S_1 <- rnorm(n = 200, mean = 180, sd = 10)
samplemean_1 <- mean(S_1)
samplemean_1[1] 179.5225In dit hoofdstuk behandelen we een fundamentele vraag uit de statistiek:
Wat zou er gebeuren als we meerdere steekproeven zouden nemen of als we ons experiment of test zouden blijven herhalen?
We zijn immers niet zozeer geïnteresseerd in één specifieke steekproef, maar in de ruimere populatie. Om een besluit te trekken over de populatie op basis van de steekproef gebruiken we de steekproevenverdeling. In dit hoofdstuk bekijken we de steekproevenverdeling van het gemiddelde, maar dezelfde idee kan op andere parameters worden toegepast.
In de vorige hoofdstukken hebben we enkele eigenschappen besproken van steekproeven en populaties. We hebben ons daarbij beperkt tot 1 steekproef of 1 populatie. In de statistiek, en dan meer bepaald in de frequentistische benadering ervan, stellen we de vraag wat er op de langere termijn zou gebeuren; wat als we meerdere steekproeven zouden nemen of creëren?
Als we een experiment uitvoeren, dan analyseren we de data alsof we het experiment zouden blijven herhalen. In zekere zin gebeurt dit ook in de wetenschap. Er is immers steeds replicatieonderzoek nodig om tot nauwkeuriger conclusies te komen. Ook hier geldt: één zwaluw maakt de lente niet.
Statistische inferentie – het trekken van conclusies over een populatie op basis van een steekproef – is gebaseerd op de idee wat er zou gebeuren als we meerdere steekproeven zouden nemen. Een fundamenteel concept daarbij is dat van de steekproevenverdeling. (Let op het meervoud: steekproeven!)
We nemen als voorbeeld de normaal verdeelde variabele Lichaamslengte, met \(\mu = 180\) en \(\sigma=10\). We nemen 1 aselecte steekproef van \(N = 100\) observaties uit deze populatie en berekenen het steekproefgemiddelde:
S_1 <- rnorm(n = 200, mean = 180, sd = 10)
samplemean_1 <- mean(S_1)
samplemean_1[1] 179.5225Dit steekproefgemiddelde wijkt weliswaar af van het populatiegemiddelde van \(180\), maar zit er toch heel dicht bij.
We nemen een tweede steekproef:
S_2 <- rnorm(n = 200, mean = 180, sd = 10)
samplemean_2 <- mean(S_2)
samplemean_2[1] 179.9407Dit tweede steekproefgemiddelde zit opnieuw dicht bij het populatiegemiddelde en is uiteraard ook verschillend van het eerste steekproefgemiddelde.
We nemen een derde steekproef:
S_3 <- rnorm(n = 200, mean = 180, sd = 10)
samplemean_3 <-mean(S_3)
samplemean_3[1] 179.6216Opnieuw een ander steekproefgemiddelde. Wat als we nu eens \(2000\) steekproeven zouden nemen? We kunnen dit simuleren aan de hand van de replicate() functie.
We bekijken de eerste 10 observaties uit de eerste 5 steekproeven (1 kolom is 1 steekproef).
Steekproeven_2000[1:10, 1:5] [,1] [,2] [,3] [,4] [,5]
[1,] 168.9184 173.7002 187.1025 187.3323 169.7900
[2,] 167.8706 171.3959 176.9771 180.6127 174.9397
[3,] 177.9432 179.8182 174.4520 173.9581 174.0648
[4,] 185.3748 177.0576 190.3920 181.2053 171.1413
[5,] 177.2780 179.2243 157.1514 186.5271 182.0701
[6,] 181.2559 185.3319 159.0754 181.9270 170.3186
[7,] 191.9060 175.0208 173.0141 179.1419 171.8145
[8,] 171.5450 171.5064 183.4134 174.8202 193.3709
[9,] 188.0578 178.0397 171.3838 185.8597 190.2513
[10,] 178.1176 183.1201 181.2556 175.1020 169.8062Voor elke steekproef (elke kolom, en we hebben er 2000 in totaal) kunnen we het gemiddelde berekenen. Hier zijn de eerste zes steekproefgemiddeldes.
Steekproef_means <- colMeans(Steekproeven_2000)
head(Steekproef_means) [1] 179.5543 179.7550 179.6470 179.7068 180.1514 180.8228Deze steekproefgemiddelden kunnen we nu als een nieuwe variabele beschouwen en we kunnen die samenvatten als een continue variabele. Figure 8.1 visualiseert de verdeling van deze steekproefgemiddeldes:
hist(Steekproef_means, col = "#1E64C8",
main = "",
ylab = "Aantal",
xlab = "Steekproefgemiddelde",
las = 1,
breaks = 20)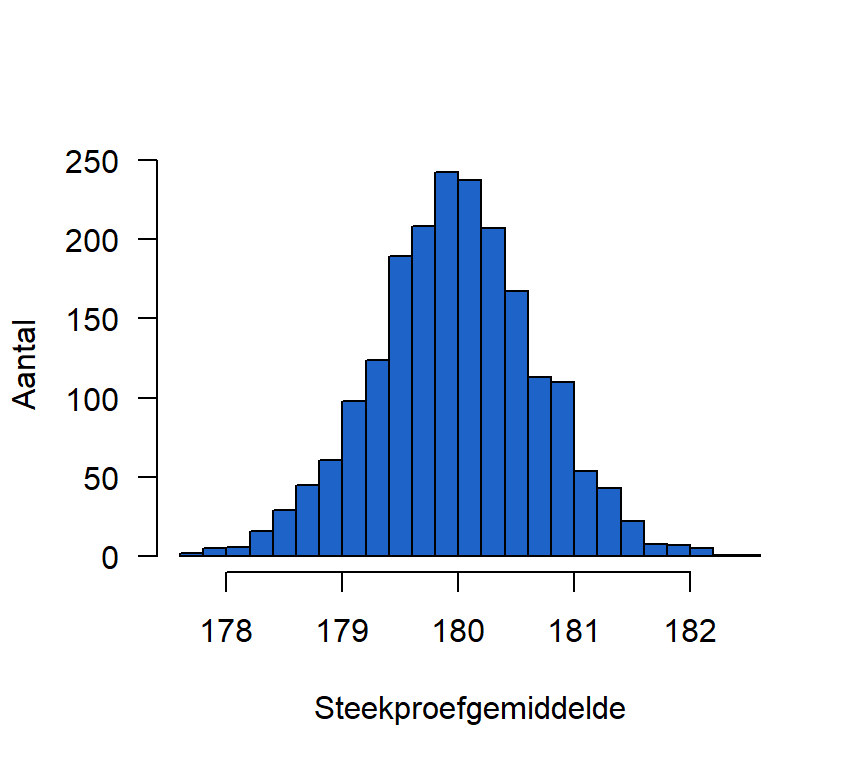
Kijk naar het centrum van deze verdeling: het gemiddelde van de steekproevenverdeling zit heel dicht bij het oorspronkelijke populatiegemiddelde \(\mu=180\). Wat is het gemiddelde van de steekproefgemiddeldes?
mean(Steekproef_means)[1] 179.9793Het gemiddelde van de steekproefgemiddeldes is \(180\) – een schitterend resultaat! Want het steekproefgemiddelde is dus op de lange termijn correct. Het bewijs is geleverd dat het steekproefgemiddelde een onvertekende schatter is (Eng. “unbiased estimator”), wat betekent dat de schatting van het gemiddelde correct is op de lange termijn. Hoe meer steekproeven we nemen, hoe dichter we bij het populatiegemiddelde zullen – en moeten! – uitkomen.
Let wel, we gaan er steeds vanuit dat we werken met aselecte steekproeven. De kwaliteit van onze analyse hangt dus volledig af van de kwaliteit van de metingen – “Garbage in, garbage out!”. Een statistische analyse kan een slecht uitgevoerde dataverzameling nooit goedmaken.
Hoe verhoudt de spreiding van de steekproevenverdeling zich tegenover de spreiding van de populatie? We vergelijken daarvoor het histogram van de steekproevenverdeling met de populatieverdeling in Figure 8.2.
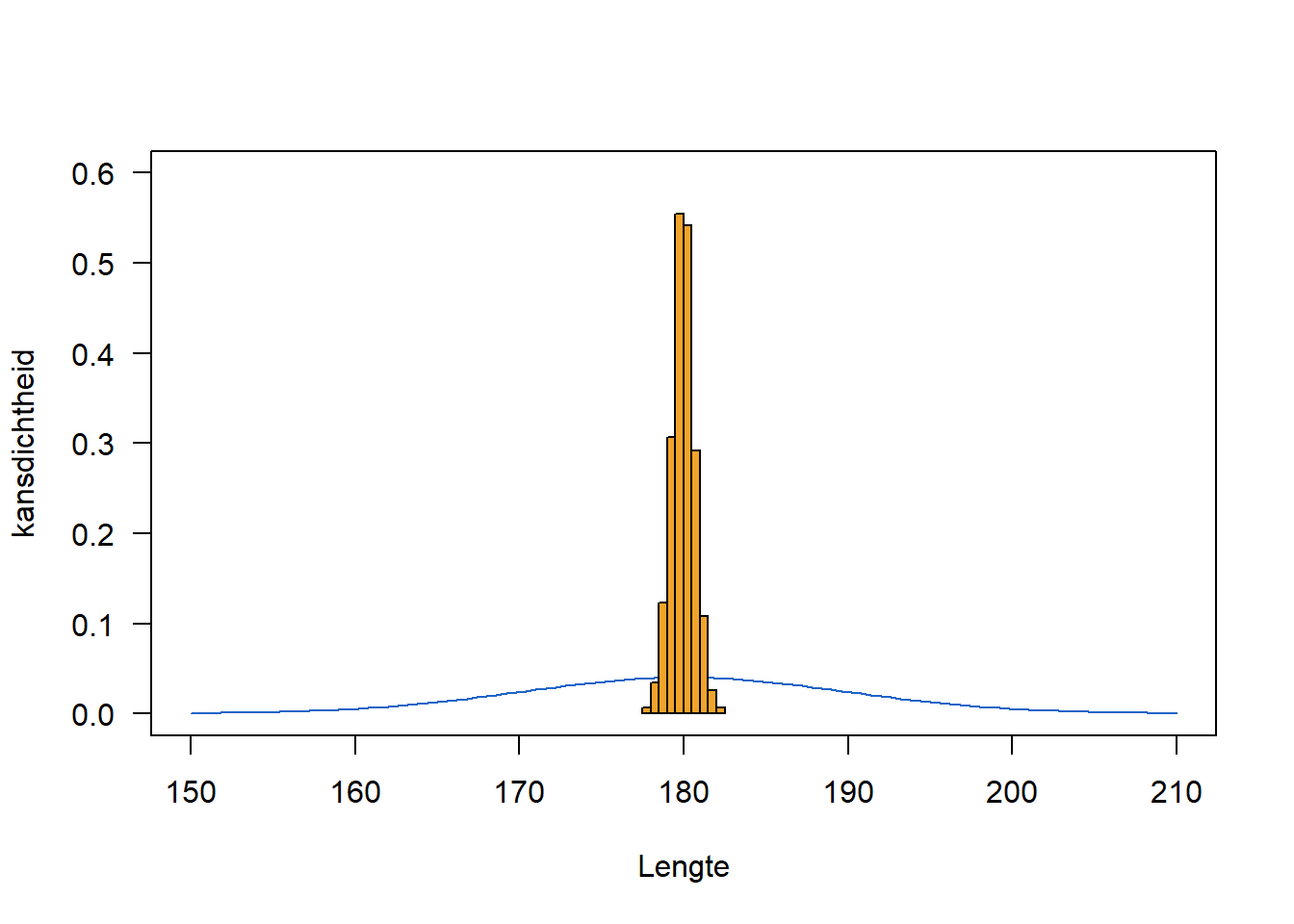
De standaardafwijking van de populatie was \(\sigma=10\). Hoeveel bedraagt de standaardafwijking van de steekproevenverdeling?
sd(Steekproef_means)[1] 0.7012723De spreiding van de gemiddeldes is veel kleiner dan die van de waarden van de oorspronkelijke verdeling. We weten zelfs exact hoeveel kleiner.
De standaardafwijking van de steekproevenverdeling noemen we de standaardfout, of in het Engels de Standard Error, afgekort SE. (in deze cursus gebruik ik de Engelse term \(SE\)). We kunnen de \(SE\) van de steekproevenverdeling bereken als in Equation 8.1.
\[ SE = \frac {\sigma}{\sqrt{n}}\\ (\text{met}\;n=\;\text{grootte van de steekproef}) \tag{8.1}\]
Als we een normaal verdeelde populatie \(X\) hebben met \(X \sim N(\mu, \sigma)\), dan weten we dat de steekproevenverdeling van het gemiddelde bij benadering normaal verdeeld is met \(\mu_{\bar{X}}=\mu\) en \(SE=\sigma_{\bar{X}}=\frac{\sigma}{\sqrt{n}}\).
We kunnen de steekproevenverdeling van het gemiddelde inschatten op basis van 1 steekproef. Dat laatste moet eigenaardig klinken. We stellen ons de vraag wat er zou gebeuren als we meerdere steekproeven zouden nemen, maar hier berekenen we de eigenschappen van de steekproevenverdeling op basis van slechts 1 steekproef. Welnu, ook 1 steekproef bestaat uit afzonderlijke “steekproeven”: elke observatie is immers onafhankelijk van de andere observaties tot stand gekomen en kan dus beschouwd worden als een steekproef.
Op basis van de centrale limietstelling weten we bovendien dat de steekproevenverdeling van het gemiddelde bij benadering normaal verdeeld is wanneer we een enkelvoudig aselecte steekproef van omvang \(N\) uit een populatie met verwachting \(\mu\) en een eindige standaardafwijking \(\sigma\) nemen; die populatie moet op zich dus niet noodzakelijk normaal verdeeld zijn!
Als we \(\sigma\) van de populatie kennen, dan is de steekproevenverdeling van het gemiddelde normaal verdeeld.
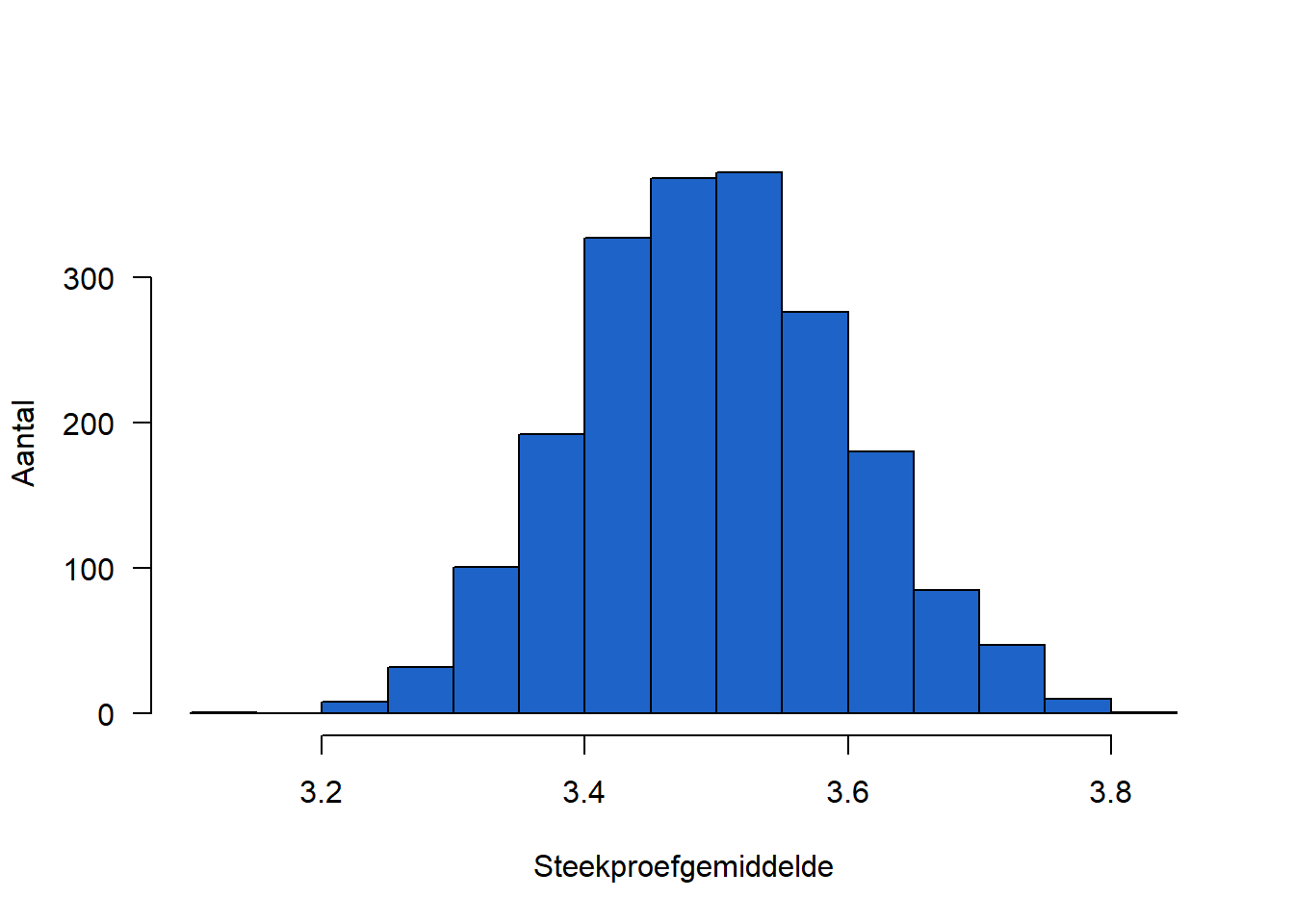
We kunnen de centrale limietstelling illustreren aan de hand van de steekproevenverdeling van de gemiddeldes uit een uniforme verdeling. Bij een uniform verdeelde variabele zijn alle observaties tussen een minimum en een maximum even waarschijnlijk. Figure 8.3 visualiseert een uniforme verdeling met \(min=1\) en \(max=6\)) en de steekproevenverdeling van het gemidddelde voor dezelfde uniforme verdeling. Figure 8.3 (b) is duidelijk normaal verdeeld.
uniform <- runif(n = 2000, min = 1, max = 6)
hist(uniform, col = "#1E64C8",
main = "",
ylab = "Aantal",
xlab = "",
las = 1,
breaks = 20)
Steekproeven_uniform <- replicate(n = 2000,
expr = runif(n = 200, min = 1, max = 6))
Steekproeven_uniform_means <- colMeans(Steekproeven_uniform)
hist(Steekproeven_uniform_means, col = "#1E64C8",
main = "",
ylab = "Aantal",
xlab = "Steekproefgemiddelde",
las = 1,
breaks = 20)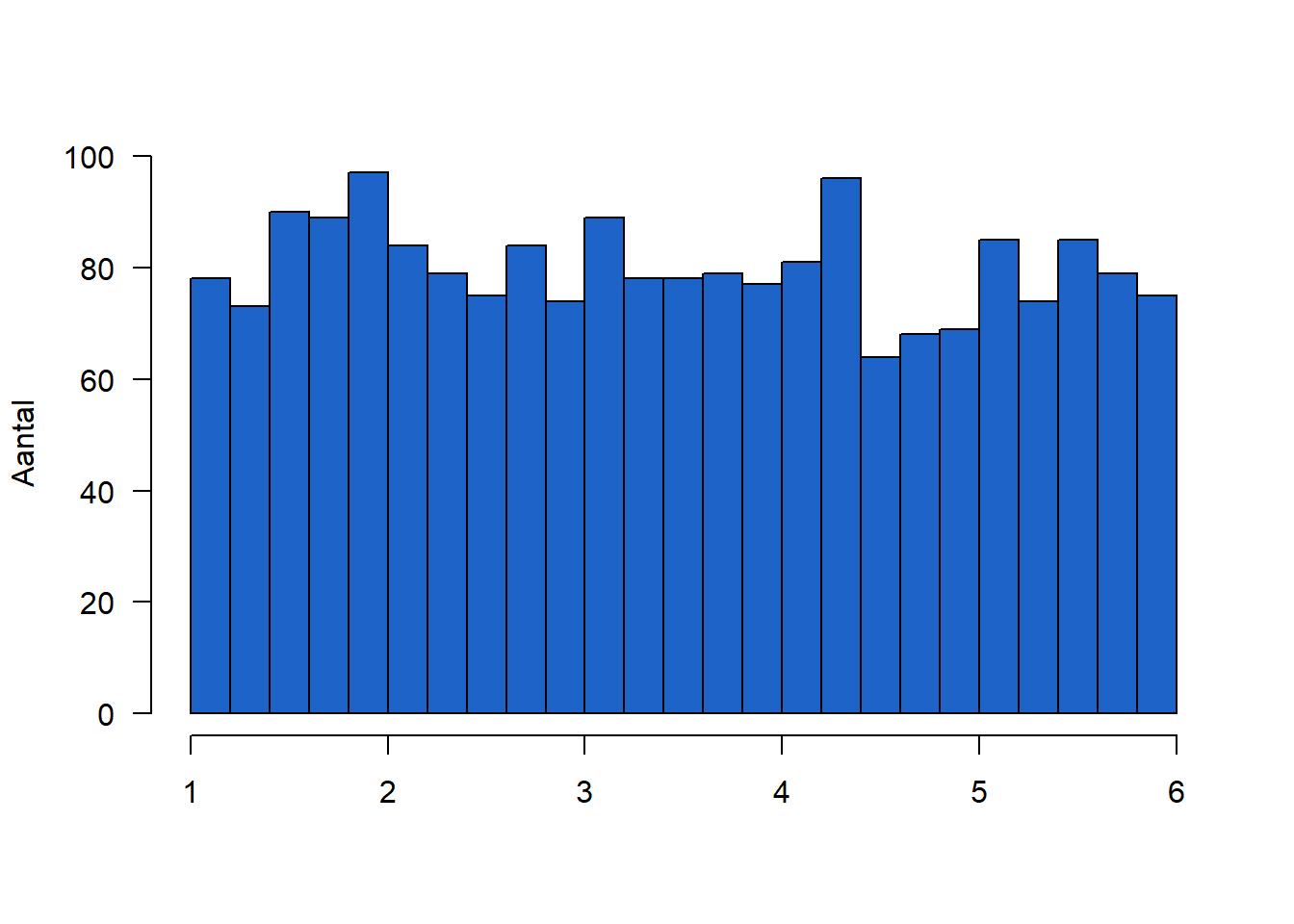
Nu we weten dat de steekproevenverdeling van het gemiddelde normaal verdeeld is, kunnen we deze steekproevenverdeling ook standaardiseren. Equation 8.2 is analoog aan die van de z-score.
Voor \(\bar{X} \sim N(\mu, \sigma/\sqrt{n})\) geldt:
\[ \frac{\bar{X}-\mu}{\frac{\sigma}{\sqrt{n}}}\sim N(0,1) \tag{8.2}\]
Dit is dus niets anders dan een standaard normale verdeling! Het is deze gestandaardiseerde versie die we gebruiken om statistische testen uit te voeren.
Maar in de meeste gevallen zullen we \(\sigma\) niet kennen. Op basis van een steekproef kunnen we \(\sigma\) wel schatten door de steekproefstandaardafwijking \(s\). In hoofdstuk 1 hebben we gezien hoe dat moet: \(s=\sqrt{\frac{1}{1-n}(x_i-\bar{X})²}\).
Als we \(\sigma\) schatten door \(s\), dan volgt de gestandaardiseerde steekproevenverdeling van het gemiddelde uit geen normale verdeling meer, maar een t-verdeling met \(n-1\) vrijheidsgraden (afgekort als “df”, voor het Eng. “degrees of freedom”):
\[ \frac{\bar{X}-\mu}{\frac{s}{\sqrt{n}}}\sim t_{n-1} \tag{8.3}\]
De t-verdeling ziet eruit zoals een normale verdeling. De vrijheidsgraad is een parameter van de verdeling (zoals \(\mu\) en \(\sigma\) parameters zijn van de normale verdeling). Figure 8.4 toont drie t-verdelingen met verschillende vrijheidsgraden samen met de normale verdeling (in zwart).
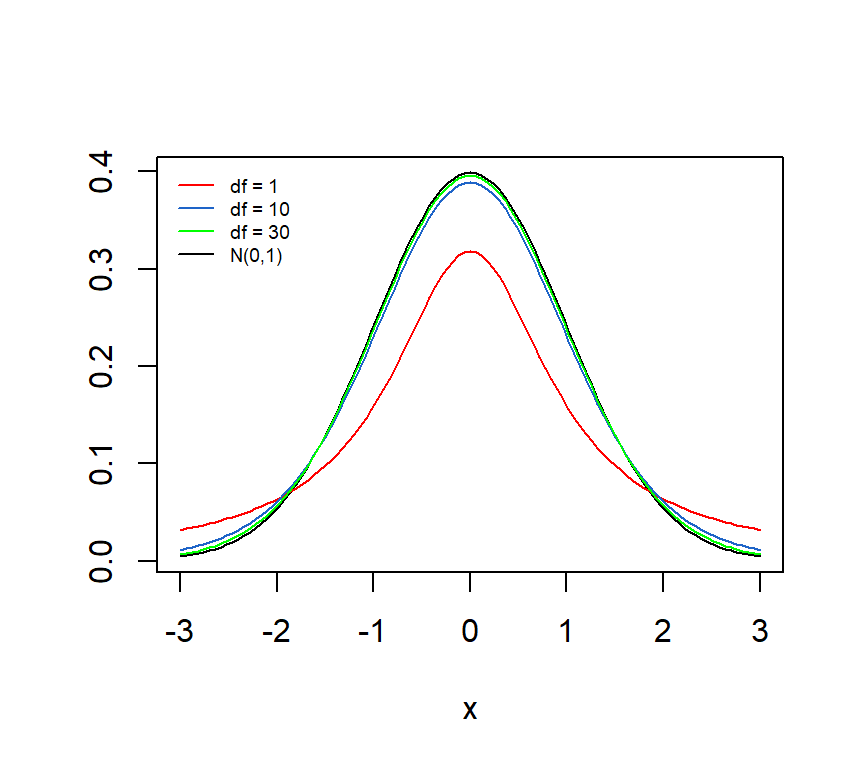
Met de functies rt(), pt() en qt() krijg je respectielijk een aselecte steekproef, een cumulatieve proportie, en een kritische waarde geassocieerd met een proportie voor een t-verdeling. Enkele voorbeelden ter illustratie.
We nemen een aselecte steekproef van \(N=1000\) observaties uit een t-verdeling met \(59\) vrijheidsgraden.
s <- rt(n = 1000, df = 59)
head(s)[1] -0.07547521 -0.40098338 1.36302070 0.97274570 -0.44384088 -0.11936063wat is de cumulatieve proportie kleiner dan \(-1.2\), of \(P(T < -1.2)\), voor een t-verdeling met \(60\) vrijheidsgraden?
pt(q = -1.2, df = 60, lower.tail = TRUE)[1] 0.1174281Wat is de kritische waarde voor de laagste en hoogste \(2.5\)% voor een t-verdeling met 40 vrijheidsgraden?
qt(p = c(0.025, 0.975), df = 40)[1] -2.021075 2.021075De concepten kritische waarde en cumulatieve proportie zijn exact analoog aan die voor de normale verdeling. Dezelfde concepten kun je op alle andere verdelingen toepassen. We zullen dit nodig hebben wanneer we significantietesten uitvoeren.
Op basis van een steekproef kunnen we schatters berekenen voor de parameters van een populatie. Tot nu toe hebben we met puntschatters gewerkt.
| (Populatie)parameter | (Steekproef)statistiek |
|---|---|
| \(\mu\) | \(\bar{X}\) |
| \(\sigma\) | \(s\) |
Beschouw opnieuw de functie van de normale verdeling in Equation 8.4:
\[ f(x)=\frac{1}{\sigma \sqrt{2\pi}}e^{-\frac{1}{2}\left(\frac{x-\mu}{\sigma}\right)^2} \tag{8.4}\]
Deze functie bevat twee parameters: \(\mu\) en \(\sigma\). Op basis van een steekproef kunnen we beide schatten en dan “kennen” we de volledige verdeling.
In plaats van 1 schatting te maken voor de parameters, kunnen we ook een interval schatten. Voor \(\mu\), bijvoorbeeld, kunnen we een interval berekenen waarin we \(\mu\) met een bepaalde kans (bvb. \(95\%\)) verwachten. We maken hiervoor gebruik van de puntschatter \(\bar{X}\) in combinatie met de \(SE\) van de steekproevenverdeling.
Beschouw opnieuw de steekproevenverdeling van het gemiddelde waarbij \(\sigma\) gekend is – de steekproevenverdeling volgt in dat geval de normale verdeling:
\[ \frac{\bar{X}-\mu}{\frac{\sigma}{\sqrt{n}}}\sim N(0,1) \]
We weten dat voor deze verdeling, \(95\%\) van de observaties tussen \(\mu-1.96\) en \(\mu+1.96\) ligt, zoals geïllustreerd in Figure 8.5.
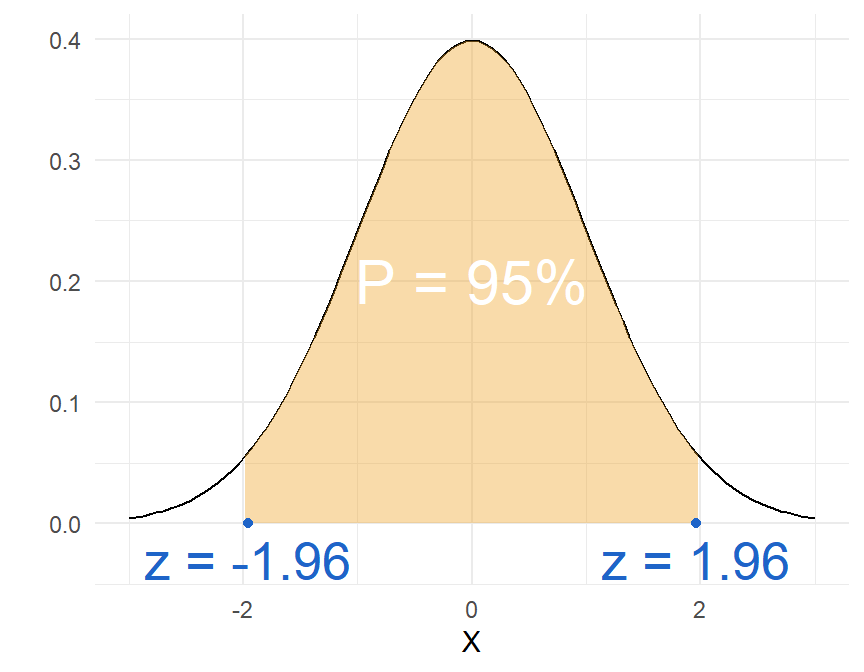
De groene zone vertegenwoordigt \(95\%\), wat ook impliceert dat de witte staarten goed zijn voor de overige \(5\%\). Die \(5\%\) noemen we \(\alpha\). Eén staart vertegenwoordigt dus \(\alpha/2\) of \(2.5\%\). De twee kritische waarden in blauw noteren we als \(z_{\alpha/2}\).
Een intervalschatter voor \(\mu\) kunnen we op een gelijkaardige manier creëren. We berekenen daarvoor een ondergrens en een bovengrens rond \(\bar{X}\). Beide grenzen berekenen we als volgt:
We illustreren een \(95\%\) betrouwbaarheidsinterval voor het populatiegemiddelde aan de hand van een voorbeeld.
Stel dat we een steekproef hebben van \(N = 40\) observaties met taaltestscores. De totale score op de test bedraagt \(60\). We weten uit vroeger onderzoek dat \(\sigma = 3\). Het steekproefgemiddelde is \(41\).
We kunnen en \(95\%\) BI als volgt berekenen:
1X_bar <- 41
2n <- 40
3sigma <- 3
4SE <- sigma/sqrt(40)
5Z_alpha <- abs(qnorm(p = 0.5/2))
6Ondergrens <- X_bar - abs(Z_alpha)*SE
Bovengrens <- X_bar + abs(Z_alpha)*SE
c(Ondergrens, Bovengrens)[1] 40.68006 41.31994We hebben een \(95\%\) betrouwbaarheidsinterval (BI) voor het gemiddelde (\(\mu\)) van \(40.07\) tot \(41.93\). Formeler wordt een BI gedefinieerd als in Equation 8.5.
\[ \begin{split} P[-z_{\alpha/2}<\frac{\bar{X}-\mu}{\frac{\sigma}{\sqrt{n}}}<z_{\alpha/2}] &=100\%-\alpha \\ P[-z_{\alpha/2}<\frac{\bar{X}-\mu}{\frac{\sigma}{\sqrt{n}}}<z_{\alpha/2}] &=100\%-\alpha \\ P[\bar{X}-z_{\alpha/2}\frac{\sigma}{\sqrt{n}}<\mu<\bar{X}+z_{\alpha/2}\frac{\sigma}{\sqrt{n}}] &=100\%-\alpha \end{split} \tag{8.5}\]
P staat hier voor proportie of kans. We lezen dus dat de proportie tussen vierkante haakjes gelijk is aan \(100\%-\alpha\). De keuze voor \(\alpha\) bepaalt de kritische waarde.
Als we een BI van \(90\%\) wensen, dan is \(\alpha=10\%\), en dus gebruiken we dan als kritische waarde \(z_{\alpha/2}=1.64\).
qnorm(0.05)[1] -1.644854Als we \(\sigma\) niet kennen, dan moeten we deze standaardafwijking schatten op basis van de steekproefstandaardafwijking \(s\) (zie Equation 6.7). In dat geval gebruiken we de t-verdeling voor de kritische waarde.
Formeel:
\[ P{[\bar{X}-t_{\alpha/2,\;n-1}\frac{\sigma}{\sqrt{n}}}<\mu<\bar{X}+t_{\alpha/2,\;n-1}\frac{\sigma}{\sqrt{n}}]=100\%-\alpha \tag{8.6}\]
We hebben een steekproef nodig om \(s\) te bereken:
set.seed(4635) # om telkens dezelfde steekproef te krijgen
dd <- rnorm(n = 40, mean = 41, sd = 3)
head(dd, 20) [1] 37.68313 42.80806 41.31365 46.18608 39.60299 40.31846 40.82984 39.37190
[9] 38.87229 41.44719 36.89051 41.90103 47.36603 41.36113 40.41350 38.00208
[17] 46.64815 36.89039 46.52108 42.28382We kunnen nu een \(95\%\) BI berekenen:
X_bar <- mean(dd)
n <- 40
s <- sd(dd)
SE <- s/sqrt(40)
t_alpha <- abs(qt(p = 0.025,df = n-1))
Ondergrens <- X_bar - abs(t_alpha)*SE
Bovengrens <- X_bar + abs(t_alpha)*SE
c(Ondergrens, Bovengrens)[1] 40.20862 41.89450Ten eerste zegt het betrouwbaarheidsinterval enkel iets over de methode die we gebruiken. Als we de methode correct gebruiken, d.w.z. als we op een correcte manier aselecte steekproeven nemen, dan zal \(\mu\) in \(95\%\) van alle betrouwbaarheidsintervallen liggen. Maar het kan even goed zijn dat \(\mu\) niet in het berekende BI ligt. Ligt \(\mu\) in het BI dat je berekend hebt? Dat weet je niet! Je weet alleen dat bij herhaaldelijke steekproeven het populatiegemiddelde \(\mu\) gemiddeld in \(95\%\) van alle BIs zal liggen.
Ten tweede is een betrouwbaarheidsinterval een interval met een ondergrens en een bovengrens. Alle waarden tussen beide grenzen zijn even waarschijnlijk. Het BI is dus GEEN kansdichtheidsfunctie. Het is dus niet zo dat \(\mu\) minder waarschijnlijk wordt naar de grenzen toe.
Het idee achter betrouwbaarheidsintervallen wordt mooi geïllustreerd aan de hand van een applet:
https://digitalfirst.bfwpub.com/stats_applet/stats_applet_4_ci.html
We hebben in dit hoofdstuk een moeilijk concept behandeld: de steekproevenverdeling. In de volgende hoofdstukken komt de steekproevenverdeling terug als de verdeling van de teststatistiek onder de nulhypothese.
Bijvoorbeeld, bij een t-test voor twee populatiegemiddelden gebruiken we de steekproevenverdeling van het verschil tussen twee gemiddelden. Bij een t-test voor één gemiddelde gebruiken we dan weer de steekproevenverdeling van het gemiddelde. Bij een regressie-analyse gaan we de significantie van de richtingscoëfficiënt na aan de hand van de steekproevenverdeling van die geschatte coëfficiënt.
Bij elke statistische test houden we dus via de steekproevenverdeling rekening met de variabiliteit in de testdata en stellen we de vraag wat er zou gebeuren als we de test meerdere malen zouden herhalen.
Functies:
formant dataset (formant.csv) bevat metingen van de eerste formant (HZ F1) van een bepaalde vocaal voor \(N=120\) participanten, waarvan 60 mannen en 60 vrouwen.
HZ F1:
HZ F1 weer als een blauwe densiteitscurveformant dataset. Naast de formanten bevat de dataset ook informatie over het geslacht van de participanten via de variabele Sex.
Sex?Sex.HZ F1 opgesplitst volgens Sex.HZ F1 volgens Sex. Gebruik hiervoor het ggplot2 package.HZ F1HZ F1tapply() functie wordt gebruikt om een samenvattende functie (bvb. mean, sd, min, enz) toe te passen op een numerieke variabele die opgesplitst wordt op basis van een categorische variabele (een zogenaamde “factor” in R).
HZ F1 volgens Sextidyverse package om volgende vragen op te lossen over de Falsebeginners dataset.
PPVT van beide geslachtenPPVT hoger dan \(100\)?Spreken dan leerlingen met een lage attitude? Vergelijk het gemiddelde en de mediaan.