<-sort(WordsPerSentence) # gesorteerde vector
order(WordsPerSentence) # volgorde [1] 2 1 7 9 13 4 5 8 10 12 14 16 17 18 3 6 11 15fivenum(WordsPerSentence) # vijfgetallensamenvatting[1] 3 12 23 27 34summary(WordsPerSentence) # samenvatting Min. 1st Qu. Median Mean 3rd Qu. Max.
3.00 14.75 23.00 22.28 26.75 34.00 We noteerden het opleidingsniveau van 10 personen:
Opleiding <-c("middelbaar",
"middelbaar",
"bachelor",
"middelbaar",
"bachelor",
"master",
"master",
"master",
"middelbaar",
"master") Opleiding is nu een charactervector. We moeten die eerst omzetten naar een factorvariabele. De verschillende namen worden dan categorieën (“levels”) waar R mee kan werken.
Opleiding <- as.factor(Opleiding)
str(Opleiding) Factor w/ 3 levels "bachelor","master",..: 3 3 1 3 1 2 2 2 3 2Opleiding is nu een factor met drie categorieën of levels. R kent automatisch een numerieke waarde toe aan de levels om achter de schermen bewerkingen uit te voeren. De numerieke waarden worden toegekend om basis van de alfabetische volgorde van de levels. Hoeveel observatie hebben we voor elke categorie?
table(Opleiding) Opleiding
bachelor master middelbaar
2 4 4 Proporties of relatieve aantallen berekenen we met de prop.table() functie.
prop.table(table(Opleiding))Opleiding
bachelor master middelbaar
0.2 0.4 0.4 In R geven we ontbrekende waarden aan met NA:
RT <- c(345, 367, 440, 438, NA, 500, 270)Hoeveel ontbrekende waarden zijn er?
is.na(RT)[1] FALSE FALSE FALSE FALSE TRUE FALSE FALSEis.na() is een logische functie. Voor een lange vector kunnen we niet alles lezen. We kunnen dan de functie which() toevoegen:
which(is.na(RT))[1] 5De vijfde waarde uit de vector is een ontbrekende waarde. Maar hoeveel zijn er nu?
length(which(is.na(RT)))[1] 1Naast is.na() zijn er nog een aantal andere praktische logische operatoren.
Is \(5\) groter dan \(3\)?
5 > 3[1] TRUEIs \(x\) kleiner dan \(y\)?
x <- 5
y <- 16
x < y [1] TRUEAndere logische operatoren:
x <= 5 # kleiner of gelijk aan [1] TRUEy >= 20 # groter of gelijk aan[1] FALSEy == 16 # gelijk aan[1] TRUEx != 5 # verschillend van[1] FALSEMet vierkante haakjes kunnen we elementen selecteren op basis van hun plaats in de vector. We maken eerst een vector van 3 elementen en vragen vervolgens wat het derde element is.
score <- c(18, 12, 17)
score[3][1] 17Let op de vierkante haakjes.
We openen de vector letters (de letters van het alfabet zitten standaard in R) en geven die de naam alfabet.
alfabet <- letters # letters is een ingebouwd object in R
alfabet [1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s"
[20] "t" "u" "v" "w" "x" "y" "z"Andere selecties met de indexoperator
alfabet[3:5] # de 3e tot de 5e letter van het alfabet[1] "c" "d" "e"alfabet[c(8,5,12,12,15)] # hallo - gebruik c()! [1] "h" "e" "l" "l" "o"alfabet[-1] # laat het eerste element weg [1] "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s" "t"
[20] "u" "v" "w" "x" "y" "z"alfabet[-c(1,3)] # laat het eerste en het derde element weg [1] "b" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s" "t" "u"
[20] "v" "w" "x" "y" "z"We maken een vector met de nummers van \(1\) tot \(20\). We kunnen daarvoor de “:” als operator gebruiken.
numbers<-1:20 Wat is de som van alle nummers kleiner dan \(5\)?
sum(numbers[numbers<5]) [1] 10Hoeveel nummers zijn er groter dan \(15\)?
length(numbers[numbers>15])[1] 5R beschikt over functies om tekst (of beter “strings”) te bevragen en te manipuleren. Deze functies worden gebruikt in de textmining. Hieronder enkele functies uit base-r. Dit overzicht is slecht bedoeld als teaser. Voor complexere analyses gebruik je stringr (Wickham 2022) en quanteda (Benoit et al. 2018).
We schrijven een zin en veranderen alle hoofdletter naar kleine letters (zie ook de omgekeerde functie toupper()).
mijnzin <- "Met R wou Jan De Smet een toponderzoeker worden"
mijnzin <- tolower(mijnzin)
mijnzin[1] "met r wou jan de smet een toponderzoeker worden"We splitsen de zin in een vector met aparte woorden (“tokenizen”). We kunnen dit doen op basis van de spaties tussen de woorden.
mijnzin <- strsplit(x = mijnzin, split = " ")
mijnzin[[1]]
[1] "met" "r" "wou" "jan"
[5] "de" "smet" "een" "toponderzoeker"
[9] "worden" De zin is nu een lijst geworden:
str(mijnzin)List of 1
$ : chr [1:9] "met" "r" "wou" "jan" ...Met unlist() transformeren we de lijst naar een vector.
unlist(mijnzin)[1] "met" "r" "wou" "jan"
[5] "de" "smet" "een" "toponderzoeker"
[9] "worden" Met chartr() vervangen we een karaker in een string.
We korten alle strings af in 4 karakters.
steden <- c("Gent", "Antwerpen", "Brussel", "Henegouwen")
abbreviate(names.arg = steden,
minlength = 4) Gent Antwerpen Brussel Henegouwen
"Gent" "Antw" "Brss" "Hngw" We halen het eerste tot en met vierde karakter uit de woorden voor de steden.
substr(steden,
start = 1,
stop = 4)[1] "Gent" "Antw" "Brus" "Hene"Stel dat we alle woorden met “top” uit een corpus zouden willen halen. Eerst zorgen we dat we alle woorden in het corpus verzamelen als een vector. Vervolgens zoeken we naar woorden met “top”.
grep(pattern = "top", x = c("Mijn", "topcollega", "Jan","wil",
"een", "toponderzoeker", "worden"), value = TRUE)[1] "topcollega" "toponderzoeker"Een van de grote sterktes van R is dat we de programmeertaal kunnen gebruiken om simulaties uit te voeren. We hoeven een experiment dus niet uit te voeren, maar kunnen doen alsof. Dit is tegenwoordig een belangrijke stap in het empirisch onderzoeksproces omdat we kunnen onderzoeken of de verwachtingen enigszins steek houden. Het nemen (of creëren) van een steekproeven is daarbij een van de basisstappen. We verzinnen hier een dataset van \(N = 10\) elementen waaruit we vervolgens een aselecte steekproef nemen van 5 elementen.
[1] 78 78 33 65 12We kunnen ook samplen met teruglegging:
muntstuk<-c("kop","munt")
sample(x = muntstuk,
size = 20,
replace=TRUE) [1] "kop" "kop" "kop" "munt" "munt" "kop" "munt" "kop" "kop" "munt"
[11] "kop" "kop" "kop" "munt" "munt" "munt" "kop" "munt" "munt" "kop" We simuleerden hier twintig keer het opgooien van een muntstuk: er zijn slechts twee mogelijkheden: kop of munt. Beide kanten hebben evenveel kans (\(50\%\) of \(0.50\)). Maar stel nu dat we een binaire variabele hebben waarbij een van de waarden met \(70\%\) kans optreedt, dan kunnen we dat via het argument prob aangeven.
data<-c(0,1)
sample(x = data,
size = 20,
prob = c(0.30, 0.70),
replace=TRUE) [1] 1 1 1 0 1 1 1 1 1 0 1 1 1 1 0 0 1 1 1 1We nemen nu een steekproef uit een normale verdeling (zie hoofdstuk 7), meer bepaald een aselecte steekproef van \(N = 20\) observaties uit een normale verdeling met gemiddelde \(\mu=4.5\) en een standaardafwijking \(\sigma=2\).
[1] 5.132197 5.394955 3.338932 7.615008 1.163836 6.555446 7.346246 2.461835
[9] 3.978325 7.271536 5.355511 2.636937 8.368387 6.197859 5.673482 2.963420
[17] 5.818484 2.273418 4.163873 3.942191We bekijken hier enkele eenvoudige basisfiguren. De code is uit pedagogische overwegingen bewust vrij minimalistisch gehouden, waardoor er zeker esthetische verbeteringen mogelijk zijn. Die komen later nog aan bod.
Figure 2.5 is gemaakt met misschien wel de simpelste code in R, en met dank aan Norman Matloff voor de inspiratie (https://github.com/matloff/fasteR):
hist(Nile)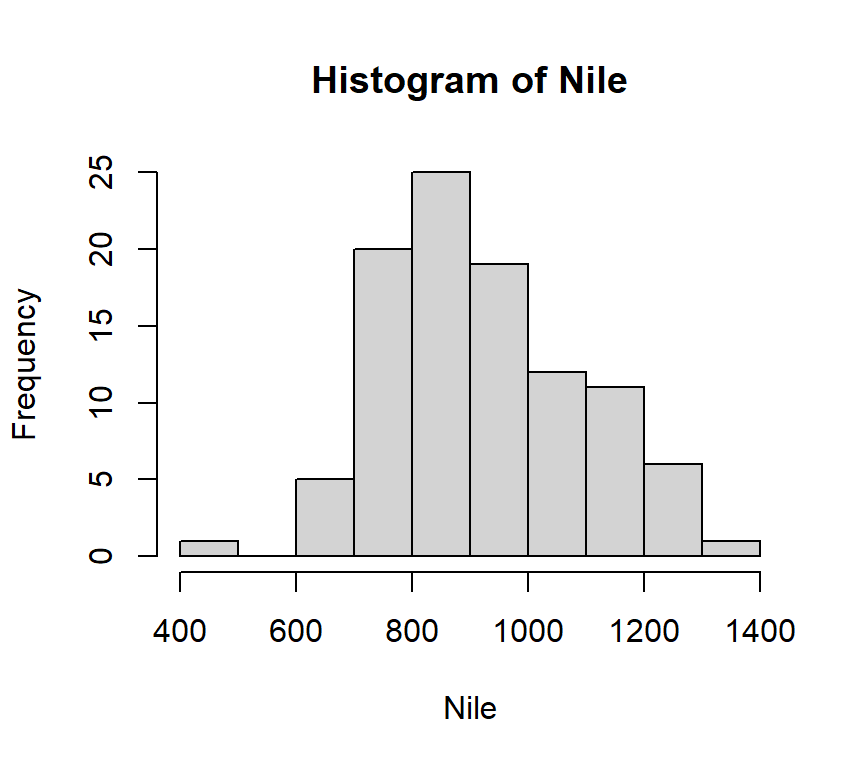
Nile is een dataset uit het base-R package en R weet perfect hoe deze dataset gevisualiseerd moet worden met een histogram. Hier zie je hoe R als statistische programmeertaal pur sang werd ontwikkeld.
We maken nu een histogram op basis van een dataset die we eerst zelf creëren. We maken een continue variabele Reactiesnelheid, met \(N=1000\) observaties die we samplen uit een normale verdeling. We gaan uit van een gemiddelde reactiesnelheid van \(300\,ms\) en een standaardafwijking van \(10\,ms\). Vervolgens passen we de hist() functie toe op ons object Reactiesnelheid en verkrijgen Figure 2.6.
1Reactiesnelheid <- rnorm(n = 1000, mean = 300, sd = 10)
2hist(Reactiesnelheid,
3 main = "",
4 ylab = "Frequentie",
xlab = "Reactiesnelheid (ms)")Reactiesnelheid
hist() toe en het eerste argument is het object dat we willen visualiseren
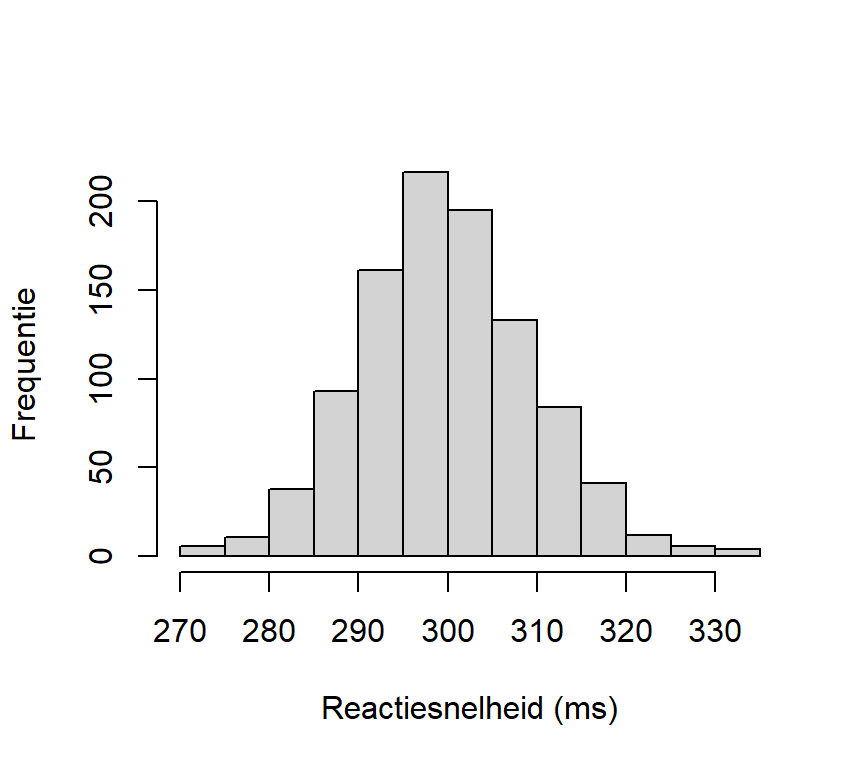
Figure 2.7 toont dezelfde data aan de hand van een densiteitscurve.
1densRT <- density(Reactiesnelheid)
2plot(densRT,
main = "",
ylab = "Kansdichtheid",
xlab = "Reactiesnelheid (ms)") 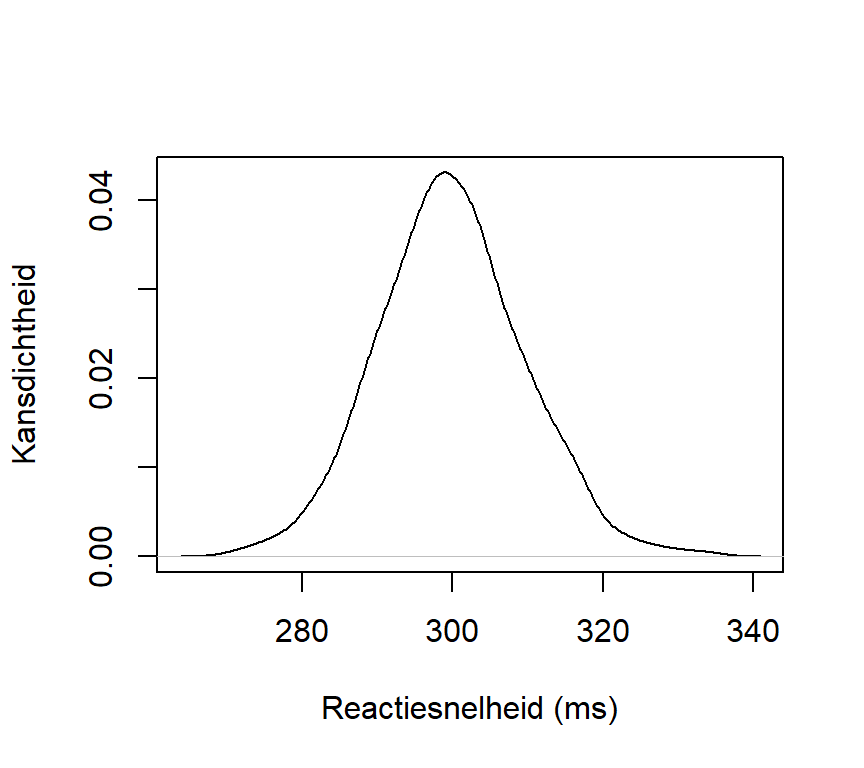
Figure 2.8 visualiseert Reactiesnelheid aan de hand van een boxplot. De boxplot is gebaseerd op de locatiematen minimum, eerste kwartiel, mediaan, derde kwartiel, en het maximum. Outliers worden als bolletjes weergegeven.
boxplot(Reactiesnelheid,
ylab = "Reactiesnelheid (ms)") 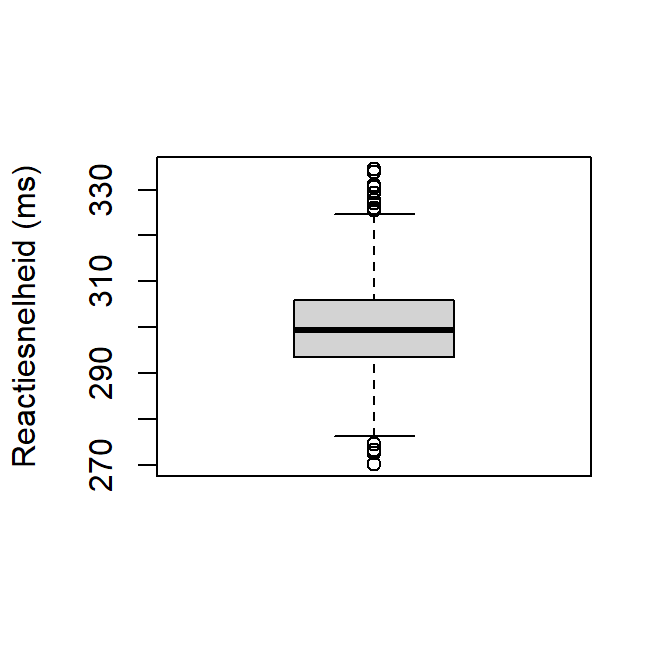
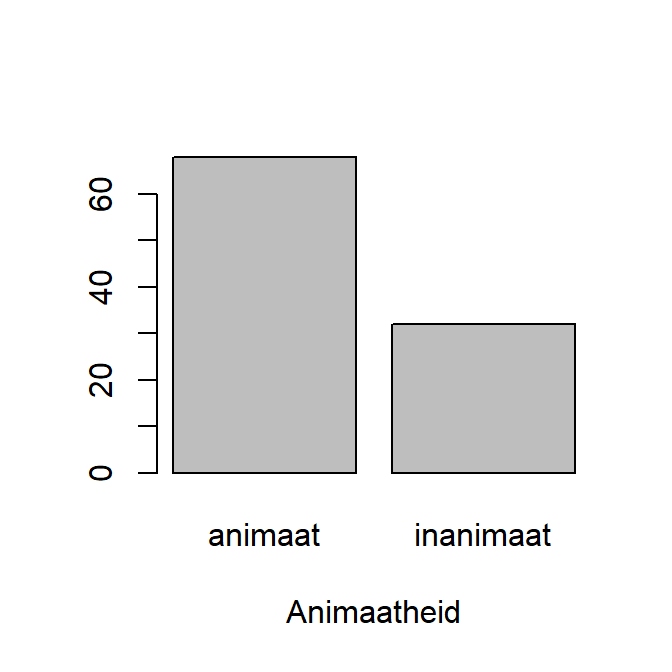
We maken eerste een vector “Animacy” met twee waarden “animate” en “inanimate” met de rep() functie.
Nu volgt een belangrijke stap: om een staafdiagram te maken, moet je altijd eerst de variabele samenvatten, waarbij je de frequentie voor elke waarde berekent.
tt <- table(Animaatheid) Vervolgens kunnen we de barplot() functie toepassen op tt en we verkrijgen Figure 2.9.
Beschouw de dataset in Table 2.1.
| ID | Pretest | Posttest |
|---|---|---|
| 1 | 13 | 15 |
| 2 | 8 | 9 |
| 3 | 11 | 16 |
| 4 | 12 | 13 |
| 5 | 16 | 17 |
| 6 | 15 | 17 |
| 7 | 11 | 12 |
| 8 | 6 | 10 |
| 9 | 10 | 13 |
| 10 | 14 | 15 |
We wensen het verband tussen de pre- en posttestscores te visualiseren aan de hand van een scatterplot (“spreidingsdiagram”). We creëren eerst twee vectoren voor beide scores en gebruiken vervolgens de plot() functie, waarbij we de x- en y-as aanduiden. Figure 2.10 toont het resultaat in al zijn eenvoud.
1Pretest <- c(13, 8, 11, 12, 16, 15, 11, 6, 10, 14)
Posttest <- c(15, 9, 16, 13, 17, 17, 12, 10, 13, 15)
2plot(x = Pretest, y = Posttest,
3 xlab = "Score Pretest",
ylab = "Score Posttest")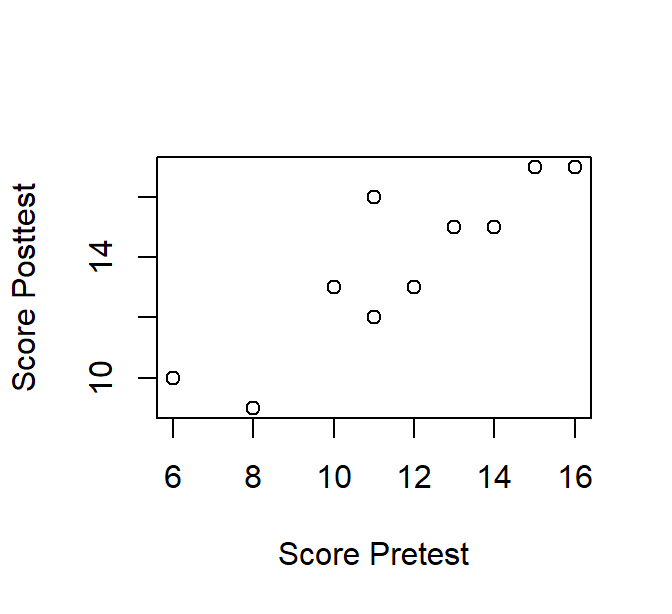
Om het lineair verband tussen de twee variabelen visueel samen te vatten, voegen we een regressielijn toe met abline() met daarin genesteld de lm()functie om een linear model te fitten. R “weet” wat er verwacht wordt. Merk op hoe “genereus” R is: we hoeven amper code te schrijven om Figure 2.11 te creëren.
plot(x = Pretest, y = Posttest,
xlab = "Score Pretest",
ylab = "Score Posttest")
abline(lm(Posttest ~ Pretest)) 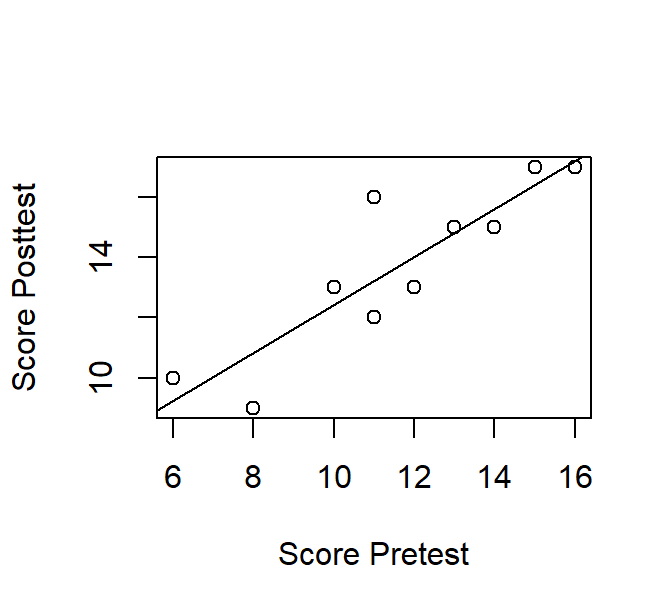
Beschouw de functie in Equation 2.1 (We kunnen die functie ook schrijven als \(y=3+2x\)).
\[ f(x)=3+2x \tag{2.1}\]
Dit is een eerstegraadsfunctie met 1 onbekende \(x\). Laten we even een paar waarden van \(x\) evalueren:
\[ \begin{split} f(-1)&: y=3+2(-1)=1\\ f(0)&: y=3+2(0)=3\\ f(1)&: y=3+2(1)=5\\ f(2)&: y=3+2(2)=7\\ \end{split} \tag{2.2}\]
Table 2.2 geeft de waardentabel:
| x | f(x) |
|---|---|
| -1 | 1 |
| 0 | 3 |
| 1 | 5 |
| 2 | 7 |
In de waardentabel hebben we maar een paar gehele getallen geëvalueerd, maar we kunnen ook alle reële getallen binnen een domein evalueren. We visualiseren Equation 2.1 voor het domein \([-3,+3]\) aan de hand van de curve() functie. Het resultaat is de rechte in Figure 2.12.
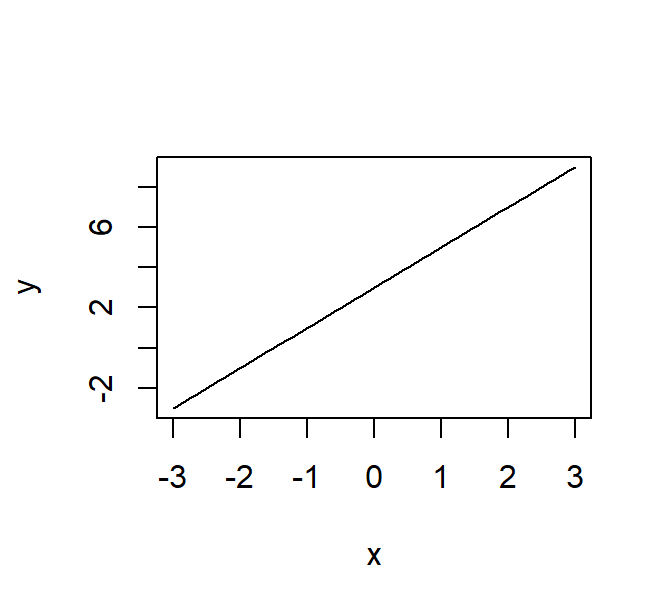
De eerstegraadsvergelijking in Equation 2.3 heeft altijd de vorm van een rechte.
\[ f(x)= a+bx \tag{2.3}\]
De twee getallen \(a\) en \(b\) heten respectievelijk het intercept en de richtingscoëfficiënt.
We komen terug op de eerstegraadsfunctie in Hoofdstuk 12 over de lineaire regressie.
We tekenen in Figure 2.13 nog enkele andere basisfuncties ter illustratie.
curve(expr = 3 + 4*x + 2*x^2,
from = -10, to = 10,
xlab = "x",
ylab = "y")
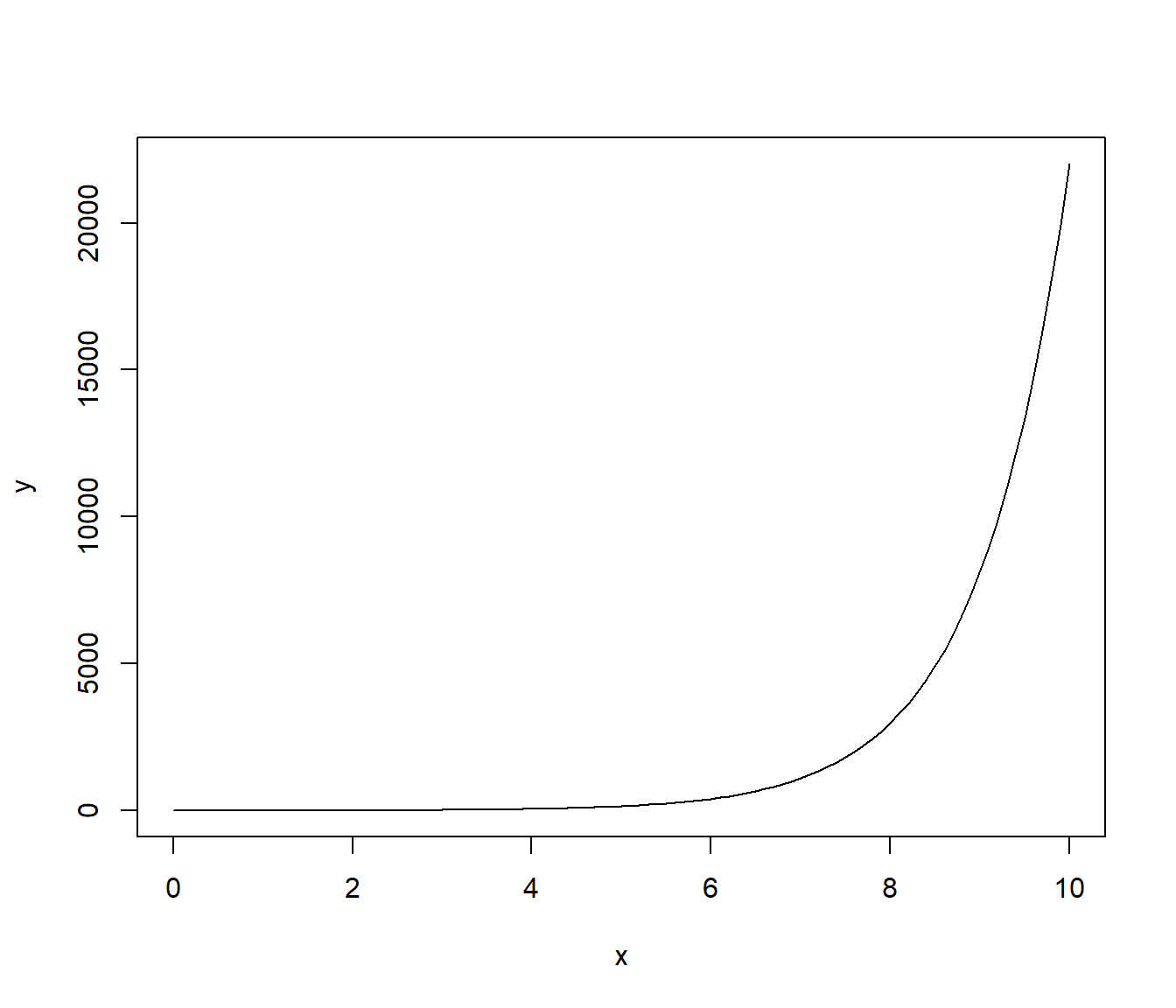
curve(expr = exp(x),
from = 0, to = 10,
xlab = "x",
ylab = "y")
curve(expr = log(x = x),
from = 0, to = 10,
xlab = "x",
ylab = "y")
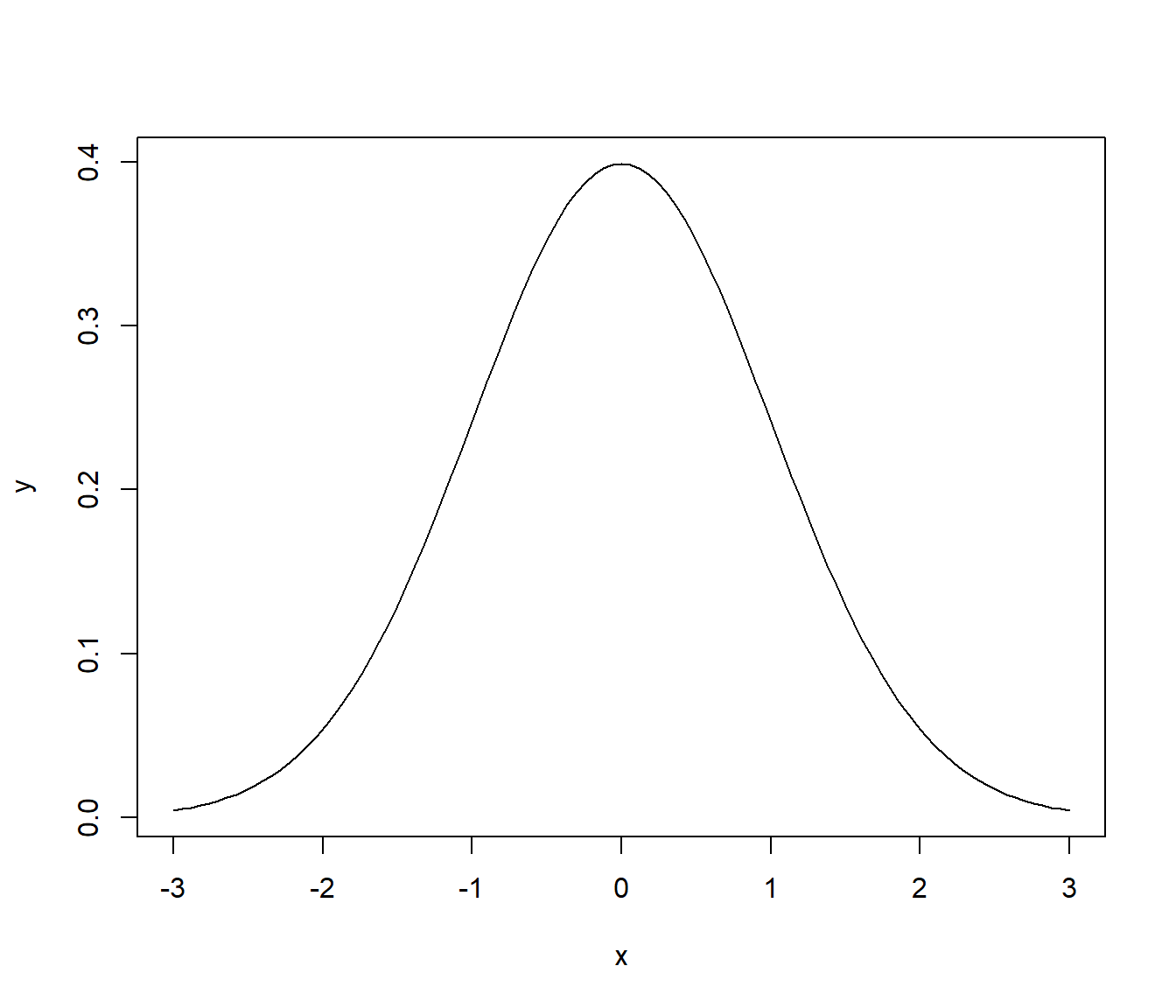
curve(dnorm(x),
from = -3, to = 3,
xlab = "x",
ylab ="y")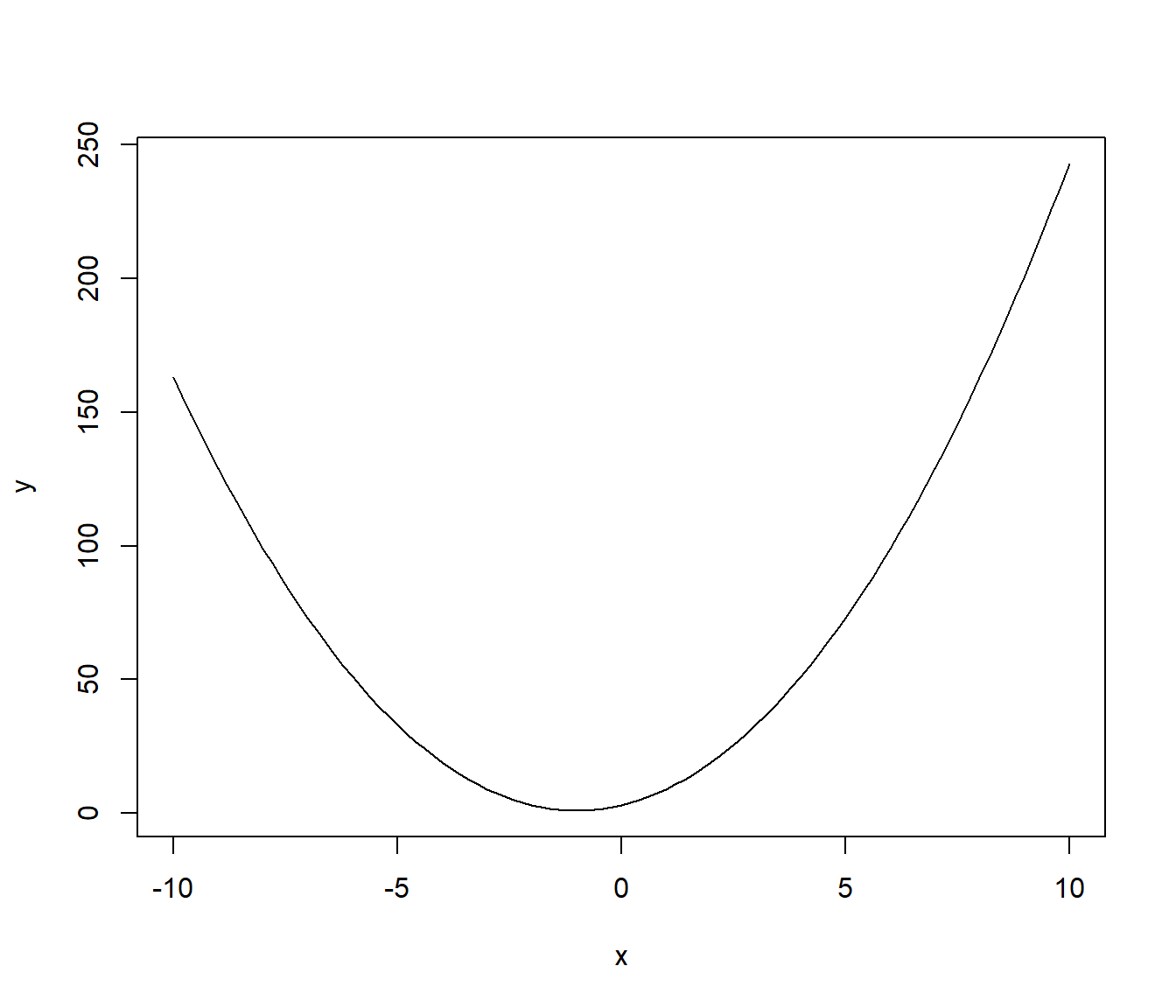
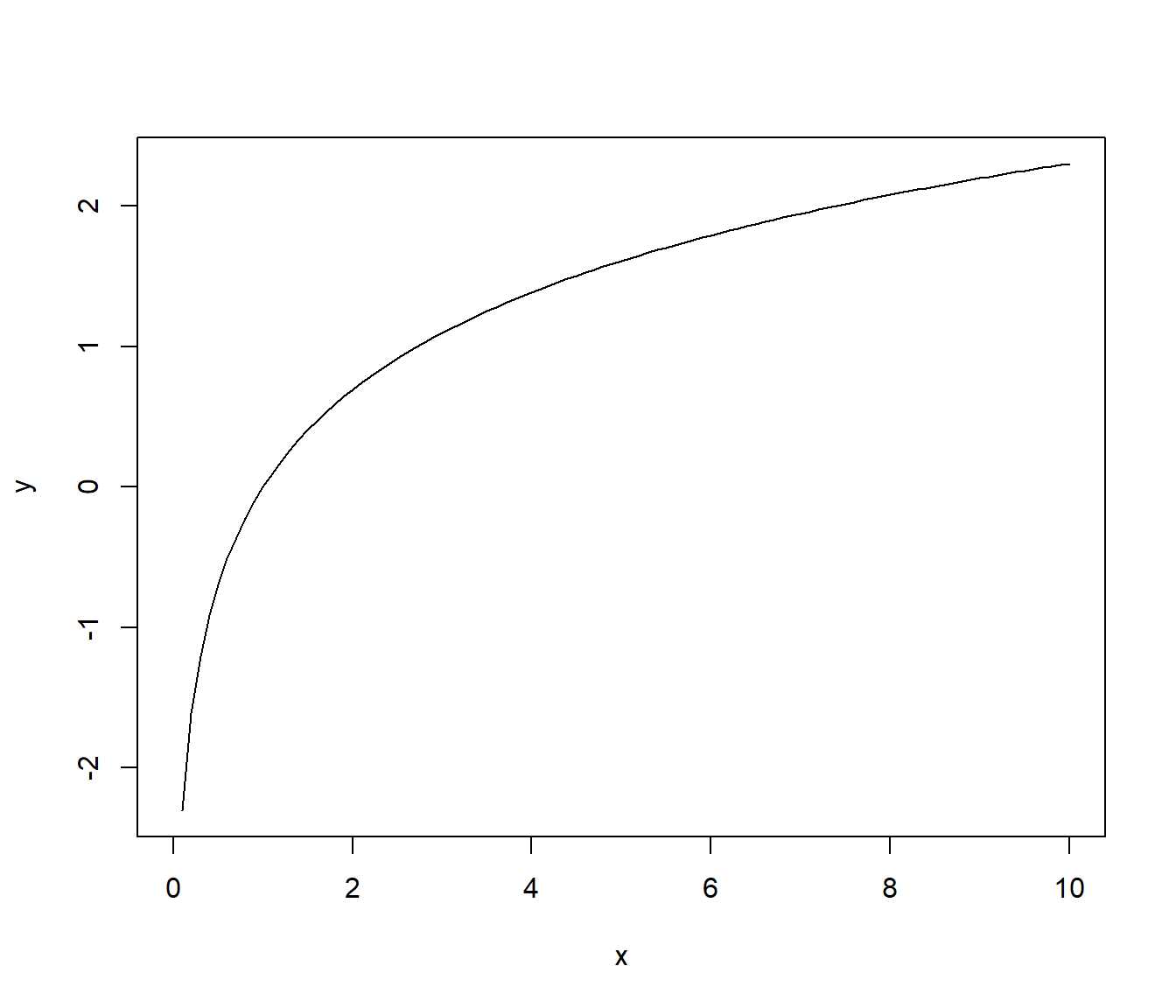
In R verwijst log() naar de natuurlijke logaritme of de Neperse logaritme, de logaritme met grondtal het getal van Euler \(e\) (2.7182…).
Dit was een eerste kennismaking met R en RStudio. Al is dit nog maar het topje van de ijsberg, we hebben toch al een mooie lijst met functies, die ik hieronder nog eens op lijst. We zullen deze lijst in de volgende hoofdstukken stelselmatig aanvullen. In het volgende hoofdstuk maak je kennis met het werkpaard van de statistiek: de dataframe, wat R’s datasetobject is. In hoofdstuk 4 en 5 breiden we de R-taal verder uit met een extra variant: tidyverse en het visualisatiepackage ggplot2. Vanaf dan beschik je over voldoende basiskennis in R om aan het echte werk te beginnen.