7 De normale verdeling
In het vorige hoofdstuk hebben we de verdeling van steekproeven onderzocht via numerieke samenvattingen en visualisaties. Maar in de wetenschappen nemen of creëren we een steekproef omdat we eignelijk een uitspraak wensen te doen of tot een inzicht wensen te komen over een populatie. In dit hoofdstuk maken we kennis met een populatieverdeling voor een continue variabele, met name de normale verdeling. We weten al dat een verdeling gelijk is aan de mogelijke waarden die een variabele kan aannemen en met welke frequentie of waarschijnlijkheid. De normale verdeling is een wiskundige functie die de waarden afbeeldt op hun waarschijnlijkheid.
De normale verdeling is slechts een van de vele verdelingen die in de statistiek gebruikt worden. In deze cursus maken we verder ook nog kennis met de t-verdeling, de chi-kwadraatverdeling en de F-verdeling. Ik begin met de normale verdeling omdat die vrij intuïtief te begrijpen is en omdat we de basisgedachte gemakkelijk uit te breiden is naar andere verdelingen.
Twee kernbegrippen die we in dit hoofdstuk op basis van de normale verdeling uitdiepen, vormen de fundamenten voor alles wat je ooit zult leren in de statistiek:
- kritische waarde
- cumulatieve proportie
Wanneer je deze twee concepten begrijpt, ben je klaar om aan het echte werk te beginnen.
7.1 Wat is een normale verdeling?
We namen al een steekproef uit een normale verdeling met een bepaald gemiddelde en een bepaalde variantie. Figure 7.1 toont wat er gebeurt als we de steekproeven vergroten.
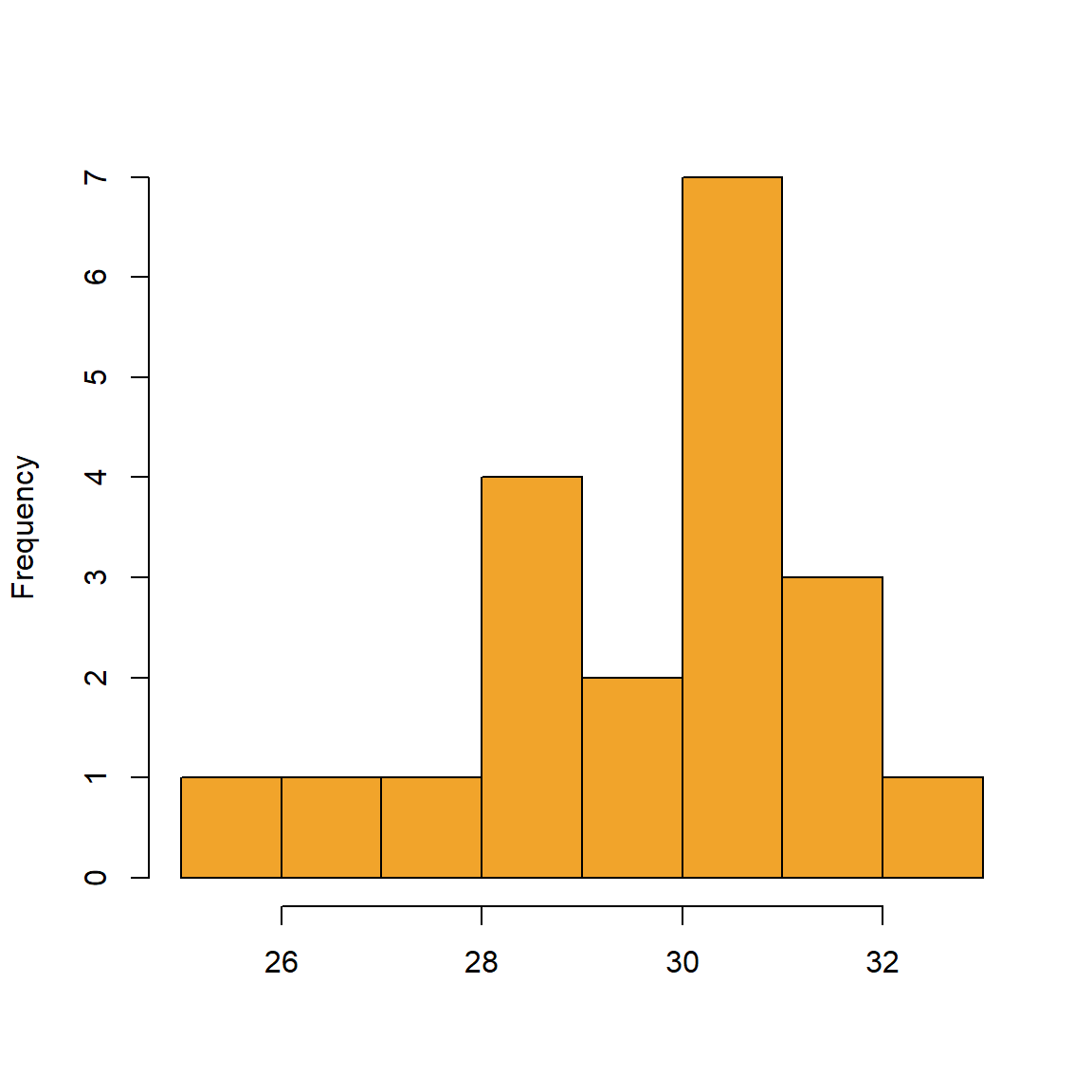
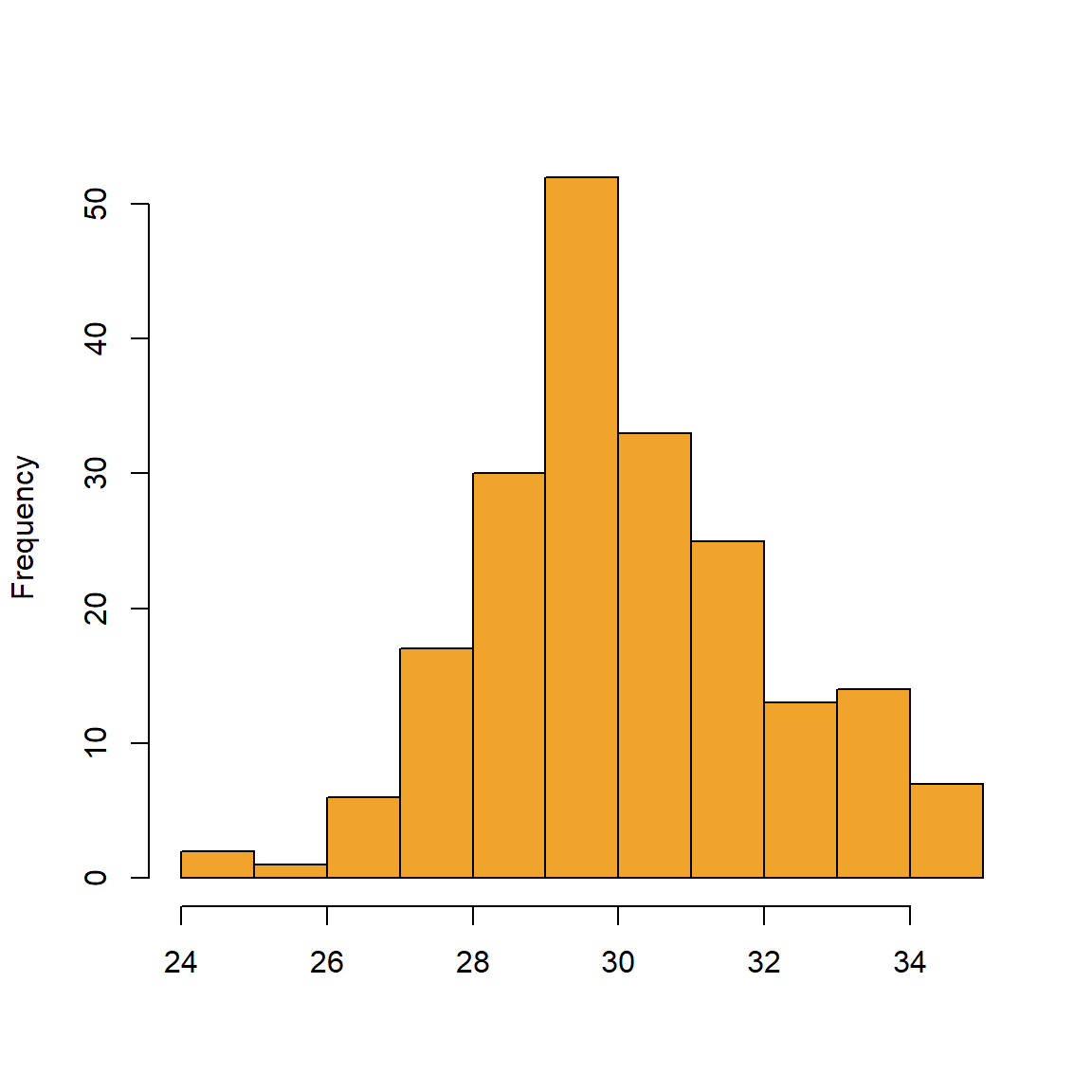
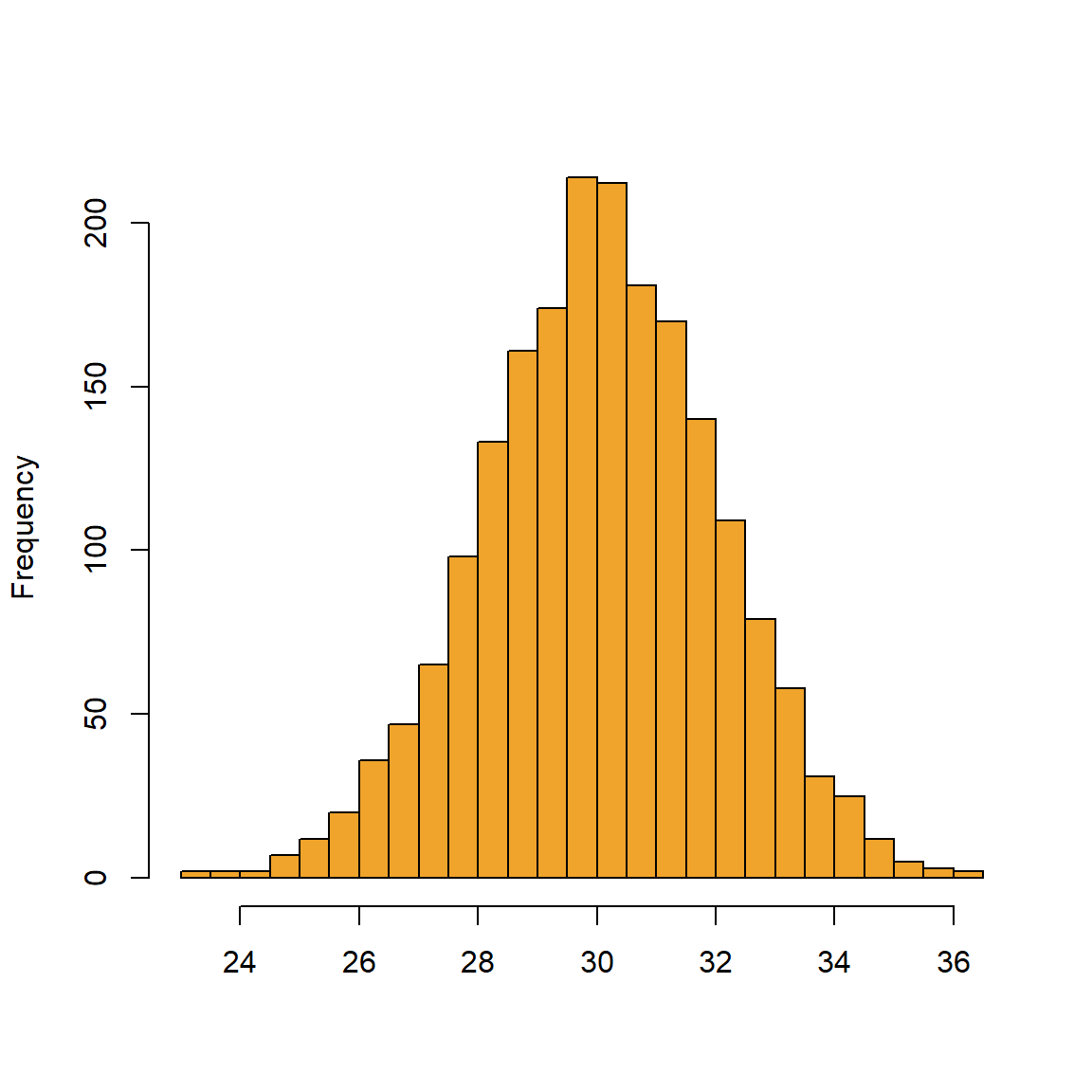
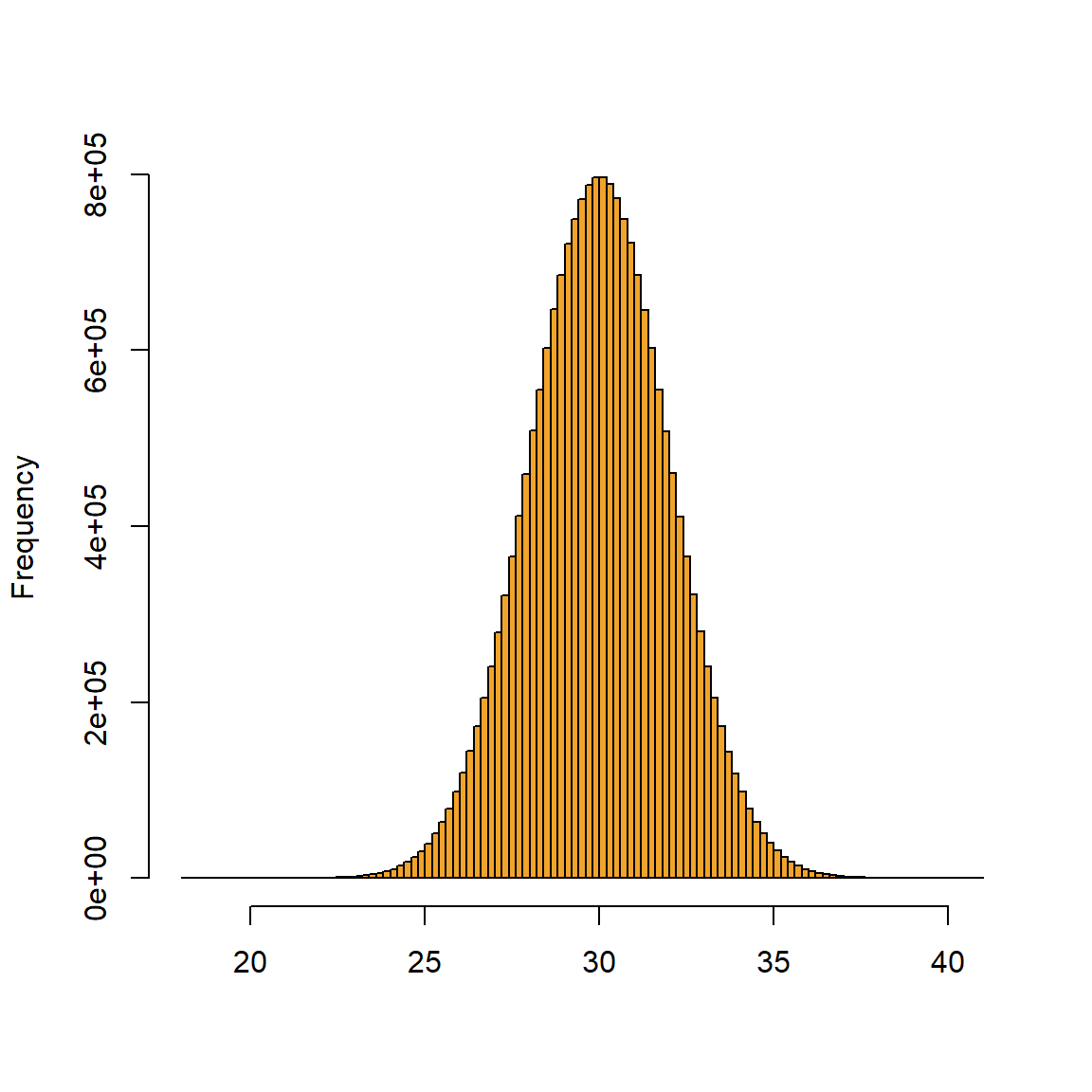
Naarmate de steekproeven groter worden, benadert het histogram een klokcurve of een normale verdeling (of Gausscurve), zoals voorgesteld in Figure 7.2.
In hoofdstuk 6 zagen we dat een verdeling een combinatie is van waarden en hun frequentie. Een normale verdeling is een continue verdeling die in principe alle mogelijke waarden kan aannemen afhankelijk van het fenomeen dat onderzocht wordt. De verdeling is symmetrisch en heeft als verwachte waarde het gemiddelde van de verdeling, die we \(\mu\) noemen. De verdeling heeft als standaardafwijking \(\sigma\). Symbolisch wordt de normale verdeling als volgt genoteerd.
\[ X \sim N(\mu,\sigma^2) \] We lezen: “\(X\) is een normaal verdeelde variabele met gemiddelde \(\mu\) en variantie \(\sigma^2\)”.
De kansdichtheid of densiteit van de normale verdeling wordt weergegeven door de functie in Equation 7.1:
\[ f(x)=\frac{1}{\sigma \sqrt{2\pi}}e^{-\frac{1}{2}\left(\frac{x-\mu}{\sigma}\right)^2} \tag{7.1}\]
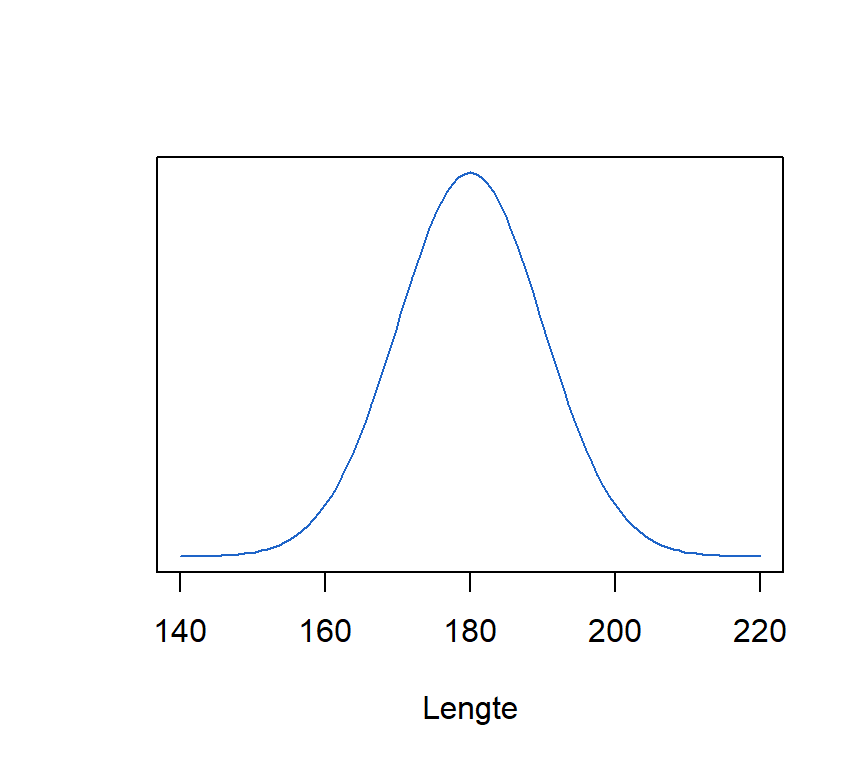
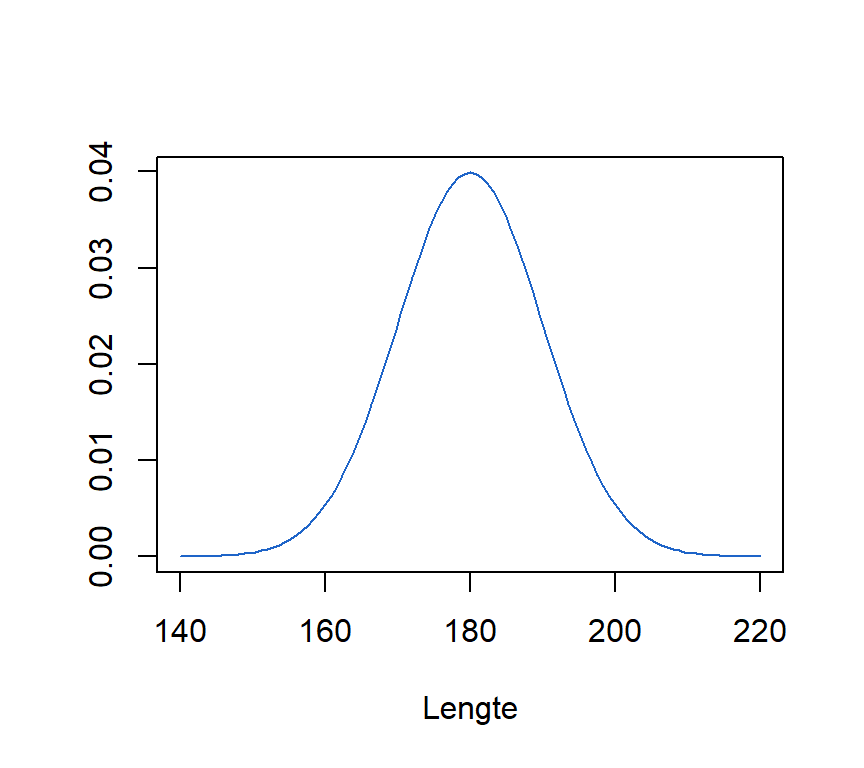
We kunnen de uitkomst van deze functie visualiseren door een gemiddelde \(\mu\) en standaardafwijking \(\sigma\) te kiezen en de functie voor alle waarden \(x\) tussen en te evalueren. Met parameters \(\mu = 180\) en \(\sigma = 10\) krijgen we voor de waarden \(x\) tussen 140 en 220, de figuur in Figure 7.2:
De X-waarden met als interval \(x = [140,220]\) zijn de inputwaarden, en de waarden op de blauwe lijn \(f(x)\) of \(y\) is de outputwaarden van de functie. De curve toont de verdeling van de variabele \(X\), die normaal verdeeld is, met parameters \(\mu = 180\) en \(\sigma = 10\).
Hoe hoger de blauwe lijn, hoe waarschijnlijker de observatie. De centrale waarden rond \(180\) zijn dus waarschijnlijker dan de observaties in de staarten. Hoe verder verwijderd van het centrum, hoe minder waarschijnlijk de observaties worden.
De meeste observaties vinden we rond het gemiddelde \(\mu=180\). Heel kleine (lager dan \(150\)) of heel grote waarden (hoger dan \(220\)) zijn veel minder waarschijnlijk. We kunnen dit ook interpreteren als kansen. Hoe verder van het centrum verwijderd, hoe kleiner de kans op een observatie. Verder in dit hoofdstuk zullen we zien hoe we deze kansen kunnen berekenen. Het berekenen van deze kansen is één van de kerngedachten in de statistiek.
Heel wat natuurlijke verschijnselen blijken een normale verdeling te benaderen, wat een van de verklaringen is voor het belang van de normale verdeling voor de statistiek.
Figure 7.3 toont wat er gebeurt als we het gemiddelde veranderen.
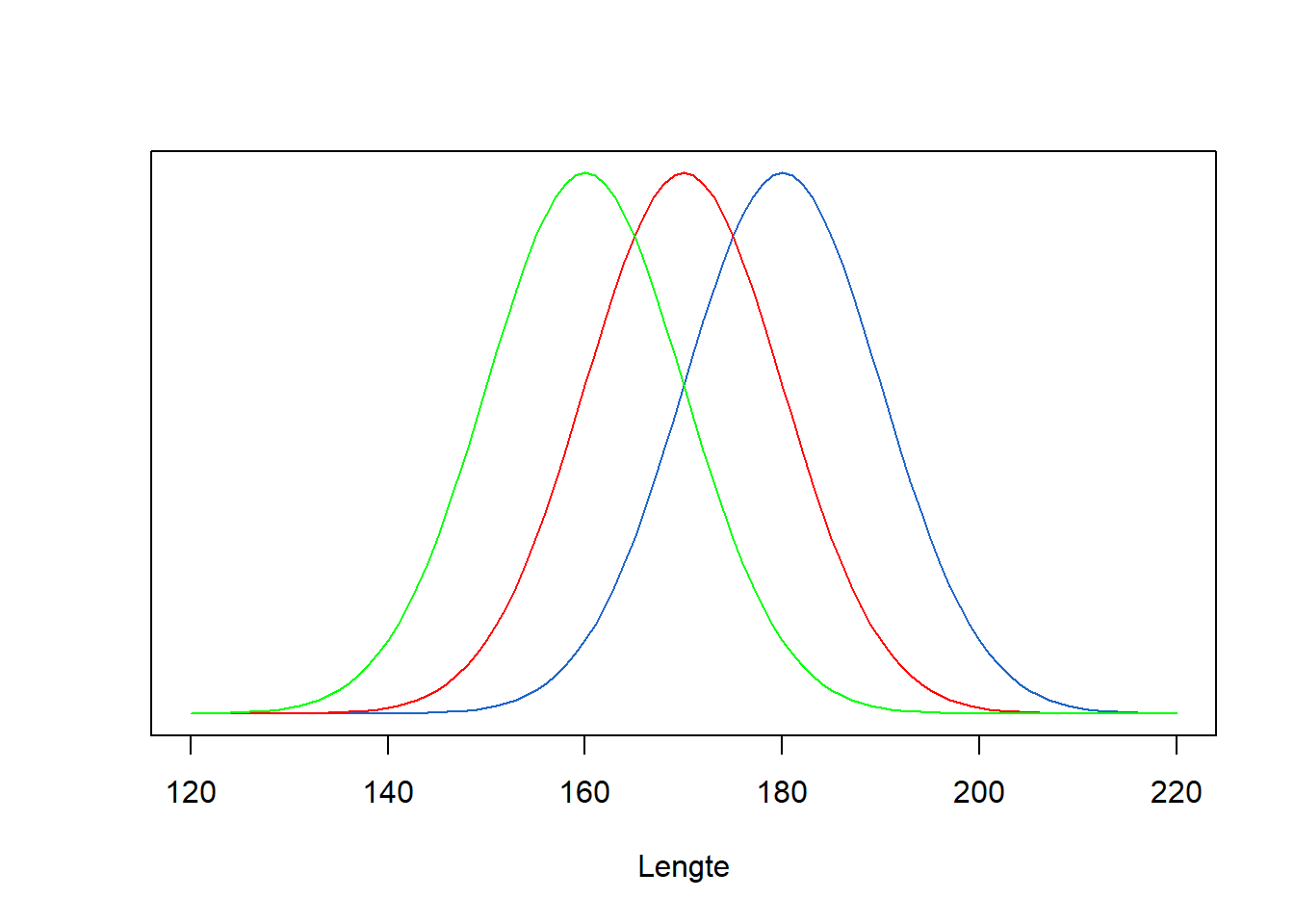
Het centrum verschuift maar de vorm van de verdeling blijft gelijk. Wanneer we \(\sigma\) veranderen, verandert de spreiding, zoals Figure 7.4 illustreert.
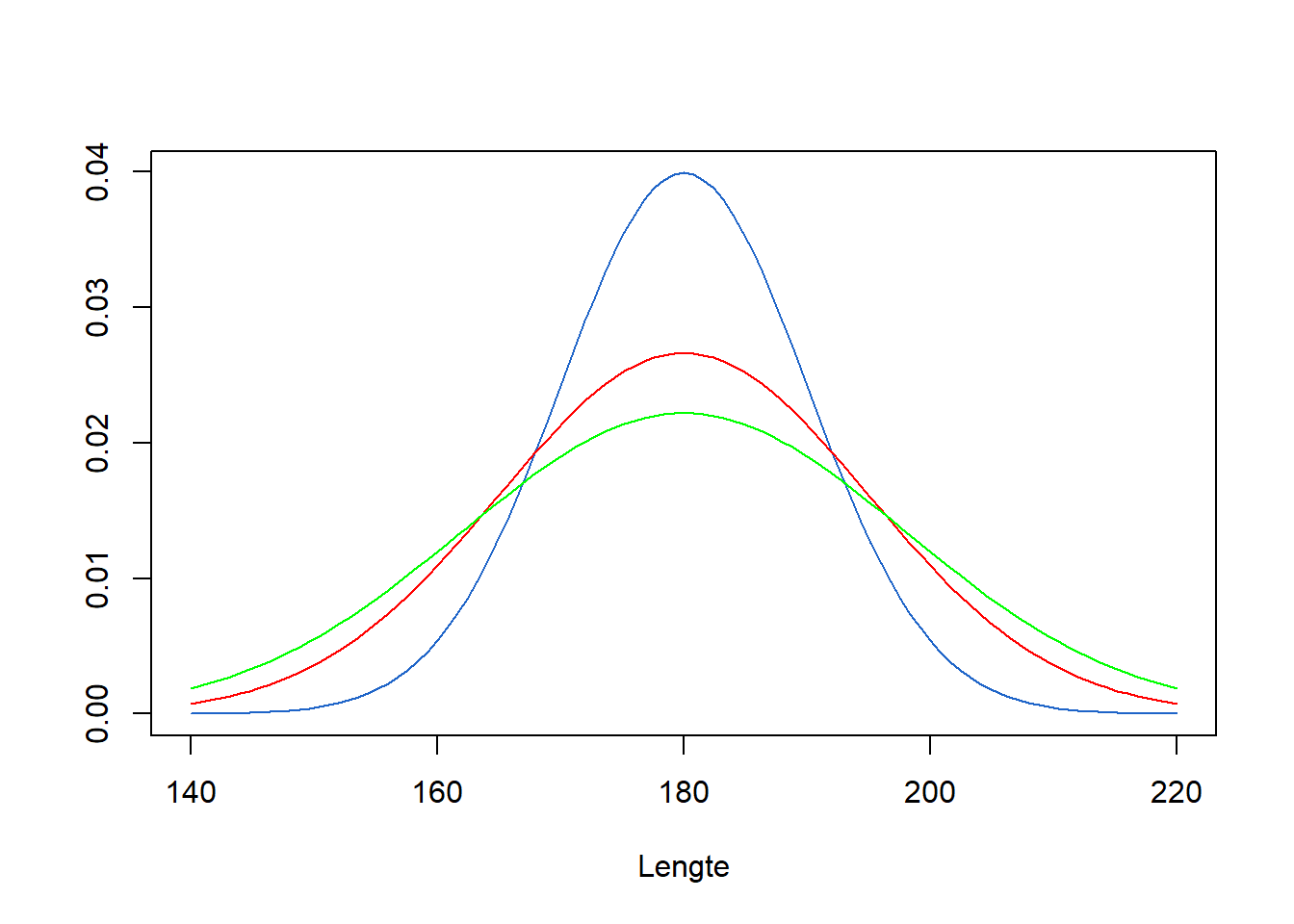
De intuïtie “hoe dichter bij het centrum, hoe waarschijnlijker, en hoe verder van het centrum, hoe onwaarschijnlijker” zullen we nu verder uitdiepen en preciezer maken.
7.2 De z-score
Wanneer we lichaamslengte als voorbeeld nemen, dan weten we intuïtief dat iemand van \(221\,cm\) zeer groot is. We weten dat deze observatie uitzonderlijk of speciaal is. Uitzonderlijk kunnen we iets formeler uitdrukken als: de kans dat iemand nog groter is heel klein. Een kans drukken we formeel uit als een percentage. Dus: het percentage aan personen die groter is dan \(221\,cm\) is heel klein. Laten we er puur hypothetisch een kans op plakken: laten we aannemen \(1\) op \(1\) miljoen, dus \(1/1000000\) of \(0.000001\%\). Formeler schrijven we: \(P(Lengte > 221)=0.000001\).
Op basis van de normale verdeling en haar eigenschappen kunnen we deze kans inschatten. Bekijken opnieuw de normale verdeling in Figure 7.5.
De totale oppervlakte onder de curve is gelijk aan \(100\%\) of \(1\). Kleinere oppervlaktes visualiseren de kans op een observatie tussen twee waarden. Bijvoorbeeld, de kans om een observatie te vinden die groter is dan \(200\) maar kleiner dan \(210\), is de oppervlakte onder de curve vanaf \(200\) tot \(210\).
Wiskundig zouden we de integraal moeten uitrekenen vanaf \(200\) tot \(210\) op basis van Equation 7.2, maar dat gaan we niet doen. Althans niet op die manier.
\[ \int_{200}^{210}\frac{1}{\sigma \sqrt{2\pi}}e^{-\frac{1}{2}\left(\frac{x-\mu}{\sigma}\right)^2}\,dx \tag{7.2}\]
We gaan de data eerst omzetten naar gestandaardiseerde waarden, zogenaamde z-scores.
Bij de variabele lichaamslengte kunnen we ons iets voorstellen. Maar er zijn veel metingen waar dat niet zo is, tenzij je over de nodige achtergrondkennis beschikt. Daarom zullen we de waarden van elke normaal verdeelde variabele zo transformeren dat we de geassocieerde proporties wel kunnen interpreteren. Deze transformatie heet standaardiseren en de standaardwaarden die we op die manier bekomen heten we z-scores. De transformatie gebeurt zoals in Equation 7.3 voor een normaal verdeelde variabele \(X\):
\[ Z=\frac{X_i-\mu}{\sigma} \tag{7.3}\]
Equation 7.4 geeft de formule voor de analoge berekening van de z-score binnen een steekproef.
\[ Z=\frac{X_i-\bar{X}}{s} \tag{7.4}\]
Als er één formule is die je uit het hoofd wil leren, dan is het deze wel. De reden hiervoor is dat dezelfde formule in verschillende analoge vormen zal terugkeren bij de statistische testen. Bij elke statistische test berekenen we een teststatistiek op basis van een formule die qnqloog is aan die voor de z-score: “hoe ver bevindt een geobserveerde waarde zich van een verwachte waarden in termen van een standaardafwijking?” is een terugkerende vraag.
7.2.0.1 Voorbeeld
We berekenen de z-score voor een persoon met lichaamslengte van \(221\;cm\) in een normale verdeling met gemiddelde \(\mu = 180\) en standaardafwijking \(\sigma = 10\):
z <- (221-180)/10
z[1] 4.1De z-score is \(4.1\), met andere woorden de lichaamslengte van \(221\,cm\) ligt \(4.1\) standaardafwijkingen boven het gemiddelde.
Laten we z-score even berekenen van een aantal andere waarden:
waarden <- c(180, 190, 200, 223, 258)
z <- (waarden-180)/10
z[1] 0.0 1.0 2.0 4.3 7.8We plaatsen de waarden en hun z-score in Table 7.1:
| waarde | z-score |
|---|---|
| 180 | 0 |
| 190 | 1 |
| 200 | 2 |
| 223 | 4.3 |
| 258 | 7.8 |
Het gemiddelde heeft als z-score \(0\), wat logisch is aangezien de waarden afgetrokken worden van het gemiddelde. De waarde \(190\) heeft als z-score \(1\) en ligt dus 1 standaardafwijking boven het gemiddelde. Iemand van \(223\,cm\) ligt \(4.3\) standaardafwijkingen boven het gemiddelde, enz. Elke waarden kunnen we transformeren naar een z-score.
Nu weten we dat er weinig mensen groter zijn dan \(223\;cm\). Welnu, je mag een z-score van \(4\) vanaf nu altijd op die manier interpreteren! Een z-score van 4 of groter wijst steeds op uitzonderlijke of speciale observaties. Je hoeft de eenheid van de variabele niet te kennen, om de gestandaardiseerde waarden of z-scores te interpreteren.
7.3 De standaard normale verdeling
De standaard normale verdeling wordt gevisualiseerd in Figure 7.6.
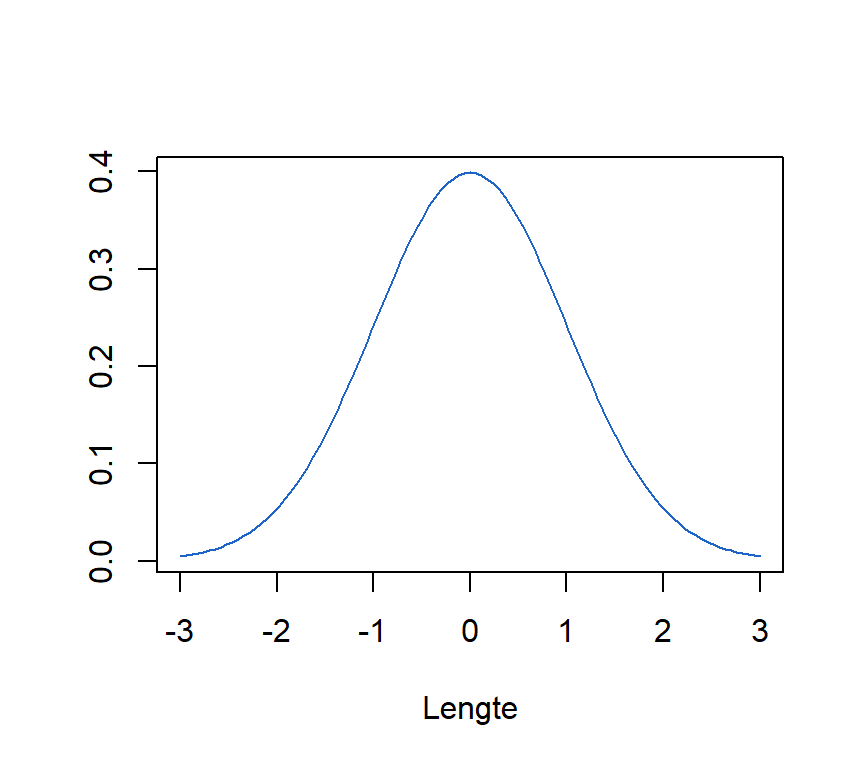
De curve van een standaard normale verdeling ziet er op het eerste gezicht exact gelijk uit aan elke andere normale verdeling. En dat klopt uiteraard. Maar kijk naar de X-as en je ziet onmiddellijk het verschil: de standaard normale verdeling heeft een gemiddelde gelijk aan \(0\) (altijd!) en een variantie (en standaardafwijking) gelijk aan \(1\) (altijd!). De standaard normale verdeling noteren we als \(N \sim (\mu = 0, \sigma = 1)\).
Elke normale verdeling kan getransformeerd worden naar een standaard normale verdeling met een gemiddelde gelijk aan \(0\) en een standaardafwijking gelijk aan \(1\). Het enige wat we daarvoor moeten doen, is de waarden van de normale verdeling transformeren naar z-scores.
7.3.0.1 Voorbeeld
We nemen een steekproef van \(1000\) observaties uit een normale verdeelde variabele \(IQ\) met gemiddelde \(\mu = 100\) en standaardafwijking \(\sigma = 13\). We standaardiseren de variabele en visualiseren de variabele met een histogram in Figure 7.7.
1steekproef <- rnorm(n = 1000, mean = 100, sd = 13)
2steekproef_z <- scale(steekproef, center = TRUE, scale = TRUE)
3hist(steekproef_z, col = "#F1A42B",
main = "", ylab = "Aantal",
xlab = "IQ_z",
xlim=c(-4,4))- 1
- We nemen een steekproef
- 2
- standaardiseren
- 3
- en visualiseren met een histogram.
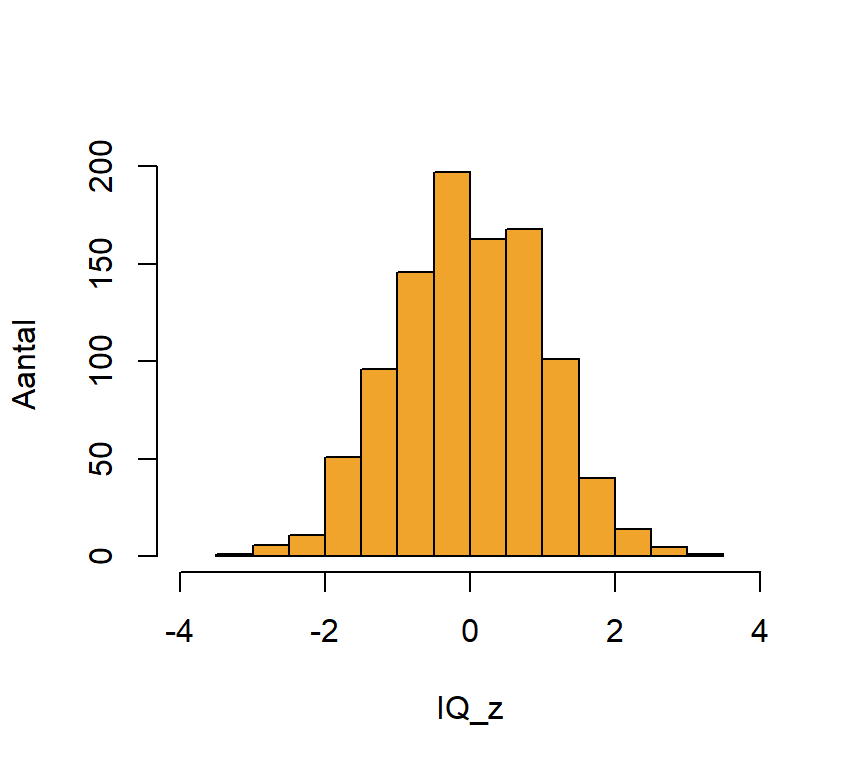
Zoals verwacht is het centrum van de verdeling gelijk aan \(0\) en bevinden de meeste observaties zich binnen \(2\) standaardafwijkingen van het gemiddelde.
7.4 Cumulatieve proporties
Op basis van de z-score kunnen we nu precieze proporties (of kansen) berekenen.
Voorbeeld
Gegeven een normale verdeling met gemiddelde \(\mu=180\) en standaardafwijking \(\sigma=10\), wat is de kans op een observatie kleiner dan \(160\)? Formeler uitgedrukt:
- Gegeven: \(Lengte \sim N(\mu = 180, \sigma =10)\)
- hoeveel is: \(P(Lengte<160)\)?
Figure 7.8 toont de proportie die we zoeken.
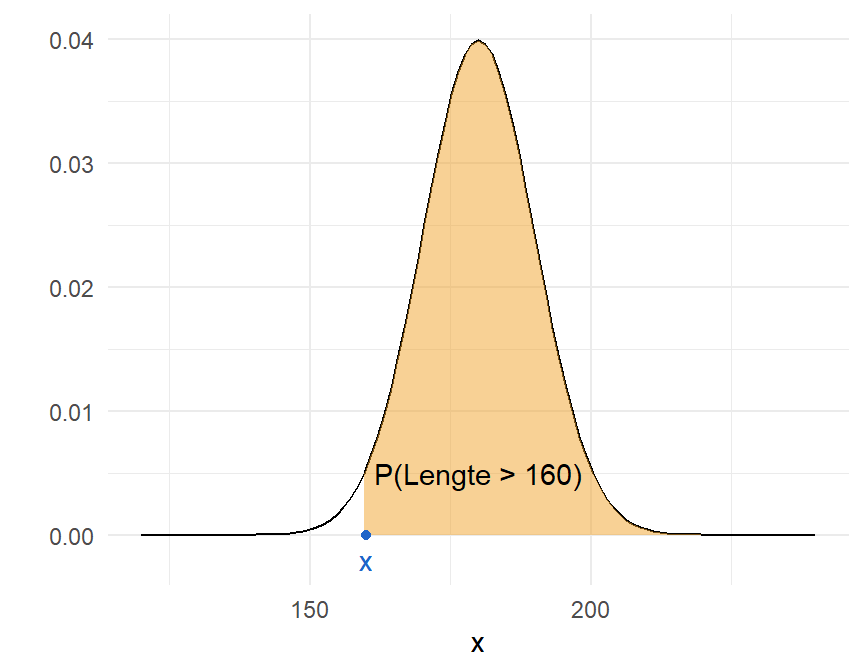
We gebruiken de pnorm() functie om de proportie te berekenen.
- 1
- We berekenen eerst de z-score:
- 2
-
en gebruiken
pnorm()om de proportie te schatten.
[1] 0.02275013De kans is (afgerond) \(2\%\). De kans op een observatie groter dan \(160\) is dan gelijk aan \(98\%\) (\(=100\%\) - \(2\%\)).
R laat ons evenwel toe om de kans te berekenen op basis van de parameters van de normale verdeling door de argumenten “mean” en “sd” aan te passen, maar de berekening via de z-score laat toe om de statistische testen die we in de latere hoofdstukken zullen uitvoeren, beter te begrijpen. Ik licht alvast een tipje van de sluier: elke statistische test is een standaardisering, waarna we zullen kijken naar een proportie groter dan deze gestandaardiseerde waarde. In de context van een statistische test is de standaardscore een teststatistiek (ook genoemd toetsingsgrootheid) en de proportie een P-waarde of significantiewaarde.
7.5 Kritische waarden
We kunnen ook de omgekeerde vraag stellen: wat is de kritische waarde voor een gegeven proportie?
- Gegeven: \(Lengte \sim N(\mu = 180, \sigma =10)\)
- Wat is \(x\) voor: \(P(Lengte<x) = 5\%\)?
We herschikken de formule voor de z-score:
\[ \begin{split} z & =\frac{x_i-\mu}{\sigma} \\ z*\sigma & =x_i-\mu \\ z*\sigma + \mu & = x_i \end{split} \tag{7.5}\]
De vergelijking \(x_i=\mu+z*\sigma\) zegt eigenlijk dat we elke observatie in een normale verdeling kunnen herschrijven als een som van het gemiddelde \(+/-\) een aantal standaardafwijkingen. Dit inzicht kot terug in de laatste hoofdstukken over de ANOVA en de regressieanalyse.
Voorbeeld
We zoeken de waarde waarvoor geldt dat de proportie kleiner dan die waarde gelijk is aan \(5\%\). Wat is die waarde op voor standaard normale verdeling? We gebruiken qnorm().
- 1
- de proportie waarvoor we de kritische waarde willen kennen
- 2
- de parameters voor de standaard normale verdeling
- 3
- we wensen de kritische waarde voor de linkerstaart.
[1] -1.644854Deze kritische waarde of z-score kunnen we nu inpluggen in de vergelijking \(x_i=\mu+z*\sigma\):
\[ x=-1.64*10 + 180 = 163.3\]
-1.64*10+180[1] 163.6\(5\%\) van de waarden op een Normale verdeling met \(\mu = 180\) en \(\sigma=10\) is kleiner dan \(163.6\;cm\).
Met de qnorm() functie kunnen we de stap van de z-score overslaan, maar het is belangrijk om de volledige redenering goed te begrijpen, omdat die later van pas komt.
qnorm(p = 0.05, mean = 180, sd = 10, lower.tail = TRUE)[1] 163.55157.6 Normaliteit testen
Normaliteit is een assumptie in veel statistische analyses. Een assumptie is een voorwaarde waaraan de data moet voldoen om betrouwbare conclusies te kunnen trekken uit de statistische analyse. We moeten dus kunnen evalueren of een variabele normaal verdeeld is. Dit kan op drie manieren.
- Ten eerste moet er nagedacht worden over het datagenererend proces. Is de variabele gerelateerd aan een eigenschap die we intuïtief met een normale verdeling associëren? Komt de data tot stand op basis van een proces waarvan we mogen veronderstellen dat de uitkomst normaal verdeeld zal zijn? Biologische maten zoals lengte en gewicht zijn vaak normaal verdeeld (ook vaak lognormaal, wat de zaken compliceert). Van talige eigenschappen zoals woordlengte en zinslengte, weten we dat die scheef verdeeld zijn en niet normaal.
- Een tweede manier om normaliteit te testen is een visuele inspectie van de data aan de hand van een histogram en gefitte densiteitscurve of aan de hand van een QQ-plot.
- Een derde manier is aan de hand van een statistische test, zoals de Shapiro-Wilk test of de Kolmogorov-Smirnov test. Statistische testen komen in een later hoofdstuk aan bod en zal ik daar verder toelichten.
7.6.0.1 Voorbeeld
We beschouwen de dataset met de lichaamslengte van \(N=20\) baskebalspelers.
Lengte<-c(184,217,191,196,205,177,209,185,200,189,
221,221,194,173,196,201,188,182,189,196)Lichaamslengte is een variabele die we doorgaans associëren met een normale verdeling. We visualiseren in Figure 7.9 de variabele Lengte met een histogram en een densiteitscurve.
library(ggplot2)
df <- data.frame(Lengte)
ggplot(df, aes(x = Lengte)) +
geom_histogram(bins = 5, fill = "#F1A42B", aes(y = after_stat(density))) +
geom_density() +
theme_minimal()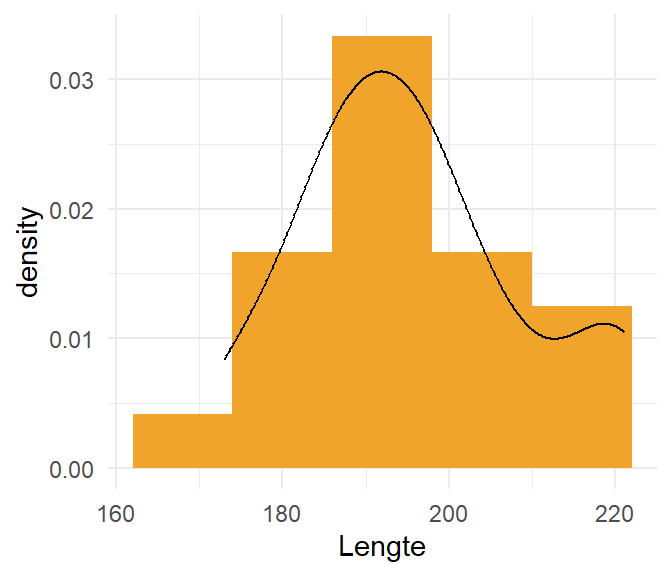
Een densiteitscurve laat gemakkelijker toe om normaliteit te beoordelen en die ziet er hier behoorlijk normaal uit. Er zijn enkele langere lengtes die er wat uitspringen, maar dat kan perfect normaal zijn bij een normaal verdeelde variabele.
Figure 7.10 toont een qq-Plot.
ggplot(df, aes(sample = Lengte)) +
stat_qq() +
stat_qq_line() +
theme_minimal()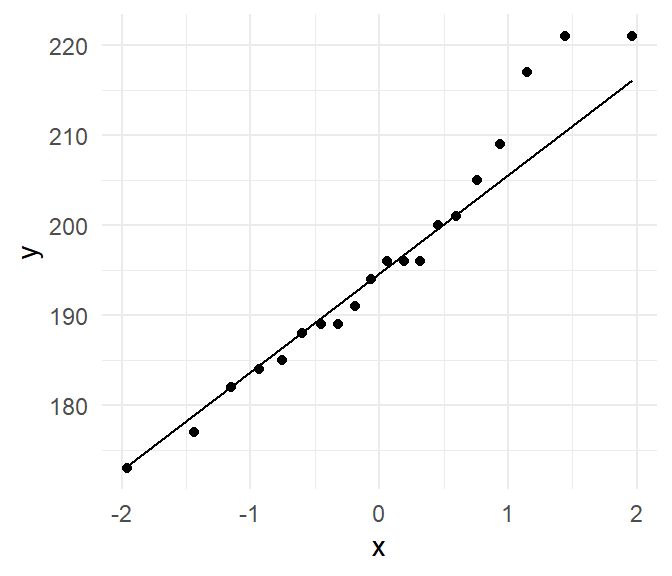
Een qq-plot is een afkorting voor quantile-quantile plot. In deze figuur worden de gestandaardiseerde waarden afgezet tegenover de theoretisch verwachte z-scores (hier op de x-as). Bij een normale verdeling verwachten we dat de punten allemaal op de rechte vallen. Hier zien we dat dit grotendeels het geval is, behalve aan de rechterstaart, waar de observaties iets groter zijn dan wat je zou verwachten bij een normale verdeling; dat zijn die enkele grotere spelers die wat uit de toon vallen, maar wat niet noodzakelijk impliceert dat de steekproef niet uit een normale verdeling komt.
Als test kunnen we een Shapiro-Wilk test uitvoeren:
shapiro.test(x = Lengte)
Shapiro-Wilk normality test
data: Lengte
W = 0.95503, p-value = 0.4499De P-waarde is hier groter dan \(5\%\), op basis waarvan we kunnen besluiten dat de data normaal verdeeld zijn. In het volgende hoofdstuk wordt deze interpretatie verder toegelicht.
7.7 Samenvatting en vooruitblik
In dit hoofdstuk hebben we enkele kenmerken van de normale verdeling gezien. We leerden hoe we elke normale verdeling kunnen standaardiseren naar een standaard normale verdeling met \(\mu=0\) en \(\sigma=1\). Op basis van de z-score hebben we cumulatieve proporties berekend. Het concept van een kritische waarde en een geassocieerde proportie of kans is fundamenteel voor alles wat volgt in de statistiek. Het is dus belangrijk om dit goed te beheersen. In het volgende hoofdstuk bekijken we de eigenschappen en de verdeling van het steekproefgemiddelde wanneer we niet één maar meerdere steekproeven zouden nemen. We zullen zien dat dit opnieuw een normale verdeling is die we kunnen standaardiseren. We noemen dit de steekproevenverdeling van het gemiddelde. Op basis van de steekproevenverdeling zullen we leren hoe we een intervalschatting kunnen maken. De steekproevenverdeling is ook een grote bouwsteen die we nodig hebben om van start te kunnen gaan met het uitvoeren van een statistische toets.
7.8 Terminologie
- normale verdeling
- parameters \(\mu\) en \(\sigma\)
- standaard normale verdeling
- z-score
- standaardiseren
- kritische waarde
- cumulatieve proportie
Functies:
- rnorm()
- dnorm()
- qnorm()
- pnorm()
- scale()
7.9 Oefeningen
- Cumulatieve proporties berekenen. IQ-scores zijn normaal verdeeld met \(\mu = 100\) en \(\sigma = 15\). Welk percentage van de populatie heeft:
- \(IQ ≤ 100\)?
- \(IQ ≤ 90\)?
- \(IQ ≥ 140\)?
- \(70 ≤ IQ ≤ 130\)?
- \(60 ≤ IQ ≤ 70\)?
- Cumulatieve proporties berekenen. Een enquête werd uitgevoerd bij \(N=2000\) participanten. De gemiddelde leeftijd van de participanten was 21 jaar (\(s=3\) jaar). Normaliteit mag aangenomen worden.
- Hoeveel participanten verwacht je tussen 18 en 24 jaar?
- Wat is de z-score van een 19 jarige participant?
- Welke proportie van participanten verwacht je ouder dan 22 jaar?
- Welke proportie verwacht je tussen 16 en 18?
- Geef de kritische waarde.
- Gegeven een normaal verdeelde variabele \(G\), met gemiddelde \(\mu = 45\) en variantie \(\sigma^2=64\). Wat is de kritische waarde voor de onderste \(10\%\)?
- \(V\sim N(\mu=12,s=3)\). Hoeveel is \(P(V > 14)\)?
- Wat zijn de kwantielwaarden voor de \(2.5\%\)-staarten op een standaard normale verdeling?
- Wat is de kritische waarde voor de bovenste \(20\%\) op een normale verdeling met gemiddelde \(\mu = 500\) en variantie \(\sigma^2=20\)?
- Geef de proportie.
- Gegeven een normaal verdeelde variabele \(G\), met gemiddelde \(\mu = 45\) en variantie \(\sigma^2=64\). Hoeveel procent is groter dan \(54\)?
- Gegeven een normaal verdeelde variabele \(G\), met gemiddelde \(\mu = 45\) en variantie \(\sigma^2=64\). Hoeveel procent is kleiner dan \(40\)?
- \(V\sim N(\mu=12,\sigma=3)\). Hoeveel is \(P(V > 14)\)?
- Gegeven een standaard normale verdeling. Wat is de proportie groter dan \(-1.96\)?
- De t-verdeling. Gegeven een variabele D verdeeld volgens een t-verdeling met 59 vrijheidsgraden.
- Wat is de proportie P voor alle waarden groter dat \(2\)?
- Wat is de proportie P voor alle waarden groter dan \(2.3\)?
- Wat is de proportie P voor alle waarden groter dan \(-1.7\)?
- \(P(D < -1.8)\)?
- \(P(D > |2.4|)\)?
- \(P(-1.68 < D < 0.54)\)?
- Wat is de kritische waarde d voor het 90ste percentiel?
- Wat is de kritische waarde d voor het eerste kwartiel?
- Wat is de kritische waarde d voor de buitenste staarten die in totaal een proportie van \(5\%\) omvatten?