fb <- read.delim("Falsebeginners.txt", stringsAsFactors=TRUE)
fb <- na.omit(fb)5 Datavisualisatie met ggplot2
ggplot2 (Wickham 2016) is tegenwoordig het package bij uitstek om data te visualiseren in R. Een inleidend overzicht mag in deze basiscursus statistiek dan ook niet ontbreken. ggplot2 is een onderdeel van de tidyverse en zoals we in het vorige hoofdstuk al gezien hebben, streeft tidyverse naar consistentie in de codesyntax. Datamanipulatie met dplyr werkt ook naadloos samen met ggplot2. In het vorige hoofdstuk hebben we gezien hoe datasamenvattingen in dplyr steeds consequent als een dataframe gerapporteerd werden. ggplot2 maakt handig gebruik van deze dataframes.
5.1 Data: False beginners
We werken opnieuw met de falsebeginners dataset en verwijderen eerst alle rijen met NAs.
De dataset volgt het lange dataformaat. We hebben een dataset van \(N = 746\) observaties en \(10\) variabelen.
summary(fb) Leerling School Klas PPVT Spreken
Min. : 2.0 S12 : 50 12A : 27 Min. : 31.00 Min. : 0.000
1st Qu.:221.2 S34 : 46 9A : 26 1st Qu.: 70.00 1st Qu.: 2.000
Median :443.5 S38 : 35 11A : 23 Median : 78.00 Median : 5.000
Mean :441.5 S51 : 35 12B : 23 Mean : 78.53 Mean : 6.782
3rd Qu.:661.8 S8 : 34 42A : 22 3rd Qu.: 88.00 3rd Qu.:10.000
Max. :867.0 S24 : 32 21A : 20 Max. :116.00 Max. :20.000
(Other):514 (Other):605
Luisteren SchrijvenLezen Attitude Thuistaal Geslacht
Min. : 0.00 Min. : 0.00 negatief: 26 Meertalig :198 man :381
1st Qu.:10.00 1st Qu.:13.00 positief:720 Nederlands:548 vrouw:365
Median :15.00 Median :18.00
Mean :14.94 Mean :21.13
3rd Qu.:20.00 3rd Qu.:29.00
Max. :25.00 Max. :50.00
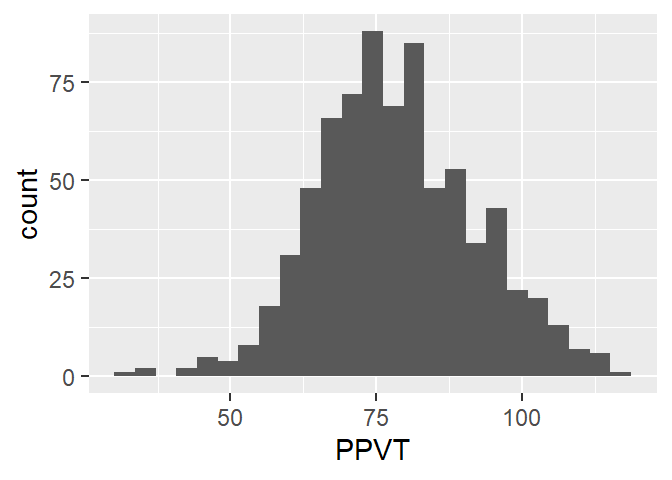
We starten met univariate visualisaties en creëren achtereenvolgens een histogram, een boxplot en een densiteitscurve voor de variabele PPVT, een score op een totaal van \(120\). We visualiseren de variabele Geslacht aan de hand van een staafdiagram.
5.2 Histogram
- 1
- het eerste argument verwijst naar de dataset die we gebruiken
- 2
-
aesbevat de variabelen die we visualiseren, in dit gevalPPVTop de x-as - 3
- geom verwijst naar de manier waarop we de data willen visualiseren
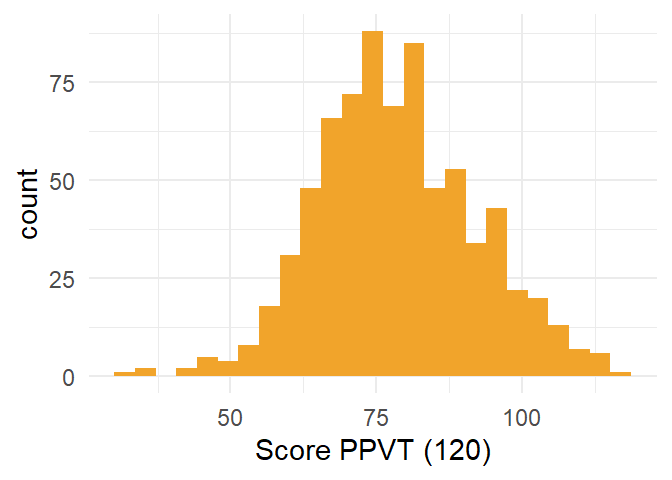
We kunnen gemakkelijk enkele esthetische verbeteringen aanbrengen.
1ggplot(fb,
2 aes(x=PPVT)) +
3 geom_histogram(bins = 25,
4 fill = "#F1A42B") +
5 theme_minimal() +
6 xlab("Score PPVT (120)")- 1
- de dataset
- 2
- de data die we willen visualiseren
- 3
- de visualisatiemethode, met argumenten die het histogram aanpassen: het aantal bins
- 4
- de opvulkleur; “col” past de kleur van de randen aan
- 5
- een thema voor de visualisatie; hier laten we de achtergrondkleur weg
- 6
- een betere naam voor de x-as.
5.3 Boxplot
Het enige wat we hier hoeven aan te passen aan de code voor het histogram is de geom – we stellen immers nog steeds dezelfde data voor, maar gebruiken een andere visualisatie.
- 1
-
Gebruik
gb - 2
-
gebruik
PPVTop de y-as (voor een horizontale boxplot gebruik jeaes(y=PPVT)maar vertikale boxplots zijn gebruikelijk. - 3
- teken een boxplot
- 4
- pas de labels op de x-as aan
- 5
- gebruik een minimalistisch thema (er zijn ontelbaar veel thema’s om uit te kiezen).
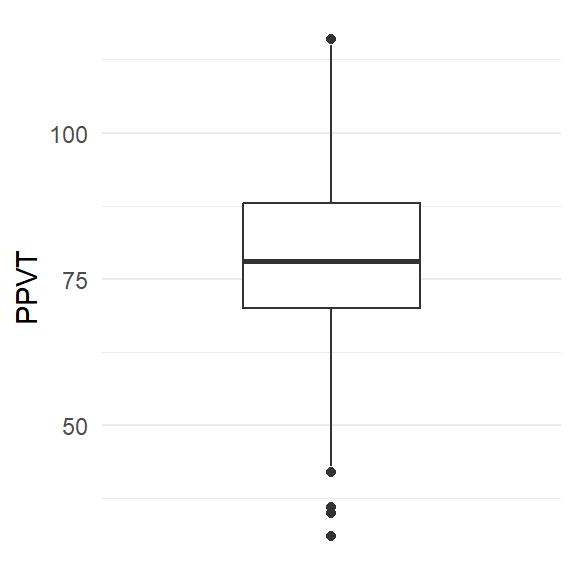
Als je dit nogal omslachtig vindt om een simpele boxplot te tekenen, dan heb je gelijk. Gebruik base-R voor dergelijke eenvoudige plots. De kracht van ggplot2 komt tot zijn recht bij complexere figuren.
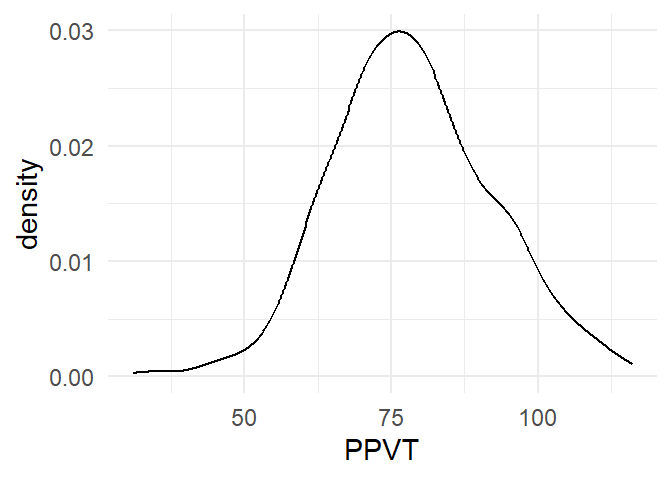
5.4 Densiteitscurve
Door de geom aan te passen bekomen we op dezelfde manier een densiteitscurve.
5.5 Staafdiagram
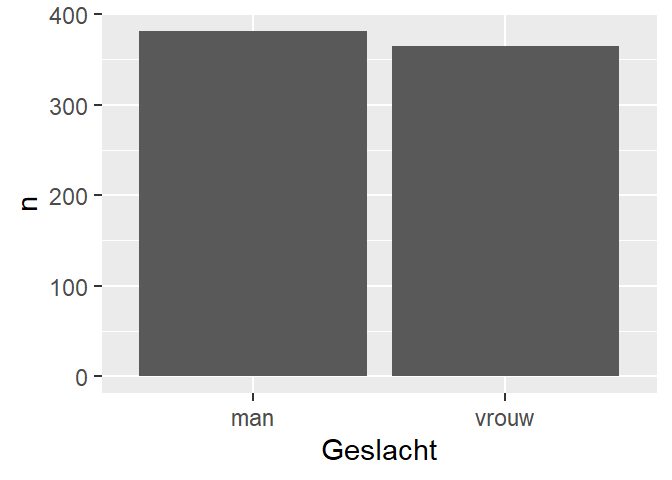
Om een staafdiagram te maken, moeten we eerst de data samenvatten. We gebruiken hiervoor het dplyr-package.
- 1
-
creëer een nieuwe dataframe
Geslacht_N, begin metfb - 2
-
tel het aantal observaties voor elke waarde van de categorische variabele
Geslacht - 3
- print de nieuwe dataset
Geslacht n
1 man 381
2 vrouw 365Merk op dat je hier mooi het verschil ziet met de table() functie in base R. Het resultaat van table() is een tabel en geen dataframe. In tidyverse worden de resultaten consequent in een dataframe weergegeven.
Vergelijk:
table(fb$Geslacht)
man vrouw
381 365 Geslacht_N gebruiken we nu voor de visualisatie: op de x-as plaatsen we de twee waarden van de variabele geslacht, en op de y-as visualiseren we de frequenties die we zonet berekend hebben.
- 1
-
Gebruik
Geslacht_N - 2
-
Gebruik
Geslacht(althans de waarden ervan) op de x-as - 3
- Gebruik de getelde aantallen op de y-as
- 4
- visualiseer de datapunten met een staafdiagram (“col” = column)
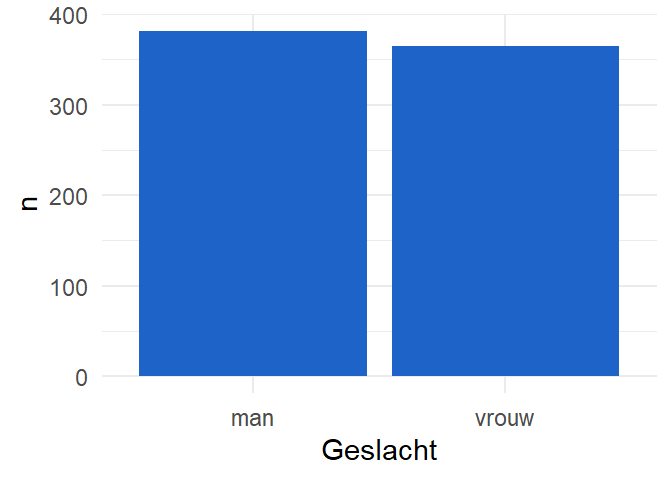
We kunnen opnieuw enkele esthetische aanpassingen aanbrengen.
1ggplot(Geslacht_N,
2 aes(x = Geslacht,
3 y = n)) +
4 geom_col(fill = "#1E64C8") +
5 xlab("Geslacht") +
6 theme_minimal()- 1
- Gebruik Geslacht_N
- 2
- gebruik Geslacht (althans de waarden ervan) op de x-as
- 3
- gebruik de getelde aantallen op de y-as
- 4
- visualiseer de datapunten met een staafdiagram en voeg een kleur toe
- 5
- geef een label aan de x-as
- 6
- gebruik een minimalistisch thema.
Het grote voordeel van ggplot2 komt tot uiting wanneer we de figuren uitbreiden met extra variabelen. De code blijft grotendeels gelijk. We hoeven enkel een extra variabele toe te voegen die de groepering aanduidt en aan te geven hoe die variabele gevisualiseerd moet worden.
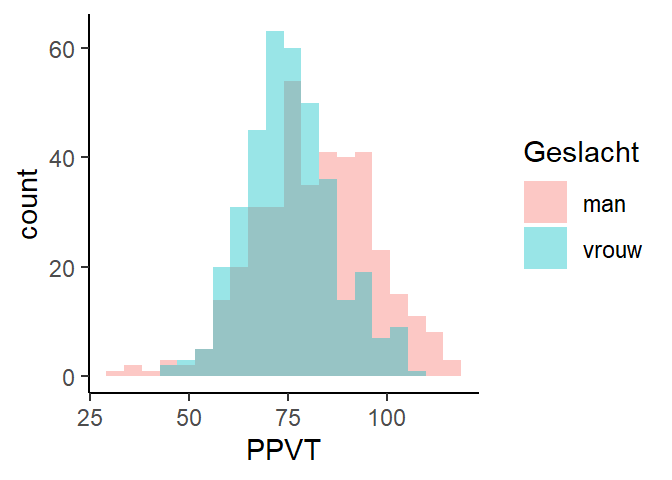
5.6 Overlappende histogrammen
Overlappende histogrammen zijn handig om twee verdelingen te vergelijken.
1ggplot(fb,
2 aes(x=PPVT,
3 fill = Geslacht)) +
4 geom_histogram(bins = 20,
position = "identity",
alpha = 0.4) +
5 theme_classic()- 1
-
Kies
fb - 2
-
gebruik
PPVTvoor de x-as - 3
- gebruik Geslacht om een kleurverschil aan te geven
- 4
-
maak een histogram. Pas de bins aan. “identity” is noodzakelijk om de histogrammen te laten overlappen. Met
alphapas je de doorzichtigheid van de histogrammen aan - 5
- in een klassiek thema.
5.7 Histogrammen in een raster
Hier volgt geef een voorbeeld van een visualisatie waarbij we eerst data selecteren met dplyr om te tonen hoe beide packages samenwerken.
5.7.0.1 Voorbeeld
We wensen voor scholen met meer dan \(15\) leerlingen per klas de PPVT score te visualiseren aan de hand van een histogram. Hiervoor moeten we eerst de klassen te kennen met meer dan \(15\) leerlingen. We gebruiken dplyr om die uit de dataset te filteren.
- 1
-
Maak een nieuwe dataframe
fbs, start metfben tel het aantal klassen per school - 2
- filter de rijen op basis van de conditie dat n (= het aantal leerlingen) meer dan \(20\) moet zijn.
We tellen het aantal klassen omdat de dataset is opgemaakt volgens het lange dataformaat. Elke leerling zit in één klas per school; door het aantal klassen te tellen krijgen we het aantal leerlingen.
Bekijk de eerste tien rijen uit de fbs dataframe:
head(fbs, 10) School Klas n
1 S10 10A 19
2 S11 11A 23
3 S12 12A 27
4 S12 12B 23
5 S18 18A 18
6 S21 21A 20
7 S24 24A 16
8 S24 24B 16
9 S30 30A 16
10 S33 33A 18n geeft hier het aantal leerlingen per klas weer en uiteraard niet het aantal klassen per school. Sommige scholen (bvb. S24) hebben meer dan \(1\) klas met meer dan \(15\) leerlingen. Hoeveel klassen zijn er?
dim(fbs)[1] 25 3Er zijn \(25\) klassen met meer dan \(15\) leerlingen. We weten nu welke scholen meer dan \(15\) klassen hebben in de dataset. Nu moeten we die scholen nog uit de fb dataset filteren. Anders kunnen we PPVT niet gebruiken.
fbschool <- filter(fb, School %in% fbs$School)De %in% operator hebben we nog niet gebruikt: met filter halen we rijen uit fb, op basis van de conditie welke School (uit fb) overeenstemt met School uit fbs (die we hierboven gemaakt hebben). Vergelijk:
1groep1 <- c("Maarten", "Jonas", "Mathis")
groep2 <- c("Matheus", "Lucas", "Johanes", "Maarten", "Mathis")
2groep1 %in% groep2
3groep1[which(groep1 %in% groep2)]- 1
- we maken twee karaktervectoren met namen die gedeeltelijk overlappen.
- 2
-
via de logische operator
%in%gaan we voor elke waarden uit groep1 na of die in groep2 voorkomt. De uitkomst is waar of vals. bvb. de eerste “TRUE”: Maarten komt inderdaad voor in groep2 - 3
- via de indexfunctie (de vierkante haakjes) halen we de elementen uit groep1 met TRUE.
[1] TRUE FALSE TRUE
[1] "Maarten" "Mathis" We keren terug naar de fbschool-dataset en bekijken de eerste zes rijen.
head(fbschool) Leerling School Klas PPVT Spreken Luisteren SchrijvenLezen Attitude
1 102 S8 8B 78 1 17 14 negatief
2 103 S8 8B 69 2 9 13 positief
3 104 S8 8B 83 12 19 28 positief
4 105 S8 8B 108 13 25 45 positief
5 107 S8 8B 96 15 21 26 positief
6 108 S8 8B 65 8 14 7 positief
Thuistaal Geslacht
1 Nederlands vrouw
2 Nederlands vrouw
3 Nederlands vrouw
4 Nederlands vrouw
5 Nederlands man
6 Meertalig vrouwAls extra check tellen we het aantal leerlingen per school.
fbschool |> count(School) School n
1 S10 19
2 S11 23
3 S12 50
4 S18 18
5 S21 20
6 S24 32
7 S30 16
8 S33 32
9 S34 46
10 S37 17
11 S38 35
12 S42 22
13 S44 19
14 S45 19
15 S46 17
16 S48 17
17 S49 18
18 S51 35
19 S8 34
20 S9 26School S24 heeft \(32\) leerlingen. Dat klopt want die school heeft 2 klassen van elk \(16\) leerlingen.
fbs |> filter(School == "S24") School Klas n
1 S24 24A 16
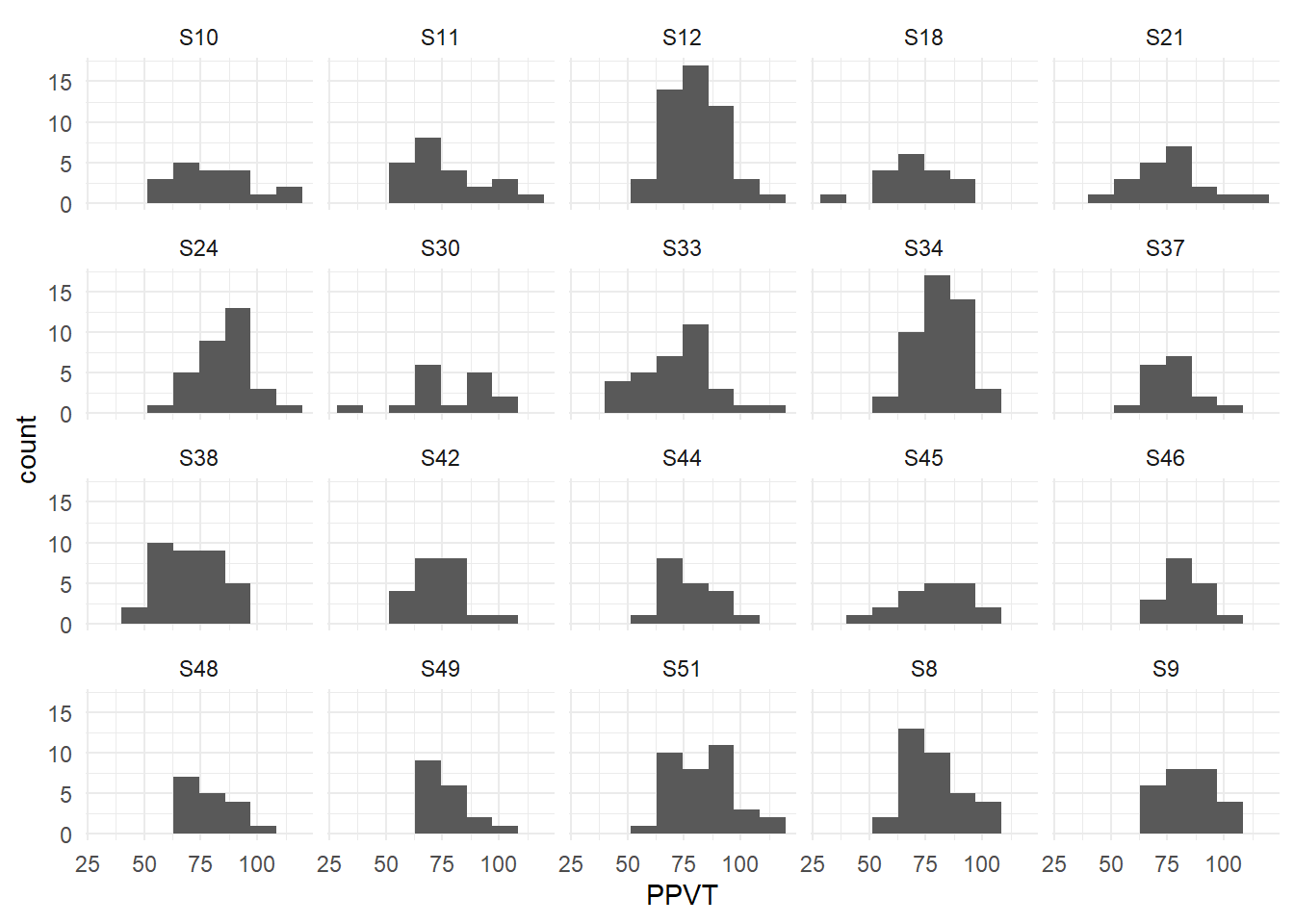
2 S24 24B 16Vervolgens maken we een histogram van PPVT voor elke school, weergegeven in Figure 5.6.
1ggplot(fbschool,
2 aes(x=PPVT)) +
3 geom_histogram(bins = 8) +
4 facet_wrap(School ~ .) +
theme_minimal()- 1
-
Kies
fbschool - 2
-
kies
PPVTals x-as variabele - 3
- visualiseer de waarden als een histogram
- 4
-
deel de figuur op per
School.
5.8 Meerdere boxplots
We keren terug naar de fb-dataset en vergelijken PPVT op basis van Geslacht aan de hand van een geclusterde boxplot. We plaatsen de variabele Geslacht op de x-as zodat er twee verticale boxplots naast elkaar getekend worden. Het resultaat zie je in Figure 5.7.
1ggplot(fb, aes(x = Geslacht,
2 y = PPVT,
3 fill = Geslacht)) +
4 geom_boxplot() +
5 theme_minimal() +
6 theme(legend.position = "none")- 1
-
Kies
fben de waarden voor de x-as - 2
-
PPVTis de variabele op de y-as - 3
-
we voegen een kleurverschil toe voor
Geslacht - 4
- en maken een boxplot
- 5
- een minimalistische opmaak
- 6
- en een legende is overbodig.
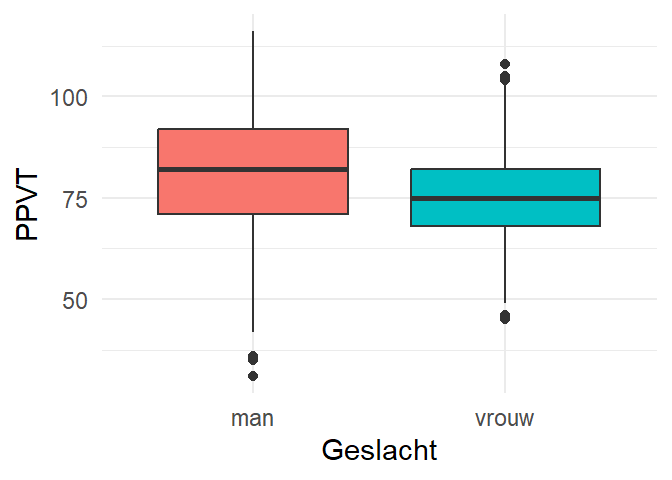
Merk op hoe consequent eerst de waarden voor de x- en y-as gekozen worden via aes, om vervolgens een methode van visualisatie toe te passen.
5.9 Boxplots met een facet
We visualiseren nu de scholen met meer dan \(n=15\) leerlingen per klas aan de hand van boxplots.
1ggplot(fbschool,
2 aes(x=PPVT)) +
3 geom_boxplot() +
4 facet_wrap(School ~ .) +
5 theme_minimal() +
6 theme(axis.text.y = element_blank())- 1
-
Kies
fbschool - 2
-
kies
PPVTals x-as variabele - 3
- visualiseer de waarden als een boxplot
- 4
-
deel de figuur op per
School - 5
- met een minimalistische opmaak
- 6
- zonder waarden op de y-as.
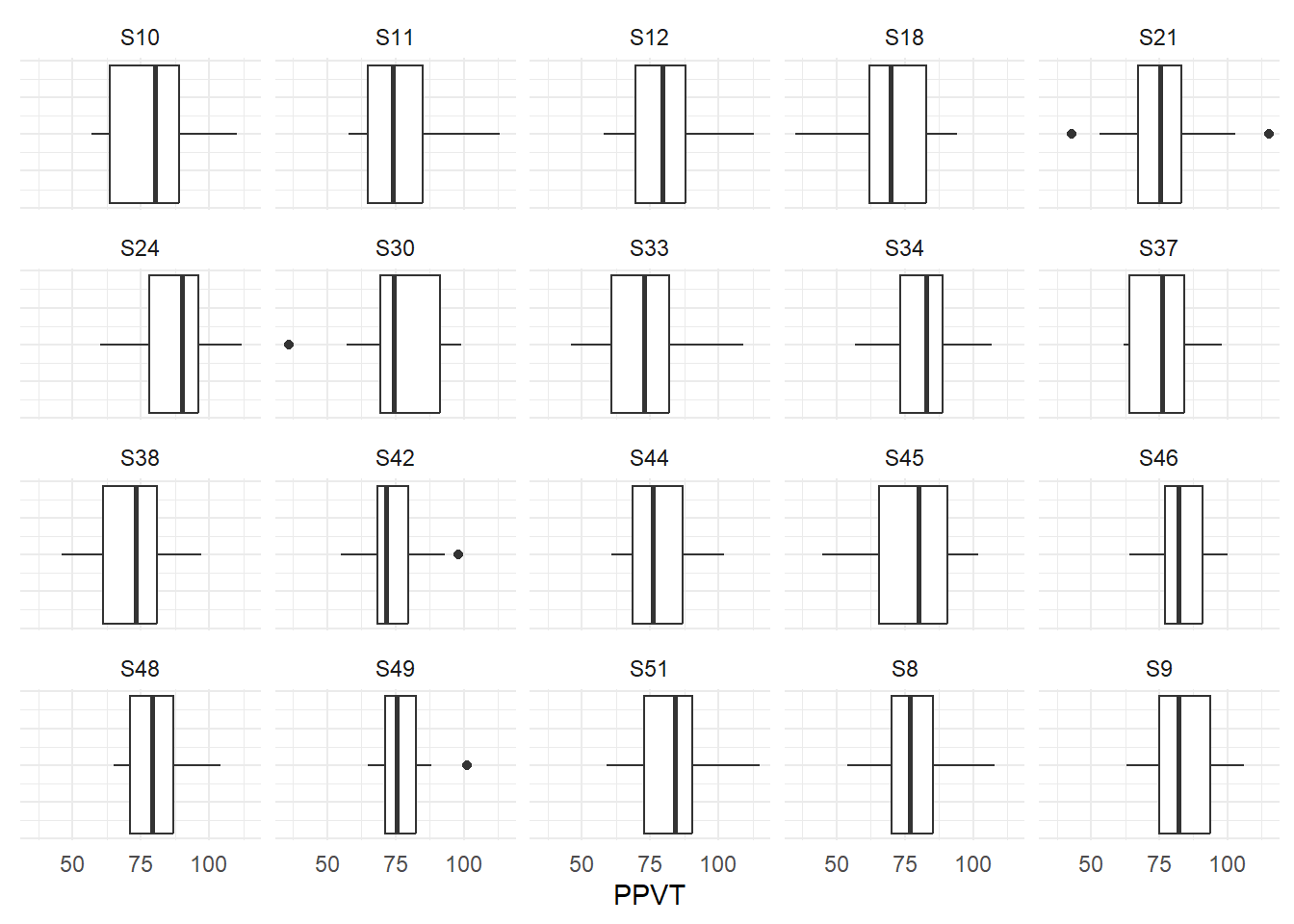
5.10 Geclusterde staafdiagrammen
We gaan na of er een verband is tussen Geslacht en Attitude tegenover Engels. We visualiseren het verband tussen beide binaire categorische variabelen aan de hand van een geclusterde staafdiagram zoals in Figure 5.9. We moeten eerst de frequenties berekenen. We slaan het resultaat op als de dataframe ga. We hebben dit object nodig om te visualiseren.
ga <- fb |> count(Geslacht, Attitude)
ga Geslacht Attitude n
1 man negatief 13
2 man positief 368
3 vrouw negatief 13
4 vrouw positief 352Bekijk opnieuw het verschil met de uitkomst van de table() functie.
table(fb$Geslacht, fb$Attitude)
negatief positief
man 13 368
vrouw 13 3521ggplot(data=ga, aes(x=Geslacht,
2 y=n,
3 fill=Attitude)) +
4 geom_col(position = "dodge") +
theme_minimal()- 1
-
Kies ga, en
Geslachtals x-as variabele - 2
- n als waarden op de y-as
- 3
-
gekleurd volgens
Attitude - 4
- visualiseer met een staafdiagram. Geclusterd, vandaar “dodge”. Ander krijg je een gestapelde versie.
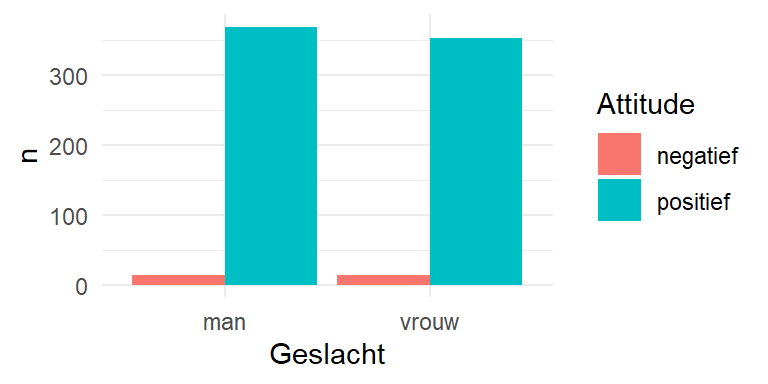
5.11 Scatterplot
We visualiseren de samenhang tussen twee continue variabelen PPVT en Spreken.
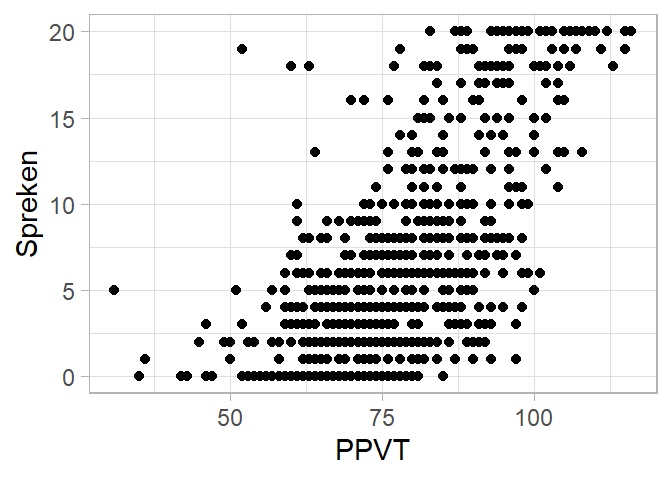
5.12 Drie of meer variabelen
5.12.1 Scatterplot
We bekijken opnieuw de scholen met klassen met meer dan \(15\) leerlingen. We gebruiken hiervoor de fbschool dataframe die we hierboven gemaakt hebben. We onderzoeken het verband tussen de scores voor Spreken en Luisteren aan de hand van een scatterplot. We voegen een lineaire regressielijn toe om het mogelijke lineaire verband weer te geven.
1ggplot(fbschool, aes(x = Spreken, y = Luisteren)) +
2 geom_point() +
3 facet_wrap(School ~ .) +
4 stat_smooth(method = lm, se = FALSE) +
theme_minimal()- 1
-
Kies
fbschool, metSprekenop de x-as enLuisterenop de y-as - 2
- visualiseer aan de hand van een puntenwolk
- 3
-
visualiseer per
School - 4
- voeg een lineaire regressielijn toe.
`geom_smooth()` using formula = 'y ~ x'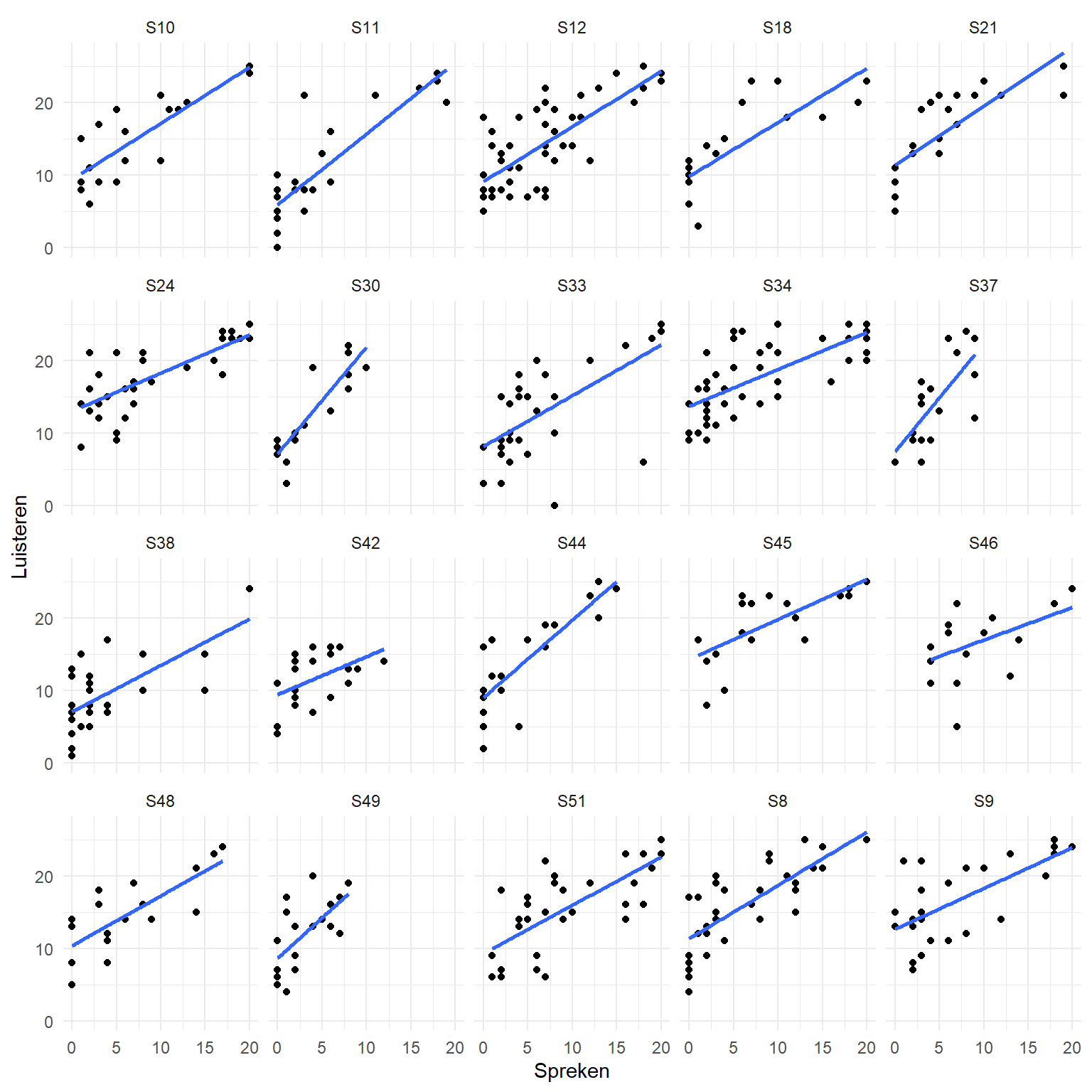
5.12.2 Boxplots
We onderzoeken opnieuw dezelfde fbschool dataset en visualiseren PPVT rekening houdend met Geslacht.
1ggplot(fbschool,
aes(x=Geslacht,
2 y=PPVT,
3 fill = Geslacht)) +
4 geom_boxplot() +
5 facet_wrap(School ~ .) +
theme_minimal() +
theme(legend.position = "none") - 1
-
Kies
fbschool - 2
-
kies
PPVTals x-as variabele - 3
-
voeg een kleur toe op basis van
Geslacht - 4
- visualiseer de waarden als een boxplot
- 5
-
deel de figuur op per
School.
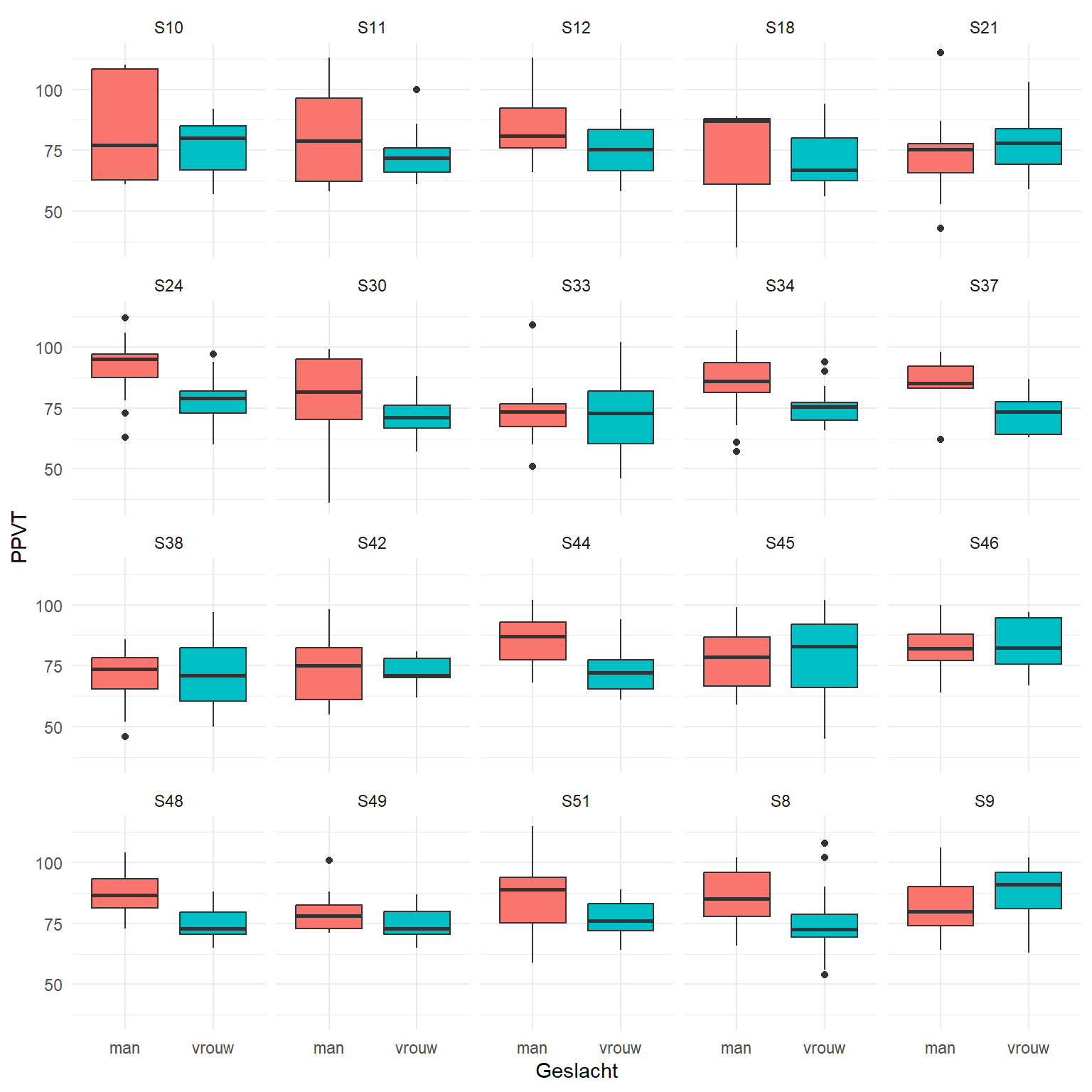
Jongens scoorden in de meeste klassen hoger voor PPVT dan meisjes.
5.13 Likertschalen visualiseren
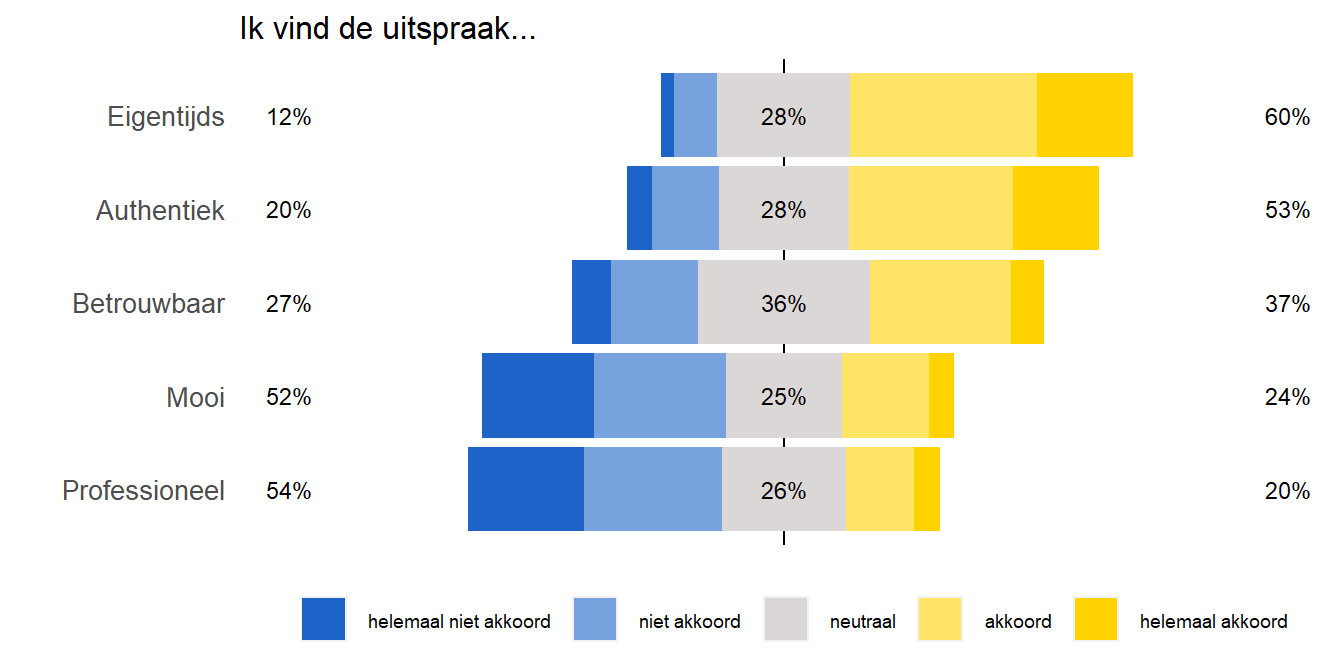
De Likertschaal is een populaire meetschaal om attitudes, percepties en meningen te meten. Met het likert package (Bryer and Speerschneider 2016) kunnen meerdere likertschalen op een efficiënte manier in één figuur weergeven worden. We bekijken de functies aan de hand van de influencer dataset.1 Deze dataset bevat \(N = 1249\) observaties op basis van een “matched guise experiment”. De participanten werd gevraagd om naar verschillende sprekers te luisteren die dezelfde tekst met een ander accent inspraken. In feite ging het om dezelfde spreker die verschillende accenten nabootste. Vervolgens werd aan de participanten gevraagd om de taal van de spreker te beoordelen op basis van verschillende kwaliteiten. Er werd onder meer gevraagd: “klinkt deze spreker voor jou …”
- Eigentijds
- Professioneel
- Mooi
- Authentiek
- Betrouwbaar
De participanten gaven een beoordeling op een 5-punt-likertschaal, van \(1 =\) “helemaal niet akkoord” tot \(5 =\) “helemaal akkoord”. De dataset bevat negen variabelen:
| ID | Variabele | Toelichting |
|---|---|---|
| 1 | ID | een uniek nummer voor elke observatie |
| 2 | Spreker | een code voor de spreker (A, B, C, en D) |
| 3 | AccentSpreker | het accent van de spreker (“Brabants” vs. “West-Vlaams”) |
| 4 | Participant | een uniek nummer voor elke participant |
| 5 | Eigentijds | beoordeling op een 5-punt likertschaal |
| 6 | Professioneel | beoordeling op een 5-punt likertschaal |
| 7 | Mooi | beoordeling op een 5-punt likertschaal |
| 8 | Authentiek | beoordeling op een 5-punt likertschaal |
| 9 | Betrouwbaar | beoordeling op een 5-punt likertschaal |
Open de dataset en het likert package.
influencer <- read.delim("influencer.txt",
stringsAsFactors=TRUE)
library(likert)De cijfers voor de beoordelingen moeten we eerst een label geven.
1Attitude <- influencer |> select(5:9)
2mylevels<-c("helemaal niet akkoord",
"niet akkoord",
"neutraal",
"akkoord",
"helemaal akkoord")
3Attitude <- data.frame(lapply(Attitude, factor, ordered=TRUE,
levels=1:5,
labels=mylevels))- 1
-
we maken een nieuwe dataframe
Attitudeen kiezen de likertschaalvariabelen die we wensen te visualiseren - 2
- we dienen de cijfers in de dataset een label te geven. Deze stap is niet nodig als de levels al met woorden weergegeven zijn.
- 3
-
de cijfers krijgen een label, via de
lapply()functie. We veranderen elke variabele in de dataframeattitudenaar een geordende factor met 5 levels en met met als labels de levels die we in stap 2 opgegeven hebben.
We kiezen vijf kleuren voor onze visualisatie. Het kleurenpallet is gebaseerd op de UGent-huisstijl.
kleuren<-c("#1E64C8", "#78a2de", "#DBD7D6", "#ffe466", "#FFD200")We maken een likert-object L1. Dit object dient als basis voor de visualisatie. Achter de schermen berekent deze code proporties voor elke beoordeling en voor elke variabele die we hebben opgenomen. Vervolgens plotten we het likertobject (L1).
1L1<-likert(Attitude)
2plot(L1,
3 wrap=50,
4 centered=TRUE,
5 col=kleuren,
6 text.size=3,
7 ordered=TRUE) +
8 theme(strip.text = element_text(size=10),
text = element_text(size = rel(4)),
legend.text = element_text(size = 7),
plot.title = element_text(size = 12),
axis.title.x = element_blank(),
axis.text.x = element_blank(),
panel.background = element_blank()) +
guides(fill=guide_legend("")) +
ggtitle("Ik vind de uitspraak...") - 1
- Maak het likert-object
- 2
-
kies het likertobject om te visualiseren (
L1) - 3
- de breedte van de levels in de plot (vooral handig als er vragen gevisualiseerd worden)
- 4
- de neutrale keuze in het midden
- 5
- de kleuren die we gemaakt hebben
- 6
- tekstgrootte labels
- 7
- geordend volgens percentages (helemaal) akkoord
- 8
- verschillende esthetische aspecten.
We voegen vervolgens het accent van de spreker als groeperende variabele toe zodat we de beoordelingen voor de twee accenten gemakkelijk kunnen vergelijken.
L2<-likert(Attitude, grouping = influencer$AccentSpreker)
plot(L2,
wrap=50,
centered=TRUE,
col=kleuren,
text.size=3,
ordered=TRUE) +
theme(strip.text = element_text(size=10),
text = element_text(size = rel(4)),
legend.text = element_text(size = 7),
plot.title = element_text(size = 12),
axis.title.x = element_blank(),
axis.text.x = element_blank(),
panel.background = element_blank()) +
guides(fill=guide_legend("")) +
ggtitle("Ik vind de uitspraak...")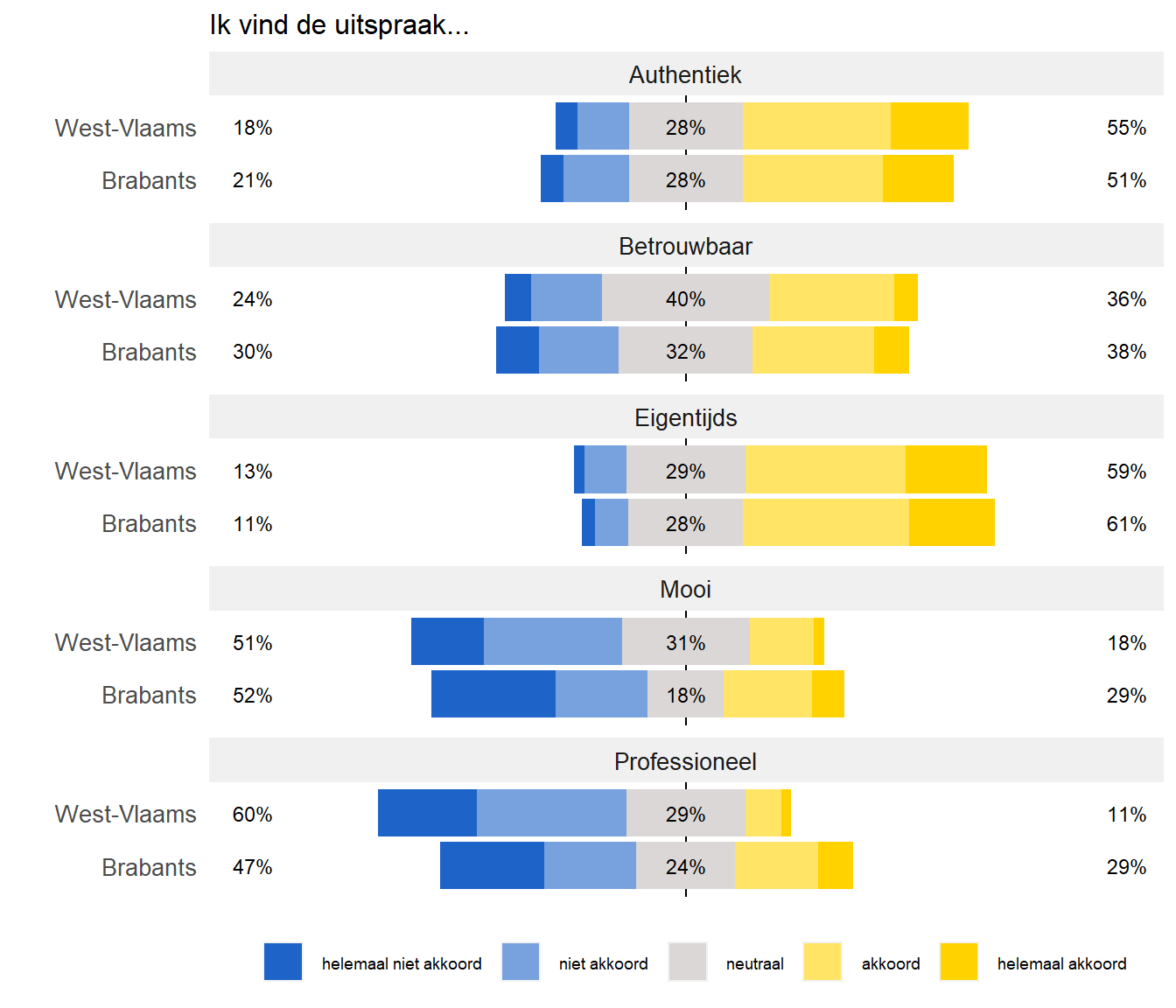
5.14 Formanten visualiseren
Sönning (2021) bevat een dataset met de eerste en tweede formant voor de TRAP en DRESS vocalen die gerealiseerd werden door Engelse moedertaalsprekers (zowel Amerikaans als Brits Engels). We laden de dataset en inspecteren de variabelen.
trap <- read.csv("trap_data_ns.csv", sep=";", stringsAsFactors=TRUE)
str(trap)'data.frame': 286 obs. of 15 variables:
$ subject: Factor w/ 26 levels "NS01","NS02",..: 1 1 1 1 1 1 1 1 1 1 ...
$ vowel : Factor w/ 2 levels "{","e": 2 2 2 2 2 2 1 1 1 1 ...
$ word : Factor w/ 11 levels "bad","bed","cat",..: 7 2 4 11 9 8 1 5 3 10 ...
$ dur : int 154 170 154 104 60 99 272 232 128 140 ...
$ voicing: Factor w/ 2 levels "v","vl": 1 1 2 2 2 2 1 1 2 2 ...
$ variety: Factor w/ 2 levels "AmE","BrE": 2 2 2 2 2 2 2 2 2 2 ...
$ age : int 21 21 21 21 21 21 21 21 21 21 ...
$ gender : Factor w/ 2 levels "f","m": 1 1 1 1 1 1 1 1 1 1 ...
$ F1 : int 678 672 730 679 780 713 764 747 802 731 ...
$ F2 : int 1738 1694 1688 1794 1722 1453 1392 1543 1692 1428 ...
$ F1Bk : num 6.36 6.32 6.75 6.37 7.1 ...
$ F2Bk : num 12.1 11.9 11.9 12.3 12 ...
$ F1zBk : num 0.777 0.737 1.121 0.784 1.439 ...
$ F2zBk : num 0.551 0.472 0.461 0.649 0.522 0.002 -0.128 0.185 0.468 -0.051 ...
$ log_dur: num 5.04 5.14 5.04 4.64 4.09 ...Op basis van het codeboek weten we dat de vocalen symbolisch worden weergegeven: “{” staat voor TRAP, “e” voor DRESS. We passen dit aan in de dataset om een mooiere visualisatie te kunnen maken.
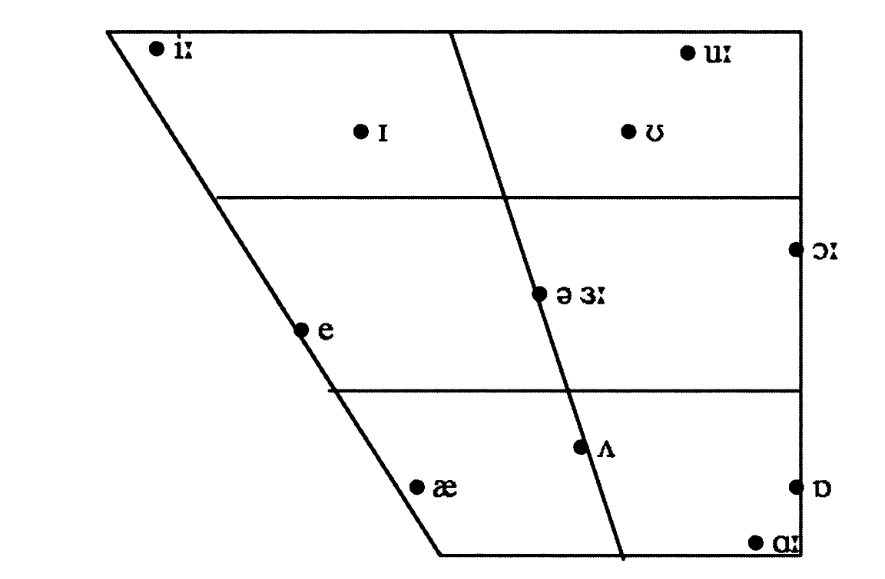
levels(trap$vowel) <- c("TRAP", "DRESS")We wensen de formanten voor beide vocalen (F1 en F2) te visualiseren. De vocalen werden geproduceerd door moedertaalsprekers en dus verwachten we dat DRESS hoger en meer vooraan zal worden gerealiseerd dan TRAP zoals geïllusteerd in Figure 5.15 (bron: (Roach 2004)).
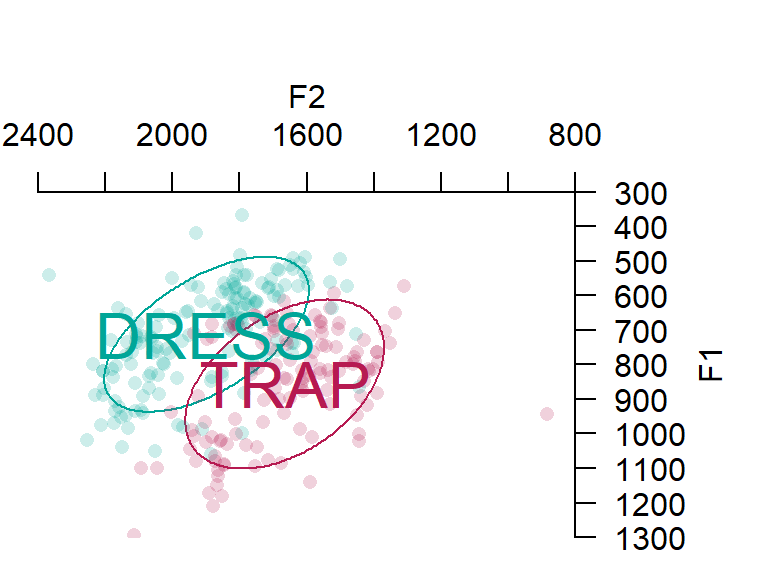
Om formanten in een soort scatterplot te visualiseren gebruiken we de plotVowels() functie. We voegen daarbij de bivariate gemiddelden toe zodat we die kunnen vergelijken met Figure 5.15. Het phonR package (McCloy 2016) werd hier speciaal voor ontwikkeld.
- We kiezen trap als dataset. Door
with()te gebruiken vermijden we in base-R het dollarteken. - kies de eerste en tweede formant in de dataset
- kies de
vowelvariabele om te visualiseren - de tokens zijn de punten op basis van
F1enF2 - we plotten de bivariate gemiddelden
alphazorgt voor doorzichtigheid (kies een waarde tussen 0 en 1)- de gemiddelden worden weergegeven als de level namen (TRAP en DRESS)
- de grootte van de gemiddelden
- kleur per vocaal
- voeg een ellips toe rond de formanten van beide vocalen
- zorg voor een mooie plot
Uit de visualisatie van de formanten blijkt inderdaad dat DRESS hoger en meer vooraan werd gerealiseerd dan TRAP.
5.15 Samenvatting en vooruitblik
We hebben gezien dat we aan de hand van het ggplot2 package op vrij eenvoudige wijze schitterende visualisaties kunnen maken. Het moeilijkste aspect bij een datavisualisatie is meestal niet zozeer de visualisatie zelf, maar veeleer de voorafgaande “data wrangling”, het transformeren, filteren, hercoderen en selecteren van de data tot het juiste dataformaat gebruikt kan worden voor verdere visualisatie. Omdat ggplot2 deel uitmaakt van de tidyverse is de code vrij consistent. Dat betekent niet dat base-R plots overbodig worden. In feite kun je ook met base-R prachtige visualisatie maken, maar de codering is vaak ingewikkelder.
5.16 Verdere studie
5.16.1 Online bronnen voor R
Enkele uitstekende bronnen om verder aan de slag te gaan met datavisualisatie in R, vind je gemakkelijk online:
- Het boek dat altijd binnen mijn handbereik ligt: https://r-graphics.org/
- Ter inspiratie: https://r-graph-gallery.com/
- En natuurlijk de Positwebsite zelf: https://ggplot2.tidyverse.org/index.html
5.16.2 Experten in datavisualisatie
Datavisualisatie is een kunst en een kunde. Bekende namen zijn:
- Nathan Yau: https://flowingdata.com/
- Edward Tufte https://www.edwardtufte.com/tufte/
- Cole Nussbaumer Knaflic: https://www.storytellingwithdata.com/
De influencer dataset bevat een selectie van de dataset die werd geproduceerd door Flore Lombaert in het kader van haar masterproef (Lombaert 2021)↩︎